 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLowering the Barrier to IREX Participation: Open-Source Algorithms, Toolkit, and Benchmarking for Iris Recognition
May 20, 2026This paper proposes two new open-source iris recognition algorithms, providing both Python and IREX-compliant C++ implementations to be submitted to the official IREX X program. This work has two primary goals: (a) to conduct the first-ever assessment of open-source iris recognition solutions according to IREX testing protocols, and (b) to offer a model C++ submission that significantly facilitates the entry of other teams' open-source methods into the IREX evaluation. The new methods consist of two Neural Networks trained with: (i) Triplet loss with Batch-Hard Triplet mining (TripletIris), and (ii) ArcFace loss (ArcIris). The paper also provides open-source IREX-compliant C++ implementations of two existing methods: (a) an iris image filtering-based algorithm utilizing human saliency-driven kernels (HDBIF), and (b) a human-interpretable algorithm for detecting and comparing Fuchs' crypts (CRYPTS). Except for CRYPTS, which faced timing constraints during 1:N search, these methods have undergone the official IREX X evaluation and have also been assessed using several popular academic benchmarks: Quality-Face/Iris Research Ensemble, Warsaw-Biobase Post-Mortem Iris, CASIA-Iris-Thousand-V4, CASIA-Iris-Lamp-V4, IIT Delhi Iris Database, IIITD Contact Lens Iris Database, NDIris3D, and Notre Dame Variable Iris Image Quality Release 2. Finally, this paper also provides open-source models for iris segmentation and circle estimation that can be incorporated into any new iris recognition method.
Beyond Mortality: Advancements in Post-Mortem Iris Recognition through Data Collection and Computer-Aided Forensic Examination
Mar 27, 2026Post-mortem iris recognition brings both hope to the forensic community (a short-term but accurate and fast means of verifying identity) as well as concerns to society (its potential illicit use in post-mortem impersonation). These hopes and concerns have grown along with the volume of research in post-mortem iris recognition. Barriers to further progress in post-mortem iris recognition include the difficult nature of data collection, and the resulting small number of approaches designed specifically for comparing iris images of deceased subjects. This paper makes several unique contributions to mitigate these barriers. First, we have collected and we offer a new dataset of NIR (compliant with ISO/IEC 19794-6 where possible) and visible-light iris images collected after demise from 259 subjects, with the largest PMI (post-mortem interval) being 1,674 hours. For one subject, the data has been collected before and after death, the first such case ever published. Second, the collected dataset was combined with publicly-available post-mortem samples to assess the current state of the art in automatic forensic iris recognition with five iris recognition methods and data originating from 338 deceased subjects. These experiments include analyses of how selected demographic factors influence recognition performance. Thirdly, this study implements a model for detecting post-mortem iris images, which can be considered as presentation attacks. Finally, we offer an open-source forensic tool integrating three post-mortem iris recognition methods with explainability elements added to make the comparison process more human-interpretable.
VISER: Visually-Informed System for Enhanced Robustness in Open-Set Iris Presentation Attack Detection
Mar 18, 2026Human perceptual priors have shown promise in saliency-guided deep learning training, particularly in the domain of iris presentation attack detection (PAD). Common saliency approaches include hand annotations obtained via mouse clicks and eye gaze heatmaps derived from eye tracking data. However, the most effective form of human saliency for open-set iris PAD remains underexplored. In this paper, we conduct a series of experiments comparing hand annotations, eye tracking heatmaps, segmentation masks, and DINOv2 embeddings to a state-of-the-art deep learning-based baseline on the task of open-set iris PAD. Results for open-set PAD in a leave-one-attack-type out paradigm indicate that denoised eye tracking heatmaps show the best generalization improvement over cross entropy in terms of Area Under the ROC curve (AUROC) and Attack Presentation Classification Error Rate (APCER) at Bona Fide Presentation Classification Error Rate (BPCER) of 1%. Along with this paper, we offer trained models, code, and saliency maps for reproducibility and to facilitate follow-up research efforts.
Generalist Multimodal LLMs Gain Biometric Expertise via Human Salience
Mar 17, 2026Iris presentation attack detection (PAD) is critical for secure biometric deployments, yet developing specialized models faces significant practical barriers: collecting data representing future unknown attacks is impossible, and collecting diverse-enough data, yet still limited in terms of its predictive power, is expensive. Additionally, sharing biometric data raises privacy concerns. Due to rapid emergence of new attack vectors demanding adaptable solutions, we thus investigate in this paper whether general-purpose multimodal large language models (MLLMs) can perform iris PAD when augmented with human expert knowledge, operating under strict privacy constraints that prohibit sending biometric data to public cloud MLLM services. Through analysis of vision encoder embeddings applied to our dataset, we demonstrate that pre-trained vision transformers in MLLMs inherently cluster many iris attack types despite never being explicitly trained for this task. However, where clustering shows overlap between attack classes, we find that structured prompts incorporating human salience (verbal descriptions from subjects identifying attack indicators) enable these models to resolve ambiguities. Testing on an IRB-restricted dataset of 224 iris images spanning seven attack types, using only university-approved services (Gemini 2.5 Pro) or locally-hosted models (e.g., Llama 3.2-Vision), we show that Gemini with expert-informed prompts outperforms both a specialized convolutional neural networks (CNN)-based baseline and human examiners, while the locally-deployable Llama achieves near-human performance. Our results establish that MLLMs deployable within institutional privacy constraints offer a viable path for iris PAD.
When Humans Judge Irises: Pupil Size Normalization as an Aid and Synthetic Irises as a Challenge
Jan 11, 2026Iris recognition is a mature biometric technology offering remarkable precision and speed, and allowing for large-scale deployments to populations exceeding a billion enrolled users (e.g., AADHAAR in India). However, in forensic applications, a human expert may be needed to review and confirm a positive identification before an iris matching result can be presented as evidence in court, especially in cases where processed samples are degraded (e.g., in post-mortem cases) or where there is a need to judge whether the sample is authentic, rather than a result of a presentation attack. This paper presents a study that examines human performance in iris verification in two controlled scenarios: (a) under varying pupil sizes, with and without a linear/nonlinear alignment of the pupil size between compared images, and (b) when both genuine and impostor iris image pairs are synthetically generated. The results demonstrate that pupil size normalization carried out by a modern autoencoder-based identity-preserving image-to-image translation model significantly improves verification accuracy. Participants were also able to determine whether iris pairs corresponded to the same or different eyes when both images were either authentic or synthetic. However, accuracy declined when subjects were comparing authentic irises against high-quality, same-eye synthetic counterparts. These findings (a) demonstrate the importance of pupil-size alignment for iris matching tasks in which humans are involved, and (b) indicate that despite the high fidelity of modern generative models, same-eye synthetic iris images are more often judged by humans as different-eye images, compared to same-eye authentic image pairs. We offer data and human judgments along with this paper to allow full replicability of this study and future works.
SAGE: Saliency-Guided Contrastive Embeddings
Nov 16, 2025Integrating human perceptual priors into the training of neural networks has been shown to raise model generalization, serve as an effective regularizer, and align models with human expertise for applications in high-risk domains. Existing approaches to integrate saliency into model training often rely on internal model mechanisms, which recent research suggests may be unreliable. Our insight is that many challenges associated with saliency-guided training stem from the placement of the guidance approaches solely within the image space. Instead, we move away from the image space, use the model's latent space embeddings to steer human guidance during training, and we propose SAGE (Saliency-Guided Contrastive Embeddings): a loss function that integrates human saliency into network training using contrastive embeddings. We apply salient-preserving and saliency-degrading signal augmentations to the input and capture the changes in embeddings and model logits. We guide the model towards salient features and away from non-salient features using a contrastive triplet loss. Additionally, we perform a sanity check on the logit distributions to ensure that the model outputs match the saliency-based augmentations. We demonstrate a boost in classification performance across both open- and closed-set scenarios against SOTA saliency-based methods, showing SAGE's effectiveness across various backbones, and include experiments to suggest its wide generalization across tasks.
Gradient-Guided Exploration of Generative Model's Latent Space for Controlled Iris Image Augmentations
Nov 12, 2025Developing reliable iris recognition and presentation attack detection methods requires diverse datasets that capture realistic variations in iris features and a wide spectrum of anomalies. Because of the rich texture of iris images, which spans a wide range of spatial frequencies, synthesizing same-identity iris images while controlling specific attributes remains challenging. In this work, we introduce a new iris image augmentation strategy by traversing a generative model's latent space toward latent codes that represent same-identity samples but with some desired iris image properties manipulated. The latent space traversal is guided by a gradient of specific geometrical, textural, or quality-related iris image features (e.g., sharpness, pupil size, iris size, or pupil-to-iris ratio) and preserves the identity represented by the image being manipulated. The proposed approach can be easily extended to manipulate any attribute for which a differentiable loss term can be formulated. Additionally, our approach can use either randomly generated images using either a pre-train GAN model or real-world iris images. We can utilize GAN inversion to project any given iris image into the latent space and obtain its corresponding latent code.
Divisive Decisions: Improving Salience-Based Training for Generalization in Binary Classification Tasks
Jul 22, 2025Existing saliency-guided training approaches improve model generalization by incorporating a loss term that compares the model's class activation map (CAM) for a sample's true-class ({\it i.e.}, correct-label class) against a human reference saliency map. However, prior work has ignored the false-class CAM(s), that is the model's saliency obtained for incorrect-label class. We hypothesize that in binary tasks the true and false CAMs should diverge on the important classification features identified by humans (and reflected in human saliency maps). We use this hypothesis to motivate three new saliency-guided training methods incorporating both true- and false-class model's CAM into the training strategy and a novel post-hoc tool for identifying important features. We evaluate all introduced methods on several diverse binary close-set and open-set classification tasks, including synthetic face detection, biometric presentation attack detection, and classification of anomalies in chest X-ray scans, and find that the proposed methods improve generalization capabilities of deep learning models over traditional (true-class CAM only) saliency-guided training approaches. We offer source codes and model weights\footnote{GitHub repository link removed to preserve anonymity} to support reproducible research.
Saliency-Guided Training for Fingerprint Presentation Attack Detection
May 04, 2025
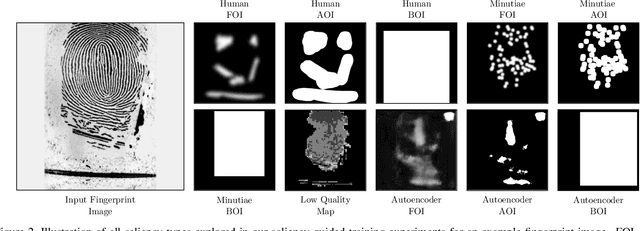


Saliency-guided training, which directs model learning to important regions of images, has demonstrated generalization improvements across various biometric presentation attack detection (PAD) tasks. This paper presents its first application to fingerprint PAD. We conducted a 50-participant study to create a dataset of 800 human-annotated fingerprint perceptually-important maps, explored alongside algorithmically-generated "pseudosaliency," including minutiae-based, image quality-based, and autoencoder-based saliency maps. Evaluating on the 2021 Fingerprint Liveness Detection Competition testing set, we explore various configurations within five distinct training scenarios to assess the impact of saliency-guided training on accuracy and generalization. Our findings demonstrate the effectiveness of saliency-guided training for fingerprint PAD in both limited and large data contexts, and we present a configuration capable of earning the first place on the LivDet-2021 benchmark. Our results highlight saliency-guided training's promise for increased model generalization capabilities, its effectiveness when data is limited, and its potential to scale to larger datasets in fingerprint PAD. All collected saliency data and trained models are released with the paper to support reproducible research.
Almost Right: Making First-layer Kernels Nearly Orthogonal Improves Model Generalization
Apr 23, 2025An ongoing research challenge within several domains in computer vision is how to increase model generalization capabilities. Several attempts to improve model generalization performance are heavily inspired by human perceptual intelligence, which is remarkable in both its performance and efficiency to generalize to unknown samples. Many of these methods attempt to force portions of the network to be orthogonal, following some observation within neuroscience related to early vision processes. In this paper, we propose a loss component that regularizes the filtering kernels in the first convolutional layer of a network to make them nearly orthogonal. Deviating from previous works, we give the network flexibility in which pairs of kernels it makes orthogonal, allowing the network to navigate to a better solution space, imposing harsh penalties. Without architectural modifications, we report substantial gains in generalization performance using the proposed loss against previous works (including orthogonalization- and saliency-based regularization methods) across three different architectures (ResNet-50, DenseNet-121, ViT-b-16) and two difficult open-set recognition tasks: presentation attack detection in iris biometrics, and anomaly detection in chest X-ray images.