 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausalTAD: Causal Implicit Generative Model for Debiased Online Trajectory Anomaly Detection
Dec 25, 2024



Trajectory anomaly detection, aiming to estimate the anomaly risk of trajectories given the Source-Destination (SD) pairs, has become a critical problem for many real-world applications. Existing solutions directly train a generative model for observed trajectories and calculate the conditional generative probability $P({T}|{C})$ as the anomaly risk, where ${T}$ and ${C}$ represent the trajectory and SD pair respectively. However, we argue that the observed trajectories are confounded by road network preference which is a common cause of both SD distribution and trajectories. Existing methods ignore this issue limiting their generalization ability on out-of-distribution trajectories. In this paper, we define the debiased trajectory anomaly detection problem and propose a causal implicit generative model, namely CausalTAD, to solve it. CausalTAD adopts do-calculus to eliminate the confounding bias of road network preference and estimates $P({T}|do({C}))$ as the anomaly criterion. Extensive experiments show that CausalTAD can not only achieve superior performance on trained trajectories but also generally improve the performance of out-of-distribution data, with improvements of $2.1\% \sim 5.7\%$ and $10.6\% \sim 32.7\%$ respectively.
Effective and Efficient Representation Learning for Flight Trajectories
Dec 21, 2024



Flight trajectory data plays a vital role in the traffic management community, especially for downstream tasks such as trajectory prediction, flight recognition, and anomaly detection. Existing works often utilize handcrafted features and design models for different tasks individually, which heavily rely on domain expertise and are hard to extend. We argue that different flight analysis tasks share the same useful features of the trajectory. Jointly learning a unified representation for flight trajectories could be beneficial for improving the performance of various tasks. However, flight trajectory representation learning (TRL) faces two primary challenges, \ie unbalanced behavior density and 3D spatial continuity, which disable recent general TRL methods. In this paper, we propose Flight2Vec , a flight-specific representation learning method to address these challenges. Specifically, a behavior-adaptive patching mechanism is used to inspire the learned representation to pay more attention to behavior-dense segments. Moreover, we introduce a motion trend learning technique that guides the model to memorize not only the precise locations, but also the motion trend to generate better representations. Extensive experimental results demonstrate that Flight2Vec significantly improves performance in downstream tasks such as flight trajectory prediction, flight recognition, and anomaly detection.
PORCA: Root Cause Analysis with Partially
Jul 08, 2024



Root Cause Analysis (RCA) aims at identifying the underlying causes of system faults by uncovering and analyzing the causal structure from complex systems. It has been widely used in many application domains. Reliable diagnostic conclusions are of great importance in mitigating system failures and financial losses. However, previous studies implicitly assume a full observation of the system, which neglect the effect of partial observation (i.e., missing nodes and latent malfunction). As a result, they fail in deriving reliable RCA results. In this paper, we unveil the issues of unobserved confounders and heterogeneity in partial observation and come up with a new problem of root cause analysis with partially observed data. To achieve this, we propose PORCA, a novel RCA framework which can explore reliable root causes under both unobserved confounders and unobserved heterogeneity. PORCA leverages magnified score-based causal discovery to efficiently optimize acyclic directed mixed graph under unobserved confounders. In addition, we also develop a heterogeneity-aware scheduling strategy to provide adaptive sample weights. Extensive experimental results on one synthetic and two real-world datasets demonstrate the effectiveness and superiority of the proposed framework.
STBench: Assessing the Ability of Large Language Models in Spatio-Temporal Analysis
Jun 27, 2024



The rapid evolution of large language models (LLMs) holds promise for reforming the methodology of spatio-temporal data mining. However, current works for evaluating the spatio-temporal understanding capability of LLMs are somewhat limited and biased. These works either fail to incorporate the latest language models or only focus on assessing the memorized spatio-temporal knowledge. To address this gap, this paper dissects LLMs' capability of spatio-temporal data into four distinct dimensions: knowledge comprehension, spatio-temporal reasoning, accurate computation, and downstream applications. We curate several natural language question-answer tasks for each category and build the benchmark dataset, namely STBench, containing 13 distinct tasks and over 60,000 QA pairs. Moreover, we have assessed the capabilities of 13 LLMs, such as GPT-4o, Gemma and Mistral. Experimental results reveal that existing LLMs show remarkable performance on knowledge comprehension and spatio-temporal reasoning tasks, with potential for further enhancement on other tasks through in-context learning, chain-of-though prompting, and fine-tuning. The code and datasets of STBench are released on https://github.com/LwbXc/STBench.
CausalMMM: Learning Causal Structure for Marketing Mix Modeling
Jun 24, 2024In online advertising, marketing mix modeling (MMM) is employed to predict the gross merchandise volume (GMV) of brand shops and help decision-makers to adjust the budget allocation of various advertising channels. Traditional MMM methods leveraging regression techniques can fail in handling the complexity of marketing. Although some efforts try to encode the causal structures for better prediction, they have the strict restriction that causal structures are prior-known and unchangeable. In this paper, we define a new causal MMM problem that automatically discovers the interpretable causal structures from data and yields better GMV predictions. To achieve causal MMM, two essential challenges should be addressed: (1) Causal Heterogeneity. The causal structures of different kinds of shops vary a lot. (2) Marketing Response Patterns. Various marketing response patterns i.e., carryover effect and shape effect, have been validated in practice. We argue that causal MMM needs dynamically discover specific causal structures for different shops and the predictions should comply with the prior known marketing response patterns. Thus, we propose CausalMMM that integrates Granger causality in a variational inference framework to measure the causal relationships between different channels and predict the GMV with the regularization of both temporal and saturation marketing response patterns. Extensive experiments show that CausalMMM can not only achieve superior performance of causal structure learning on synthetic datasets with improvements of 5.7%\sim 7.1%, but also enhance the GMV prediction results on a representative E-commerce platform.
AnomalyLLM: Few-shot Anomaly Edge Detection for Dynamic Graphs using Large Language Models
May 13, 2024



Detecting anomaly edges for dynamic graphs aims to identify edges significantly deviating from the normal pattern and can be applied in various domains, such as cybersecurity, financial transactions and AIOps. With the evolving of time, the types of anomaly edges are emerging and the labeled anomaly samples are few for each type. Current methods are either designed to detect randomly inserted edges or require sufficient labeled data for model training, which harms their applicability for real-world applications. In this paper, we study this problem by cooperating with the rich knowledge encoded in large language models(LLMs) and propose a method, namely AnomalyLLM. To align the dynamic graph with LLMs, AnomalyLLM pre-trains a dynamic-aware encoder to generate the representations of edges and reprograms the edges using the prototypes of word embeddings. Along with the encoder, we design an in-context learning framework that integrates the information of a few labeled samples to achieve few-shot anomaly detection. Experiments on four datasets reveal that AnomalyLLM can not only significantly improve the performance of few-shot anomaly detection, but also achieve superior results on new anomalies without any update of model parameters.
Causal Discovery from Temporal Data: An Overview and New Perspectives
Mar 17, 2023



Temporal data, representing chronological observations of complex systems, has always been a typical data structure that can be widely generated by many domains, such as industry, medicine and finance. Analyzing this type of data is extremely valuable for various applications. Thus, different temporal data analysis tasks, eg, classification, clustering and prediction, have been proposed in the past decades. Among them, causal discovery, learning the causal relations from temporal data, is considered an interesting yet critical task and has attracted much research attention. Existing casual discovery works can be divided into two highly correlated categories according to whether the temporal data is calibrated, ie, multivariate time series casual discovery, and event sequence casual discovery. However, most previous surveys are only focused on the time series casual discovery and ignore the second category. In this paper, we specify the correlation between the two categories and provide a systematical overview of existing solutions. Furthermore, we provide public datasets, evaluation metrics and new perspectives for temporal data casual discovery.
CausalMTA: Eliminating the User Confounding Bias for Causal Multi-touch Attribution
Dec 21, 2021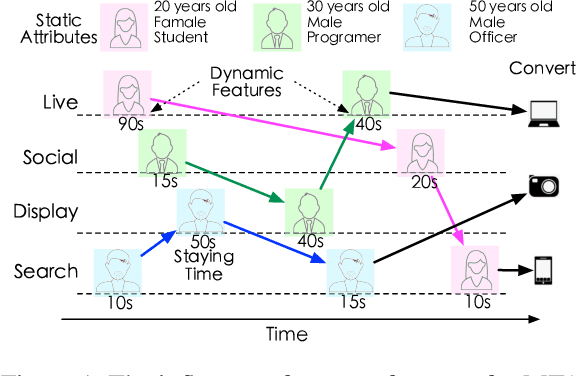
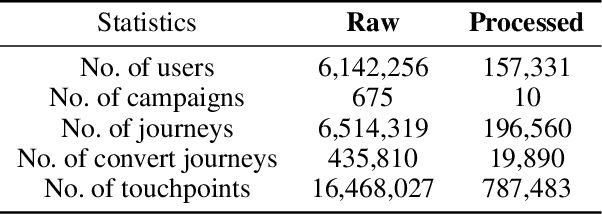
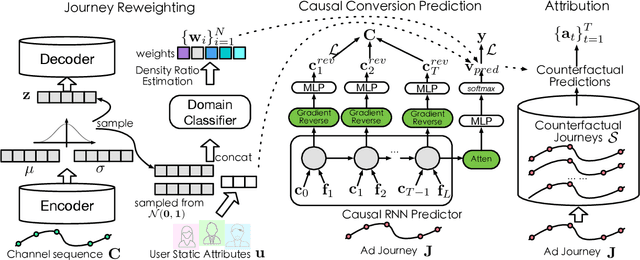
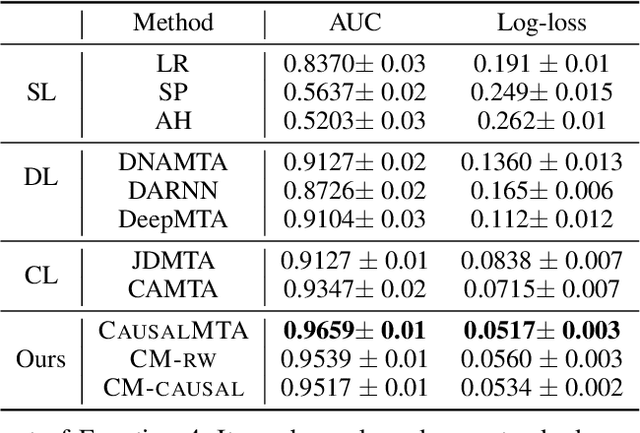
Multi-touch attribution (MTA), aiming to estimate the contribution of each advertisement touchpoint in conversion journeys, is essential for budget allocation and automatically advertising. Existing methods first train a model to predict the conversion probability of the advertisement journeys with historical data and calculate the attribution of each touchpoint using counterfactual predictions. An assumption of these works is the conversion prediction model is unbiased, i.e., it can give accurate predictions on any randomly assigned journey, including both the factual and counterfactual ones. Nevertheless, this assumption does not always hold as the exposed advertisements are recommended according to user preferences. This confounding bias of users would lead to an out-of-distribution (OOD) problem in the counterfactual prediction and cause concept drift in attribution. In this paper, we define the causal MTA task and propose CausalMTA to eliminate the influence of user preferences. It systemically eliminates the confounding bias from both static and dynamic preferences to learn the conversion prediction model using historical data. We also provide a theoretical analysis to prove CausalMTA can learn an unbiased prediction model with sufficient data. Extensive experiments on both public datasets and the impression data in an e-commerce company show that CausalMTA not only achieves better prediction performance than the state-of-the-art method but also generates meaningful attribution credits across different advertising channels.