 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtected group bias and stereotypes in Large Language Models
Mar 21, 2024



As modern Large Language Models (LLMs) shatter many state-of-the-art benchmarks in a variety of domains, this paper investigates their behavior in the domains of ethics and fairness, focusing on protected group bias. We conduct a two-part study: first, we solicit sentence continuations describing the occupations of individuals from different protected groups, including gender, sexuality, religion, and race. Second, we have the model generate stories about individuals who hold different types of occupations. We collect >10k sentence completions made by a publicly available LLM, which we subject to human annotation. We find bias across minoritized groups, but in particular in the domains of gender and sexuality, as well as Western bias, in model generations. The model not only reflects societal biases, but appears to amplify them. The model is additionally overly cautious in replies to queries relating to minoritized groups, providing responses that strongly emphasize diversity and equity to an extent that other group characteristics are overshadowed. This suggests that artificially constraining potentially harmful outputs may itself lead to harm, and should be applied in a careful and controlled manner.
DELPHI: Data for Evaluating LLMs' Performance in Handling Controversial Issues
Nov 07, 2023



Controversy is a reflection of our zeitgeist, and an important aspect to any discourse. The rise of large language models (LLMs) as conversational systems has increased public reliance on these systems for answers to their various questions. Consequently, it is crucial to systematically examine how these models respond to questions that pertaining to ongoing debates. However, few such datasets exist in providing human-annotated labels reflecting the contemporary discussions. To foster research in this area, we propose a novel construction of a controversial questions dataset, expanding upon the publicly released Quora Question Pairs Dataset. This dataset presents challenges concerning knowledge recency, safety, fairness, and bias. We evaluate different LLMs using a subset of this dataset, illuminating how they handle controversial issues and the stances they adopt. This research ultimately contributes to our understanding of LLMs' interaction with controversial issues, paving the way for improvements in their comprehension and handling of complex societal debates.
Feedback Effect in User Interaction with Intelligent Assistants: Delayed Engagement, Adaption and Drop-out
Mar 17, 2023With the growing popularity of intelligent assistants (IAs), evaluating IA quality becomes an increasingly active field of research. This paper identifies and quantifies the feedback effect, a novel component in IA-user interactions: how the capabilities and limitations of the IA influence user behavior over time. First, we demonstrate that unhelpful responses from the IA cause users to delay or reduce subsequent interactions in the short term via an observational study. Next, we expand the time horizon to examine behavior changes and show that as users discover the limitations of the IA's understanding and functional capabilities, they learn to adjust the scope and wording of their requests to increase the likelihood of receiving a helpful response from the IA. Our findings highlight the impact of the feedback effect at both the micro and meso levels. We further discuss its macro-level consequences: unsatisfactory interactions continuously reduce the likelihood and diversity of future user engagements in a feedback loop.
Improving Human-Labeled Data through Dynamic Automatic Conflict Resolution
Dec 08, 2020
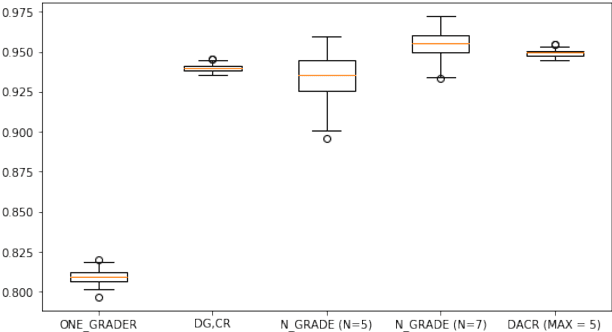

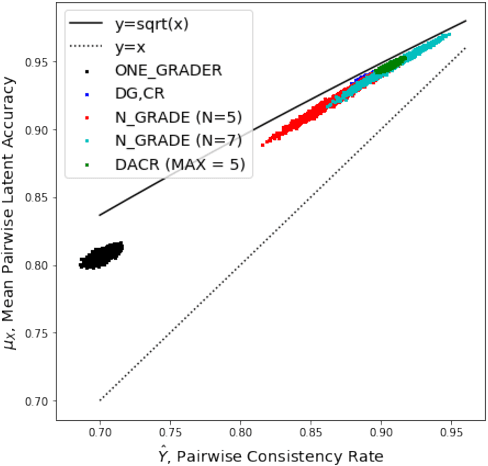
This paper develops and implements a scalable methodology for (a) estimating the noisiness of labels produced by a typical crowdsourcing semantic annotation task, and (b) reducing the resulting error of the labeling process by as much as 20-30% in comparison to other common labeling strategies. Importantly, this new approach to the labeling process, which we name Dynamic Automatic Conflict Resolution (DACR), does not require a ground truth dataset and is instead based on inter-project annotation inconsistencies. This makes DACR not only more accurate but also available to a broad range of labeling tasks. In what follows we present results from a text classification task performed at scale for a commercial personal assistant, and evaluate the inherent ambiguity uncovered by this annotation strategy as compared to other common labeling strategies.
Generating Natural Questions from Images for Multimodal Assistants
Nov 17, 2020
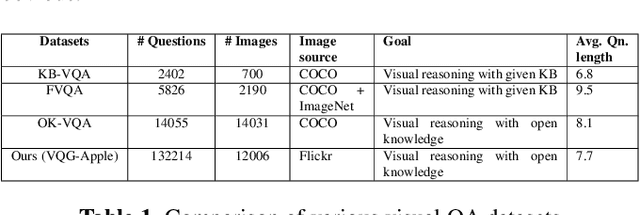

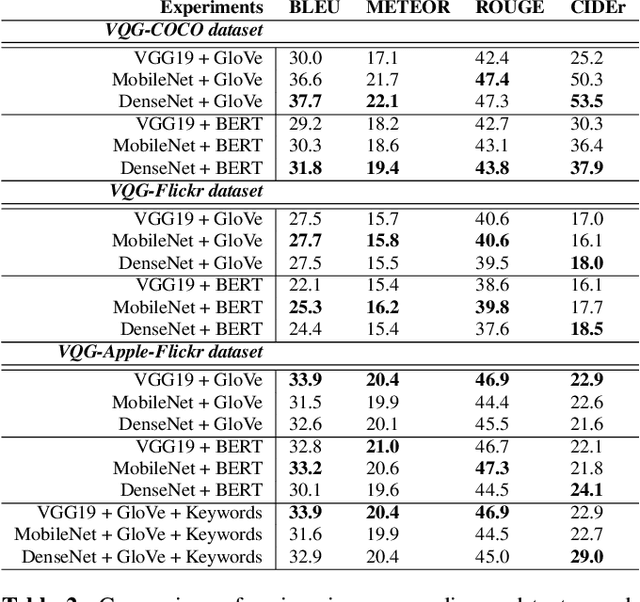
Generating natural, diverse, and meaningful questions from images is an essential task for multimodal assistants as it confirms whether they have understood the object and scene in the images properly. The research in visual question answering (VQA) and visual question generation (VQG) is a great step. However, this research does not capture questions that a visually-abled person would ask multimodal assistants. Recently published datasets such as KB-VQA, FVQA, and OK-VQA try to collect questions that look for external knowledge which makes them appropriate for multimodal assistants. However, they still contain many obvious and common-sense questions that humans would not usually ask a digital assistant. In this paper, we provide a new benchmark dataset that contains questions generated by human annotators keeping in mind what they would ask multimodal digital assistants. Large scale annotations for several hundred thousand images are expensive and time-consuming, so we also present an effective way of automatically generating questions from unseen images. In this paper, we present an approach for generating diverse and meaningful questions that consider image content and metadata of image (e.g., location, associated keyword). We evaluate our approach using standard evaluation metrics such as BLEU, METEOR, ROUGE, and CIDEr to show the relevance of generated questions with human-provided questions. We also measure the diversity of generated questions using generative strength and inventiveness metrics. We report new state-of-the-art results on the public and our datasets.
Active Learning for Domain Classification in a Commercial Spoken Personal Assistant
Aug 29, 2019
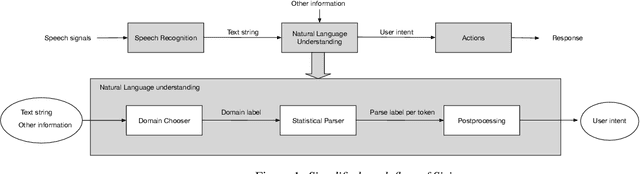
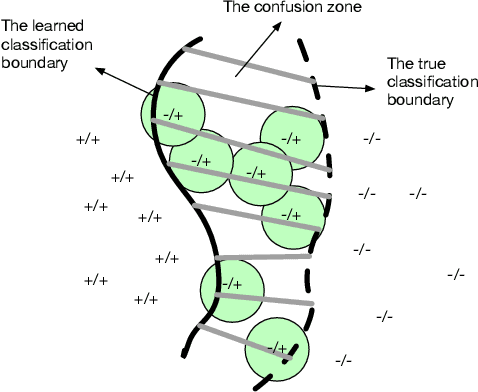
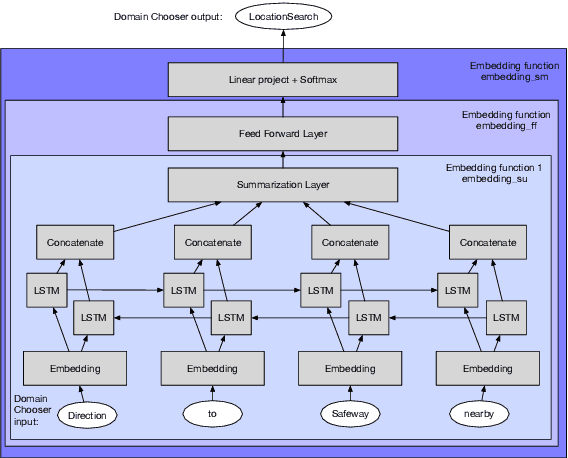
We describe a method for selecting relevant new training data for the LSTM-based domain selection component of our personal assistant system. Adding more annotated training data for any ML system typically improves accuracy, but only if it provides examples not already adequately covered in the existing data. However, obtaining, selecting, and labeling relevant data is expensive. This work presents a simple technique that automatically identifies new helpful examples suitable for human annotation. Our experimental results show that the proposed method, compared with random-selection and entropy-based methods, leads to higher accuracy improvements given a fixed annotation budget. Although developed and tested in the setting of a commercial intelligent assistant, the technique is of wider applicability.