 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Loosely Coupled Odometry, UWB Ranging, and Cooperative Spatial Detection for Relative Monte-Carlo Multi-Robot Localization
Apr 13, 2023
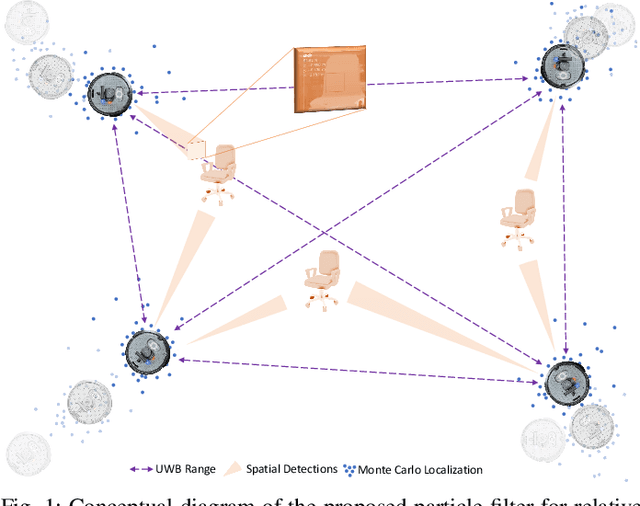
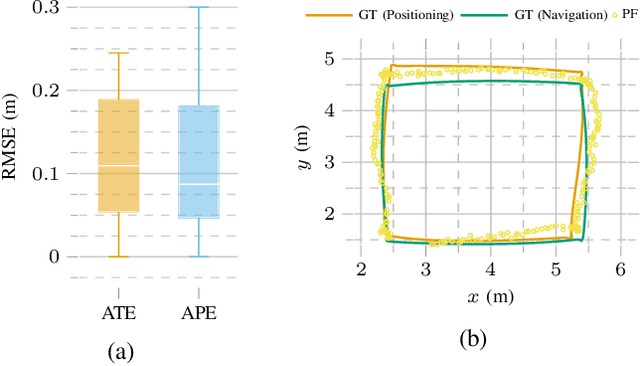
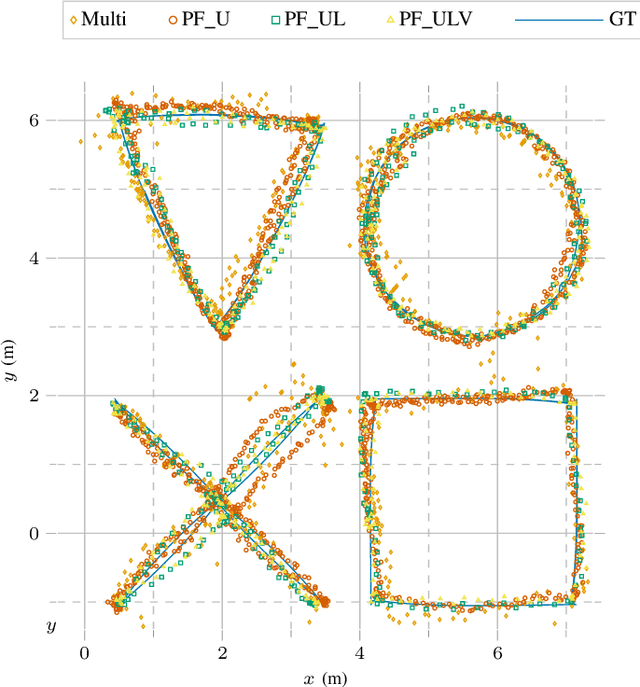
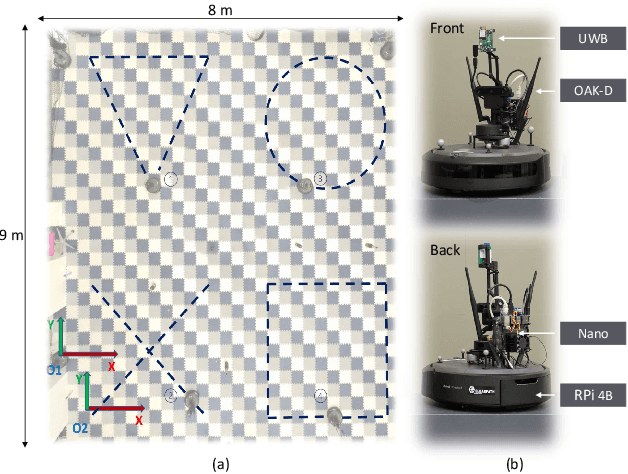
As mobile robots become more ubiquitous, their deployments grow across use cases where GNSS positioning is either unavailable or unreliable. This has led to increased interest in multi-modal relative localization methods. Complementing onboard odometry, ranging allows for relative state estimation, with ultra-wideband (UWB) ranging having gained widespread recognition due to its low cost and centimeter-level out-of-box accuracy. Infrastructure-free localization methods allow for more dynamic, ad-hoc, and flexible deployments, yet they have received less attention from the research community. In this work, we propose a cooperative relative multi-robot localization where we leverage inter-robot ranging and simultaneous spatial detections of objects in the environment. To achieve this, we equip robots with a single UWB transceiver and a stereo camera. We propose a novel Monte-Carlo approach to estimate relative states by either employing only UWB ranges or dynamically integrating simultaneous spatial detections from the stereo cameras. We also address the challenges for UWB ranging error mitigation, especially in non-line-of-sight, with a study on different LSTM networks to estimate the ranging error. The proposed approach has multiple benefits. First, we show that a single range is enough to estimate the accurate relative states of two robots when fusing odometry measurements. Second, our experiments also demonstrate that our approach surpasses traditional methods such as multilateration in terms of accuracy. Third, to increase accuracy even further, we allow for the integration of cooperative spatial detections. Finally, we show how ROS 2 and Zenoh can be integrated to build a scalable wireless communication solution for multi-robot systems. The experimental validation includes real-time deployment and autonomous navigation based on the relative positioning method.
Signal identification without signal formulation
Apr 13, 2023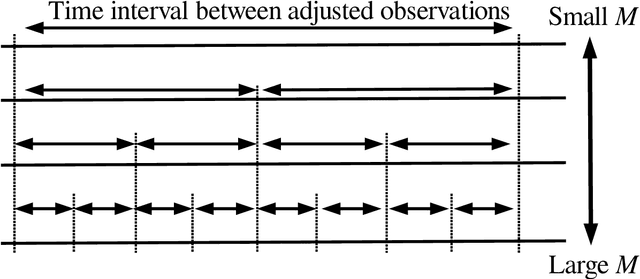
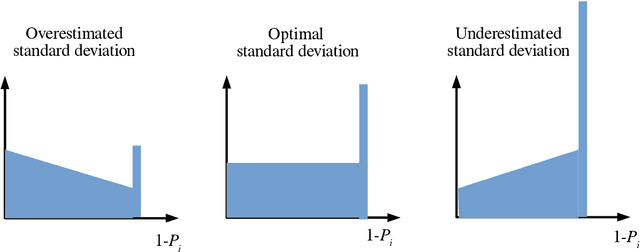
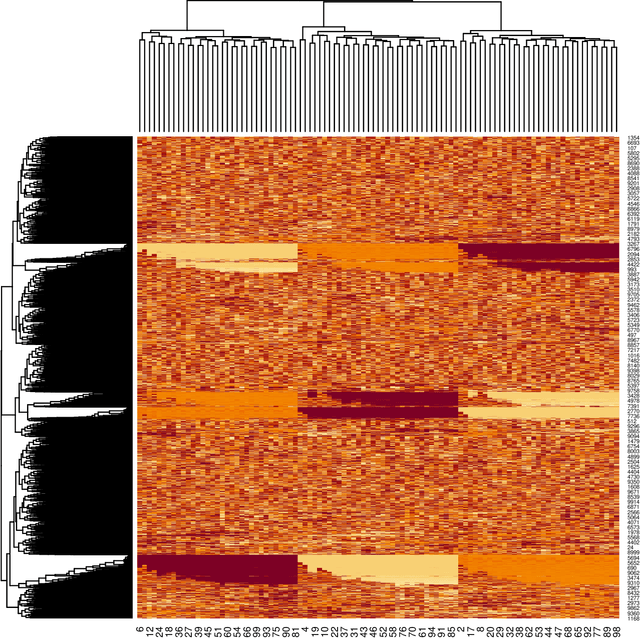
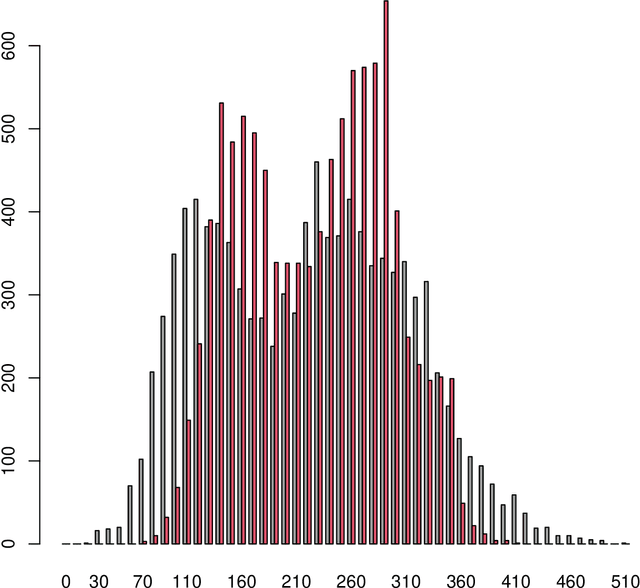
When there are signals and noises, physicists try to identify signals by modeling them, whereas statisticians oppositely try to model noise to identify signals. In this study, we applied the statisticians' concept of signal detection of physics data with small-size samples and high dimensions without modeling the signals. Most of the data in nature, whether noises or signals, are assumed to be generated by dynamical systems; thus, there is essentially no distinction between these generating processes. We propose that the correlation length of a dynamical system and the number of samples are crucial for the practical definition of noise variables among the signal variables generated by such a system. Since variables with short-term correlations reach normal distributions faster as the number of samples decreases, they are regarded to be ``noise-like'' variables, whereas variables with opposite properties are ``signal-like'' variables. Normality tests are not effective for data of small-size samples with high dimensions. Therefore, we modeled noises on the basis of the property of a noise variable, that is, the uniformity of the histogram of the probability that a variable is a noise. We devised a method of detecting signal variables from the structural change of the histogram according to the decrease in the number of samples. We applied our method to the data generated by globally coupled map, which can produce time series data with different correlation lengths, and also applied to gene expression data, which are typical static data of small-size samples with high dimensions, and we successfully detected signal variables from them. Moreover, we verified the assumption that the gene expression data also potentially have a dynamical system as their generation model, and found that the assumption is compatible with the results of signal extraction.
Causal Discovery from Temporal Data: An Overview and New Perspectives
Mar 17, 2023
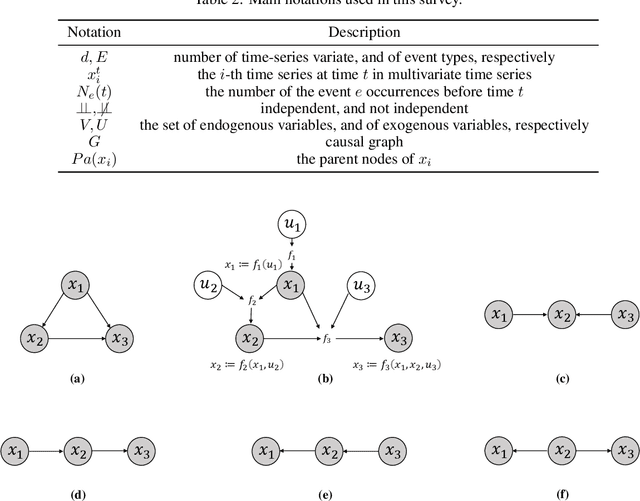
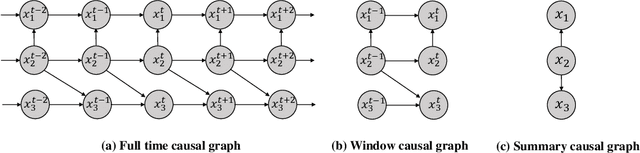
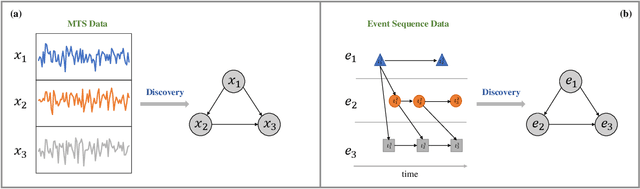
Temporal data, representing chronological observations of complex systems, has always been a typical data structure that can be widely generated by many domains, such as industry, medicine and finance. Analyzing this type of data is extremely valuable for various applications. Thus, different temporal data analysis tasks, eg, classification, clustering and prediction, have been proposed in the past decades. Among them, causal discovery, learning the causal relations from temporal data, is considered an interesting yet critical task and has attracted much research attention. Existing casual discovery works can be divided into two highly correlated categories according to whether the temporal data is calibrated, ie, multivariate time series casual discovery, and event sequence casual discovery. However, most previous surveys are only focused on the time series casual discovery and ignore the second category. In this paper, we specify the correlation between the two categories and provide a systematical overview of existing solutions. Furthermore, we provide public datasets, evaluation metrics and new perspectives for temporal data casual discovery.
Feedback Effect in User Interaction with Intelligent Assistants: Delayed Engagement, Adaption and Drop-out
Mar 17, 2023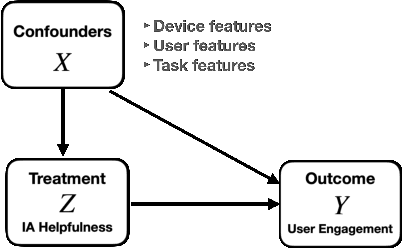

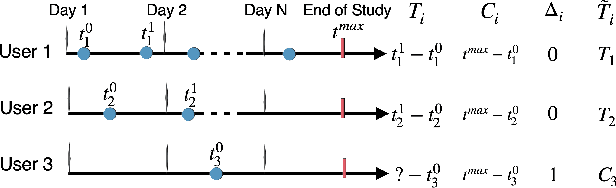
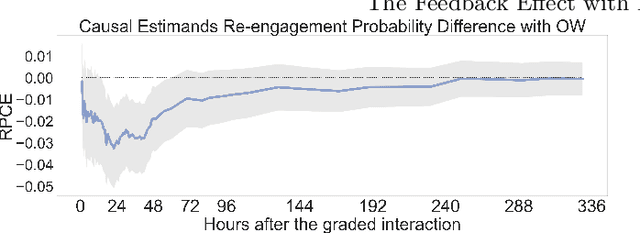
With the growing popularity of intelligent assistants (IAs), evaluating IA quality becomes an increasingly active field of research. This paper identifies and quantifies the feedback effect, a novel component in IA-user interactions: how the capabilities and limitations of the IA influence user behavior over time. First, we demonstrate that unhelpful responses from the IA cause users to delay or reduce subsequent interactions in the short term via an observational study. Next, we expand the time horizon to examine behavior changes and show that as users discover the limitations of the IA's understanding and functional capabilities, they learn to adjust the scope and wording of their requests to increase the likelihood of receiving a helpful response from the IA. Our findings highlight the impact of the feedback effect at both the micro and meso levels. We further discuss its macro-level consequences: unsatisfactory interactions continuously reduce the likelihood and diversity of future user engagements in a feedback loop.
CoVIO: Online Continual Learning for Visual-Inertial Odometry
Mar 17, 2023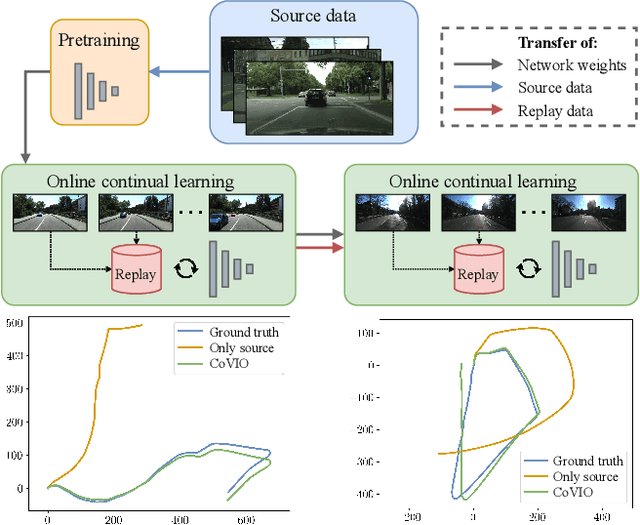
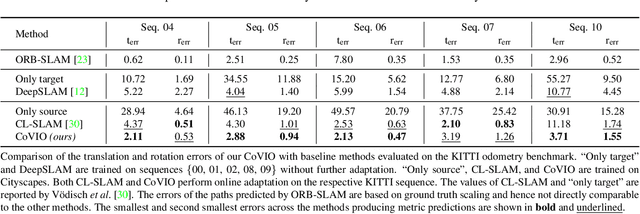
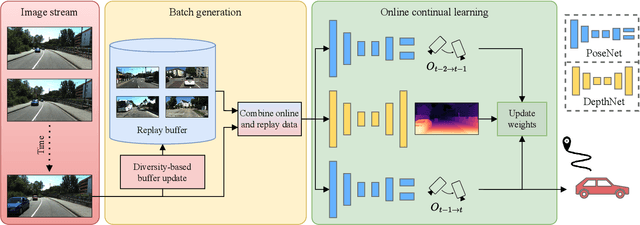
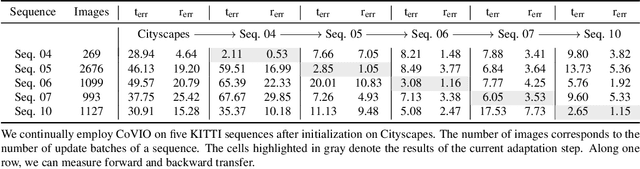
Visual odometry is a fundamental task for many applications on mobile devices and robotic platforms. Since such applications are oftentimes not limited to predefined target domains and learning-based vision systems are known to generalize poorly to unseen environments, methods for continual adaptation during inference time are of significant interest. In this work, we introduce CoVIO for online continual learning of visual-inertial odometry. CoVIO effectively adapts to new domains while mitigating catastrophic forgetting by exploiting experience replay. In particular, we propose a novel sampling strategy to maximize image diversity in a fixed-size replay buffer that targets the limited storage capacity of embedded devices. We further provide an asynchronous version that decouples the odometry estimation from the network weight update step enabling continuous inference in real time. We extensively evaluate CoVIO on various real-world datasets demonstrating that it successfully adapts to new domains while outperforming previous methods. The code of our work is publicly available at http://continual-slam.cs.uni-freiburg.de.
Solar Power Time Series Forecasting Utilising Wavelet Coefficients
Oct 01, 2022

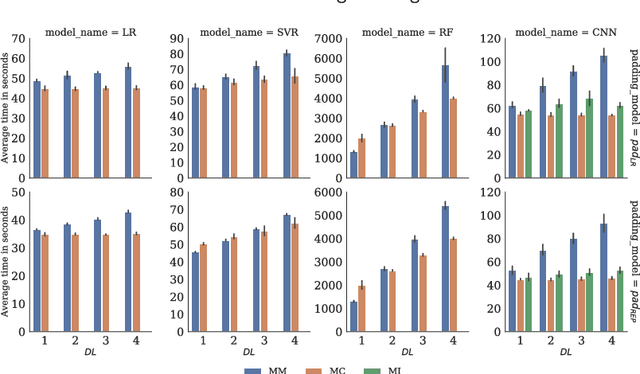
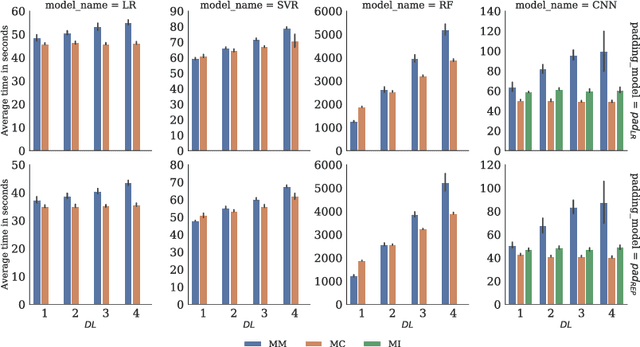
Accurate and reliable prediction of Photovoltaic (PV) power output is critical to electricity grid stability and power dispatching capabilities. However, Photovoltaic (PV) power generation is highly volatile and unstable due to different reasons. The Wavelet Transform (WT) has been utilised in time series applications, such as Photovoltaic (PV) power prediction, to model the stochastic volatility and reduce prediction errors. Yet the existing Wavelet Transform (WT) approach has a limitation in terms of time complexity. It requires reconstructing the decomposed components and modelling them separately and thus needs more time for reconstruction, model configuration and training. The aim of this study is to improve the efficiency of applying Wavelet Transform (WT) by proposing a new method that uses a single simplified model. Given a time series and its Wavelet Transform (WT) coefficients, it trains one model with the coefficients as features and the original time series as labels. This eliminates the need for component reconstruction and training numerous models. This work contributes to the day-ahead aggregated solar Photovoltaic (PV) power time series prediction problem by proposing and comprehensively evaluating a new approach of employing WT. The proposed approach is evaluated using 17 months of aggregated solar Photovoltaic (PV) power data from two real-world datasets. The evaluation includes the use of a variety of prediction models, including Linear Regression, Random Forest, Support Vector Regression, and Convolutional Neural Networks. The results indicate that using a coefficients-based strategy can give predictions that are comparable to those obtained using the components-based approach while requiring fewer models and less computational time.
Neglected Free Lunch; Learning Image Classifiers Using Annotation Byproducts
Apr 04, 2023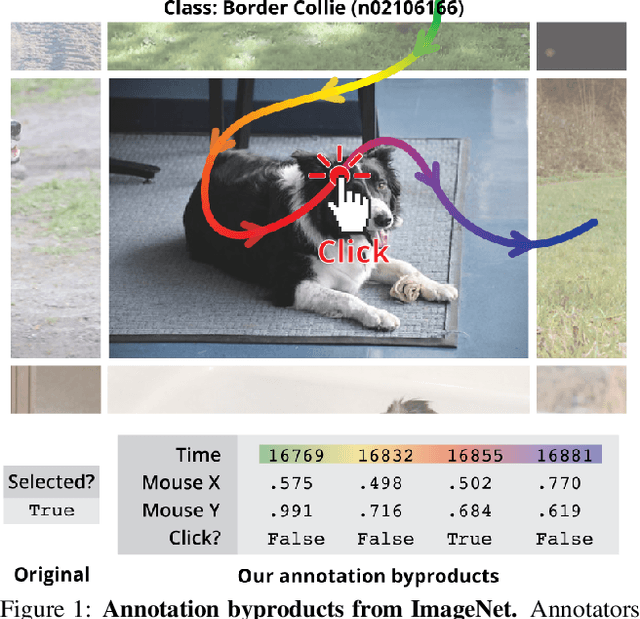
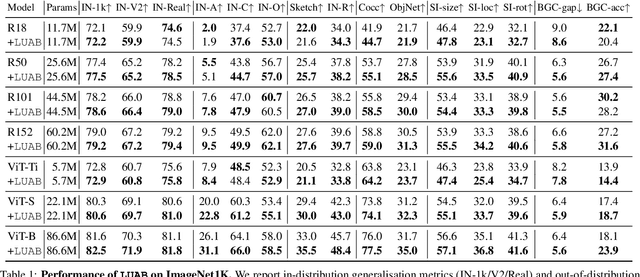
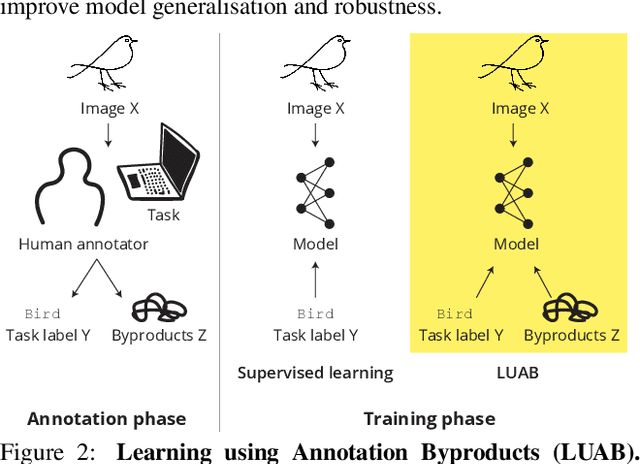
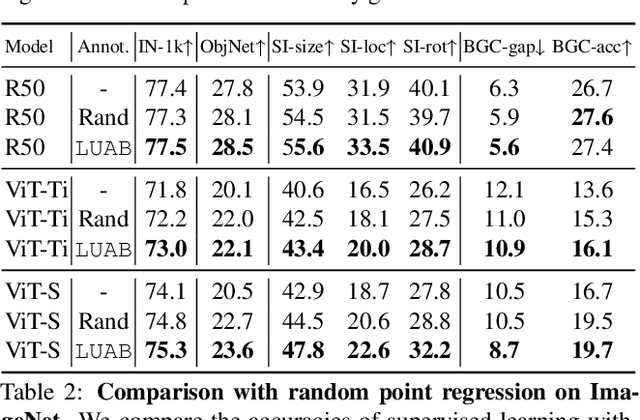
Supervised learning of image classifiers distills human knowledge into a parametric model through pairs of images and corresponding labels (X,Y). We argue that this simple and widely used representation of human knowledge neglects rich auxiliary information from the annotation procedure, such as the time-series of mouse traces and clicks left after image selection. Our insight is that such annotation byproducts Z provide approximate human attention that weakly guides the model to focus on the foreground cues, reducing spurious correlations and discouraging shortcut learning. To verify this, we create ImageNet-AB and COCO-AB. They are ImageNet and COCO training sets enriched with sample-wise annotation byproducts, collected by replicating the respective original annotation tasks. We refer to the new paradigm of training models with annotation byproducts as learning using annotation byproducts (LUAB). We show that a simple multitask loss for regressing Z together with Y already improves the generalisability and robustness of the learned models. Compared to the original supervised learning, LUAB does not require extra annotation costs. ImageNet-AB and COCO-AB are at https://github.com/naver-ai/NeglectedFreeLunch.
OrienterNet: Visual Localization in 2D Public Maps with Neural Matching
Apr 04, 2023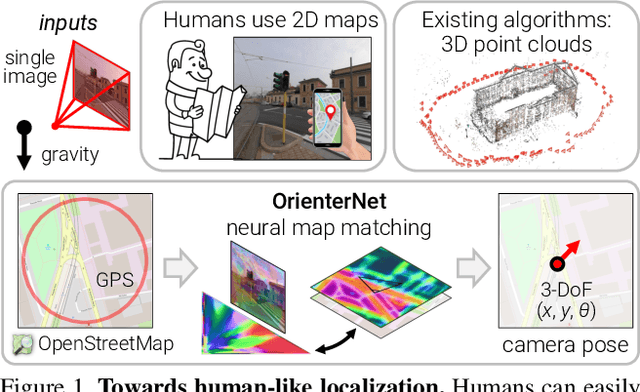
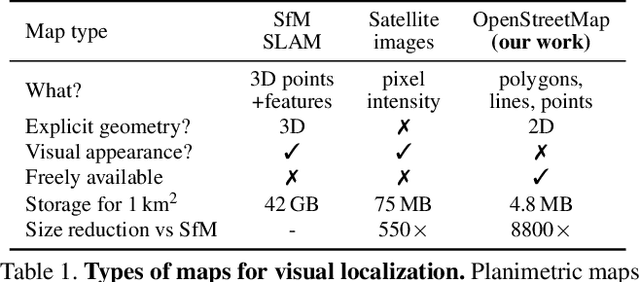
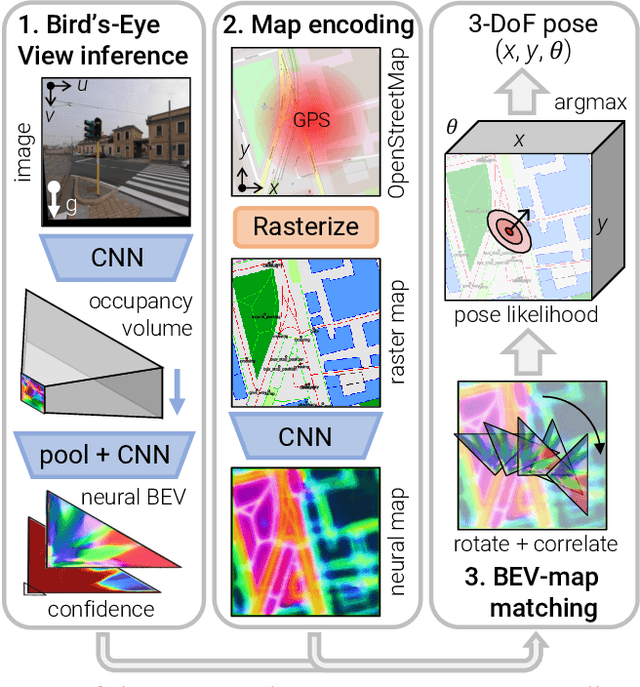
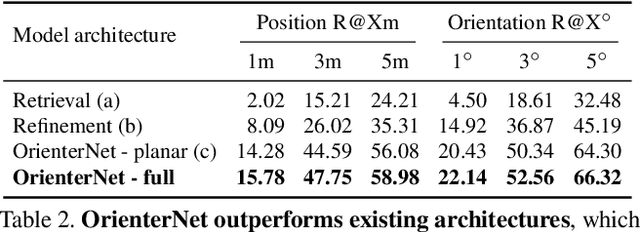
Humans can orient themselves in their 3D environments using simple 2D maps. Differently, algorithms for visual localization mostly rely on complex 3D point clouds that are expensive to build, store, and maintain over time. We bridge this gap by introducing OrienterNet, the first deep neural network that can localize an image with sub-meter accuracy using the same 2D semantic maps that humans use. OrienterNet estimates the location and orientation of a query image by matching a neural Bird's-Eye View with open and globally available maps from OpenStreetMap, enabling anyone to localize anywhere such maps are available. OrienterNet is supervised only by camera poses but learns to perform semantic matching with a wide range of map elements in an end-to-end manner. To enable this, we introduce a large crowd-sourced dataset of images captured across 12 cities from the diverse viewpoints of cars, bikes, and pedestrians. OrienterNet generalizes to new datasets and pushes the state of the art in both robotics and AR scenarios. The code and trained model will be released publicly.
Towards Open-Vocabulary Video Instance Segmentation
Apr 04, 2023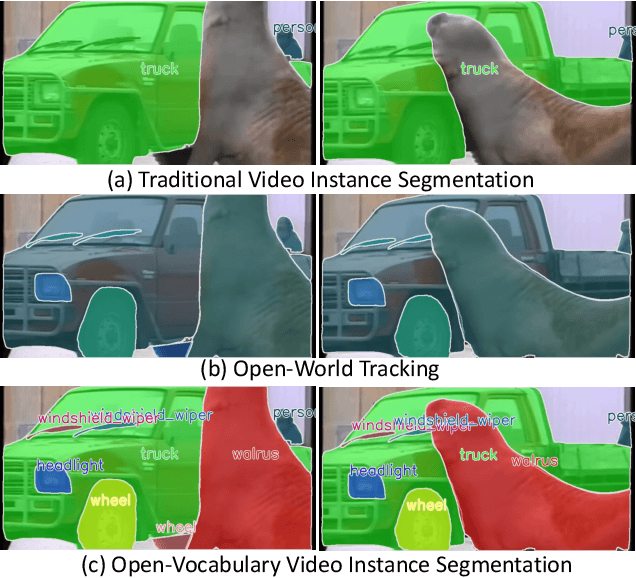
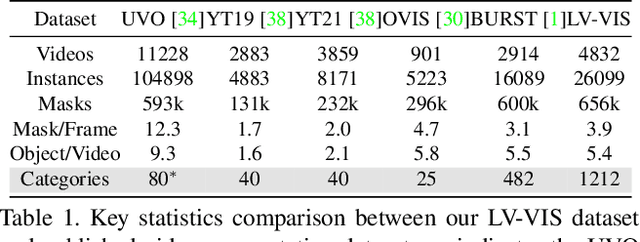
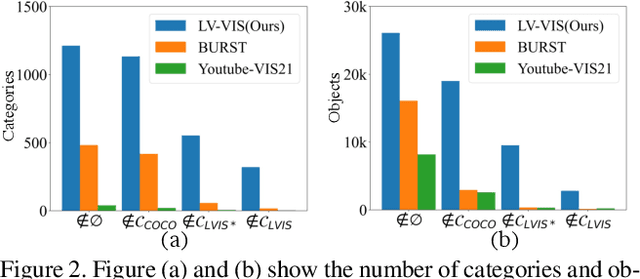
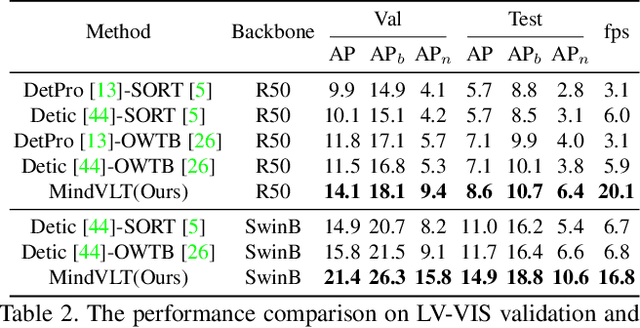
Video Instance Segmentation(VIS) aims at segmenting and categorizing objects in videos from a closed set of training categories, lacking the generalization ability to handle novel categories in real-world videos. To address this limitation, we make the following three contributions. First, we introduce the novel task of Open-Vocabulary Video Instance Segmentation, which aims to simultaneously segment, track, and classify objects in videos from open-set categories, including novel categories unseen during training. Second, to benchmark Open-Vocabulary VIS, we collect a Large-Vocabulary Video Instance Segmentation dataset(LV-VIS), that contains well-annotated objects from 1,212 diverse categories, significantly surpassing the category size of existing datasets by more than one order of magnitude. Third, we propose an efficient Memory-Induced Vision-Language Transformer, MindVLT, to first achieve Open-Vocabulary VIS in an end-to-end manner with near real-time inference speed. Extensive experiments on LV-VIS and four existing VIS datasets demonstrate the strong zero-shot generalization ability of MindVLT on novel categories. We will release the dataset and code to facilitate future endeavors.
Performance Analysis of ML-based MTC Traffic Pattern Predictors
Apr 04, 2023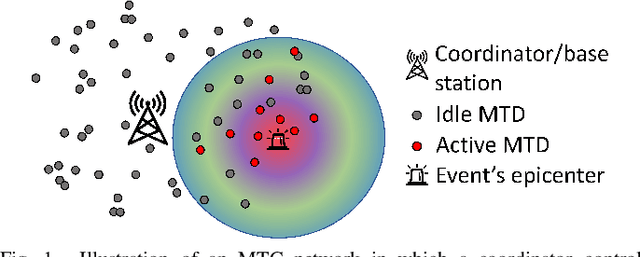
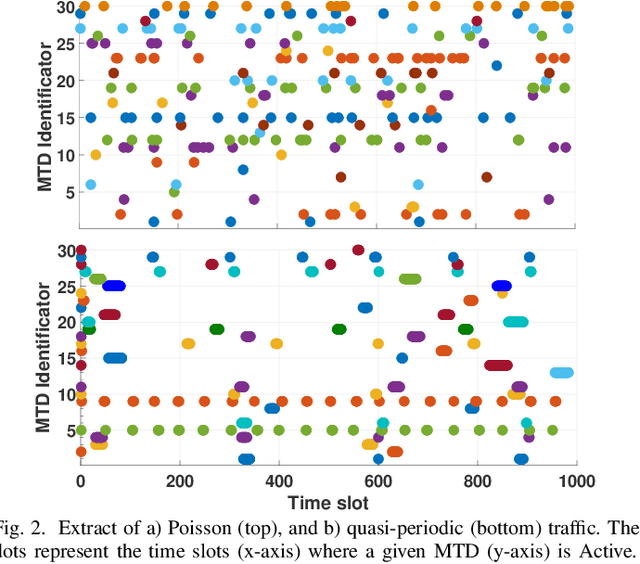
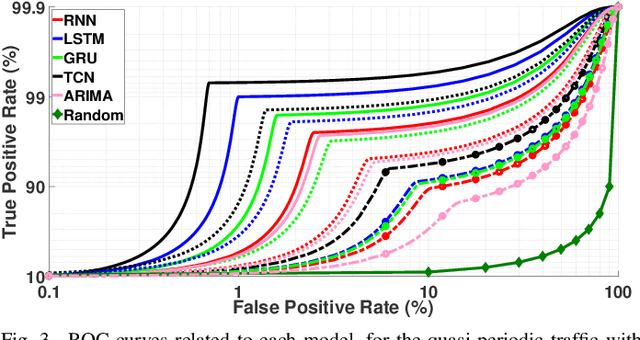
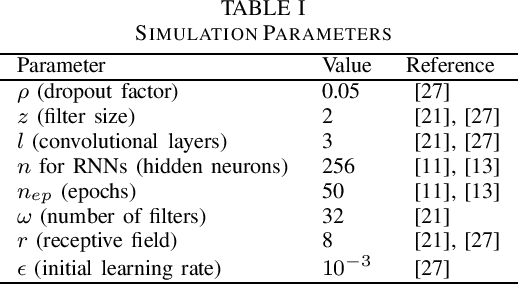
Prolonging the lifetime of massive machine-type communication (MTC) networks is key to realizing a sustainable digitized society. Great energy savings can be achieved by accurately predicting MTC traffic followed by properly designed resource allocation mechanisms. However, selecting the proper MTC traffic predictor is not straightforward and depends on accuracy/complexity trade-offs and the specific MTC applications and network characteristics. Remarkably, the related state-of-the-art literature still lacks such debates. Herein, we assess the performance of several machine learning (ML) methods to predict Poisson and quasi-periodic MTC traffic in terms of accuracy and computational cost. Results show that the temporal convolutional network (TCN) outperforms the long-short term memory (LSTM), the gated recurrent units (GRU), and the recurrent neural network (RNN), in that order. For Poisson traffic, the accuracy gap between the predictors is larger than under quasi-periodic traffic. Finally, we show that running a TCN predictor is around three times more costly than other methods, while the training/inference time is the greatest/least.