 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProText: A benchmark dataset for measuring (mis)gendering in long-form texts
Mar 29, 2026We introduce ProText, a dataset for measuring gendering and misgendering in stylistically diverse long-form English texts. ProText spans three dimensions: Theme nouns (names, occupations, titles, kinship terms), Theme category (stereotypically male, stereotypically female, gender-neutral/non-gendered), and Pronoun category (masculine, feminine, gender-neutral, none). The dataset is designed to probe (mis)gendering in text transformations such as summarization and rewrites using state-of-the-art Large Language Models, extending beyond traditional pronoun resolution benchmarks and beyond the gender binary. We validated ProText through a mini case study, showing that even with just two prompts and two models, we can draw nuanced insights regarding gender bias, stereotyping, misgendering, and gendering. We reveal systematic gender bias, particularly when inputs contain no explicit gender cues or when models default to heteronormative assumptions.
LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations
Oct 03, 2024



Large language models (LLMs) often produce errors, including factual inaccuracies, biases, and reasoning failures, collectively referred to as "hallucinations". Recent studies have demonstrated that LLMs' internal states encode information regarding the truthfulness of their outputs, and that this information can be utilized to detect errors. In this work, we show that the internal representations of LLMs encode much more information about truthfulness than previously recognized. We first discover that the truthfulness information is concentrated in specific tokens, and leveraging this property significantly enhances error detection performance. Yet, we show that such error detectors fail to generalize across datasets, implying that -- contrary to prior claims -- truthfulness encoding is not universal but rather multifaceted. Next, we show that internal representations can also be used for predicting the types of errors the model is likely to make, facilitating the development of tailored mitigation strategies. Lastly, we reveal a discrepancy between LLMs' internal encoding and external behavior: they may encode the correct answer, yet consistently generate an incorrect one. Taken together, these insights deepen our understanding of LLM errors from the model's internal perspective, which can guide future research on enhancing error analysis and mitigation.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
Protected group bias and stereotypes in Large Language Models
Mar 21, 2024



As modern Large Language Models (LLMs) shatter many state-of-the-art benchmarks in a variety of domains, this paper investigates their behavior in the domains of ethics and fairness, focusing on protected group bias. We conduct a two-part study: first, we solicit sentence continuations describing the occupations of individuals from different protected groups, including gender, sexuality, religion, and race. Second, we have the model generate stories about individuals who hold different types of occupations. We collect >10k sentence completions made by a publicly available LLM, which we subject to human annotation. We find bias across minoritized groups, but in particular in the domains of gender and sexuality, as well as Western bias, in model generations. The model not only reflects societal biases, but appears to amplify them. The model is additionally overly cautious in replies to queries relating to minoritized groups, providing responses that strongly emphasize diversity and equity to an extent that other group characteristics are overshadowed. This suggests that artificially constraining potentially harmful outputs may itself lead to harm, and should be applied in a careful and controlled manner.
DELPHI: Data for Evaluating LLMs' Performance in Handling Controversial Issues
Nov 07, 2023



Controversy is a reflection of our zeitgeist, and an important aspect to any discourse. The rise of large language models (LLMs) as conversational systems has increased public reliance on these systems for answers to their various questions. Consequently, it is crucial to systematically examine how these models respond to questions that pertaining to ongoing debates. However, few such datasets exist in providing human-annotated labels reflecting the contemporary discussions. To foster research in this area, we propose a novel construction of a controversial questions dataset, expanding upon the publicly released Quora Question Pairs Dataset. This dataset presents challenges concerning knowledge recency, safety, fairness, and bias. We evaluate different LLMs using a subset of this dataset, illuminating how they handle controversial issues and the stances they adopt. This research ultimately contributes to our understanding of LLMs' interaction with controversial issues, paving the way for improvements in their comprehension and handling of complex societal debates.
Gender bias and stereotypes in Large Language Models
Aug 28, 2023Large Language Models (LLMs) have made substantial progress in the past several months, shattering state-of-the-art benchmarks in many domains. This paper investigates LLMs' behavior with respect to gender stereotypes, a known issue for prior models. We use a simple paradigm to test the presence of gender bias, building on but differing from WinoBias, a commonly used gender bias dataset, which is likely to be included in the training data of current LLMs. We test four recently published LLMs and demonstrate that they express biased assumptions about men and women's occupations. Our contributions in this paper are as follows: (a) LLMs are 3-6 times more likely to choose an occupation that stereotypically aligns with a person's gender; (b) these choices align with people's perceptions better than with the ground truth as reflected in official job statistics; (c) LLMs in fact amplify the bias beyond what is reflected in perceptions or the ground truth; (d) LLMs ignore crucial ambiguities in sentence structure 95% of the time in our study items, but when explicitly prompted, they recognize the ambiguity; (e) LLMs provide explanations for their choices that are factually inaccurate and likely obscure the true reason behind their predictions. That is, they provide rationalizations of their biased behavior. This highlights a key property of these models: LLMs are trained on imbalanced datasets; as such, even with the recent successes of reinforcement learning with human feedback, they tend to reflect those imbalances back at us. As with other types of societal biases, we suggest that LLMs must be carefully tested to ensure that they treat minoritized individuals and communities equitably.
* ACM Collective Intelligence
Feedback Effect in User Interaction with Intelligent Assistants: Delayed Engagement, Adaption and Drop-out
Mar 17, 2023With the growing popularity of intelligent assistants (IAs), evaluating IA quality becomes an increasingly active field of research. This paper identifies and quantifies the feedback effect, a novel component in IA-user interactions: how the capabilities and limitations of the IA influence user behavior over time. First, we demonstrate that unhelpful responses from the IA cause users to delay or reduce subsequent interactions in the short term via an observational study. Next, we expand the time horizon to examine behavior changes and show that as users discover the limitations of the IA's understanding and functional capabilities, they learn to adjust the scope and wording of their requests to increase the likelihood of receiving a helpful response from the IA. Our findings highlight the impact of the feedback effect at both the micro and meso levels. We further discuss its macro-level consequences: unsatisfactory interactions continuously reduce the likelihood and diversity of future user engagements in a feedback loop.
MMIU: Dataset for Visual Intent Understanding in Multimodal Assistants
Oct 31, 2021
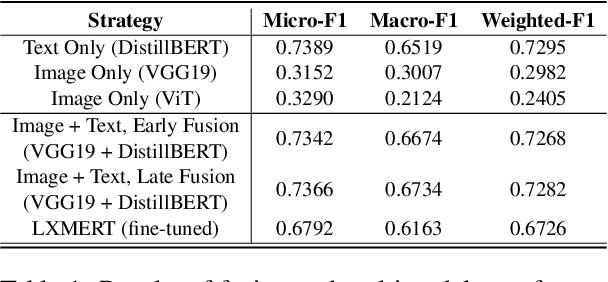


In multimodal assistant, where vision is also one of the input modalities, the identification of user intent becomes a challenging task as visual input can influence the outcome. Current digital assistants take spoken input and try to determine the user intent from conversational or device context. So, a dataset, which includes visual input (i.e. images or videos for the corresponding questions targeted for multimodal assistant use cases, is not readily available. The research in visual question answering (VQA) and visual question generation (VQG) is a great step forward. However, they do not capture questions that a visually-abled person would ask multimodal assistants. Moreover, many times questions do not seek information from external knowledge. In this paper, we provide a new dataset, MMIU (MultiModal Intent Understanding), that contains questions and corresponding intents provided by human annotators while looking at images. We, then, use this dataset for intent classification task in multimodal digital assistant. We also experiment with various approaches for combining vision and language features including the use of multimodal transformer for classification of image-question pairs into 14 intents. We provide the benchmark results and discuss the role of visual and text features for the intent classification task on our dataset.
Improving Human-Labeled Data through Dynamic Automatic Conflict Resolution
Dec 08, 2020
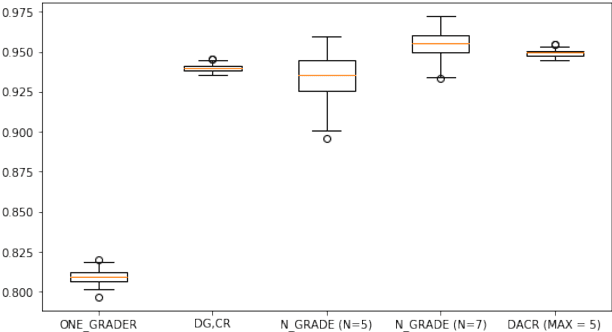

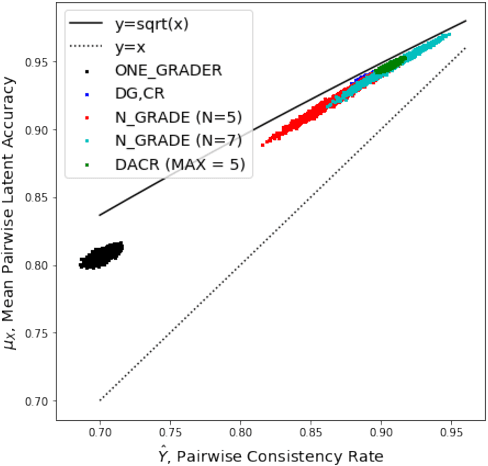
This paper develops and implements a scalable methodology for (a) estimating the noisiness of labels produced by a typical crowdsourcing semantic annotation task, and (b) reducing the resulting error of the labeling process by as much as 20-30% in comparison to other common labeling strategies. Importantly, this new approach to the labeling process, which we name Dynamic Automatic Conflict Resolution (DACR), does not require a ground truth dataset and is instead based on inter-project annotation inconsistencies. This makes DACR not only more accurate but also available to a broad range of labeling tasks. In what follows we present results from a text classification task performed at scale for a commercial personal assistant, and evaluate the inherent ambiguity uncovered by this annotation strategy as compared to other common labeling strategies.
Generating Natural Questions from Images for Multimodal Assistants
Nov 17, 2020
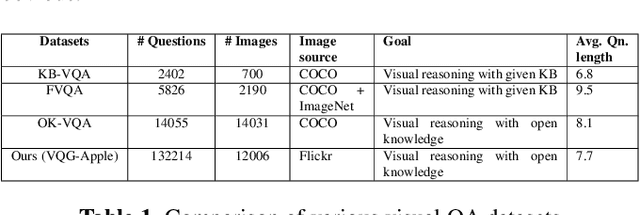

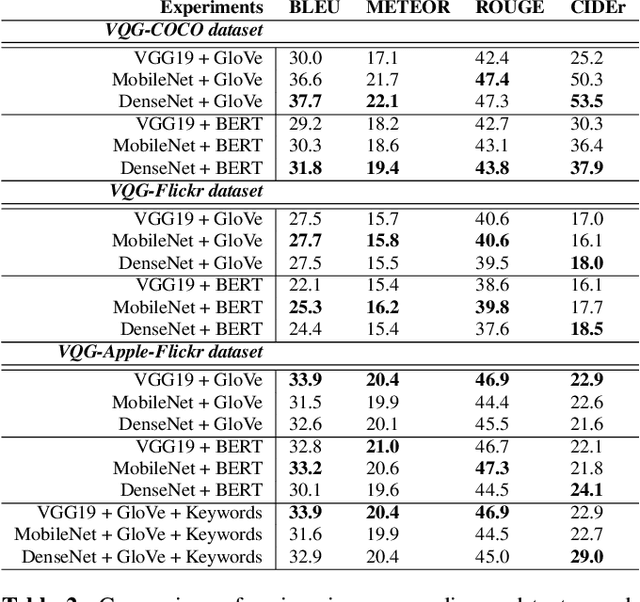
Generating natural, diverse, and meaningful questions from images is an essential task for multimodal assistants as it confirms whether they have understood the object and scene in the images properly. The research in visual question answering (VQA) and visual question generation (VQG) is a great step. However, this research does not capture questions that a visually-abled person would ask multimodal assistants. Recently published datasets such as KB-VQA, FVQA, and OK-VQA try to collect questions that look for external knowledge which makes them appropriate for multimodal assistants. However, they still contain many obvious and common-sense questions that humans would not usually ask a digital assistant. In this paper, we provide a new benchmark dataset that contains questions generated by human annotators keeping in mind what they would ask multimodal digital assistants. Large scale annotations for several hundred thousand images are expensive and time-consuming, so we also present an effective way of automatically generating questions from unseen images. In this paper, we present an approach for generating diverse and meaningful questions that consider image content and metadata of image (e.g., location, associated keyword). We evaluate our approach using standard evaluation metrics such as BLEU, METEOR, ROUGE, and CIDEr to show the relevance of generated questions with human-provided questions. We also measure the diversity of generated questions using generative strength and inventiveness metrics. We report new state-of-the-art results on the public and our datasets.