 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The Potential and Pitfalls of using a Large Language Model such as ChatGPT or GPT-4 as a Clinical Assistant
Jul 16, 2023

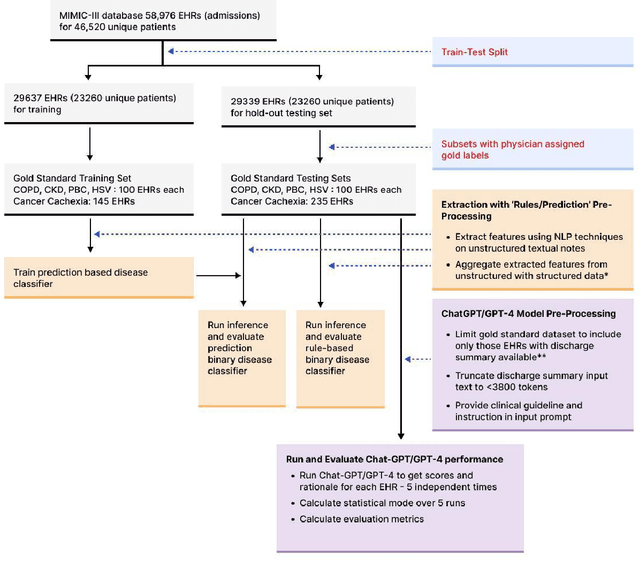
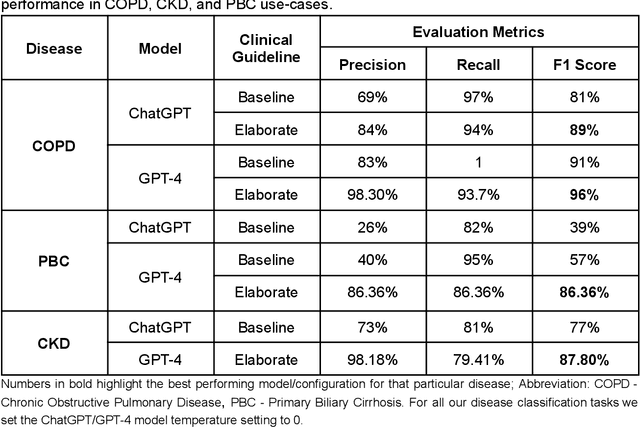
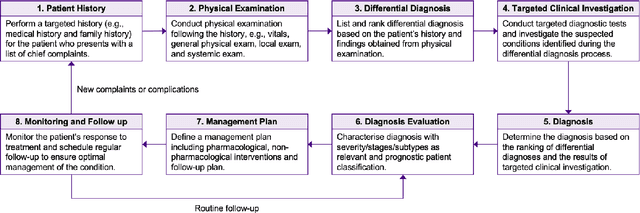
Recent studies have demonstrated promising performance of ChatGPT and GPT-4 on several medical domain tasks. However, none have assessed its performance using a large-scale real-world electronic health record database, nor have evaluated its utility in providing clinical diagnostic assistance for patients across a full range of disease presentation. We performed two analyses using ChatGPT and GPT-4, one to identify patients with specific medical diagnoses using a real-world large electronic health record database and the other, in providing diagnostic assistance to healthcare workers in the prospective evaluation of hypothetical patients. Our results show that GPT-4 across disease classification tasks with chain of thought and few-shot prompting can achieve performance as high as 96% F1 scores. For patient assessment, GPT-4 can accurately diagnose three out of four times. However, there were mentions of factually incorrect statements, overlooking crucial medical findings, recommendations for unnecessary investigations and overtreatment. These issues coupled with privacy concerns, make these models currently inadequate for real world clinical use. However, limited data and time needed for prompt engineering in comparison to configuration of conventional machine learning workflows highlight their potential for scalability across healthcare applications.
SARC: Soft Actor Retrospective Critic
Jun 28, 2023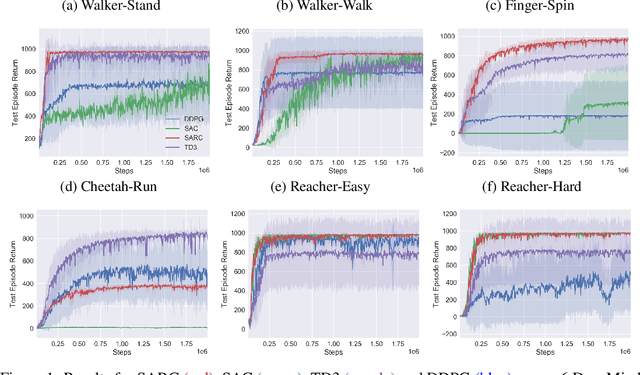
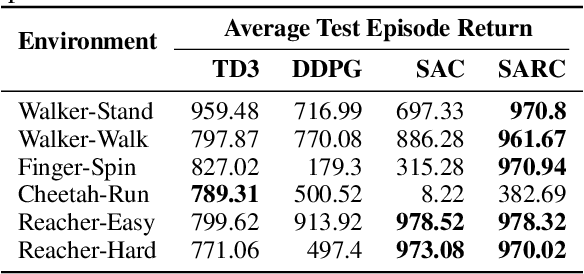
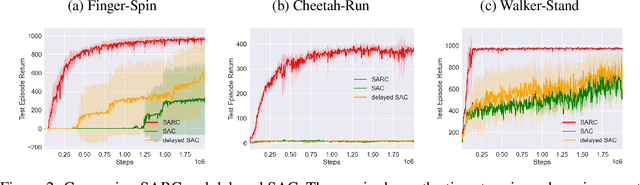
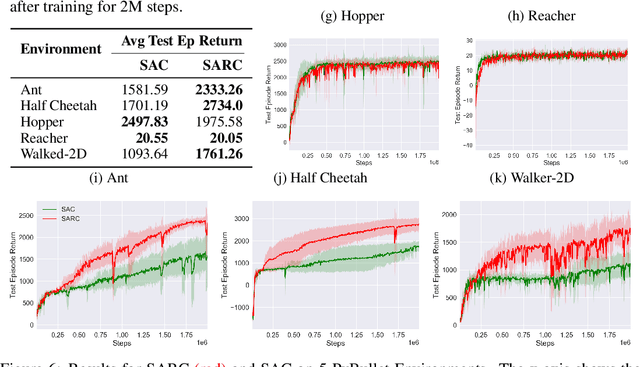
The two-time scale nature of SAC, which is an actor-critic algorithm, is characterised by the fact that the critic estimate has not converged for the actor at any given time, but since the critic learns faster than the actor, it ensures eventual consistency between the two. Various strategies have been introduced in literature to learn better gradient estimates to help achieve better convergence. Since gradient estimates depend upon the critic, we posit that improving the critic can provide a better gradient estimate for the actor at each time. Utilizing this, we propose Soft Actor Retrospective Critic (SARC), where we augment the SAC critic loss with another loss term - retrospective loss - leading to faster critic convergence and consequently, better policy gradient estimates for the actor. An existing implementation of SAC can be easily adapted to SARC with minimal modifications. Through extensive experimentation and analysis, we show that SARC provides consistent improvement over SAC on benchmark environments. We plan to open-source the code and all experiment data at: https://github.com/sukritiverma1996/SARC.
Bake off redux: a review and experimental evaluation of recent time series classification algorithms
Apr 25, 2023
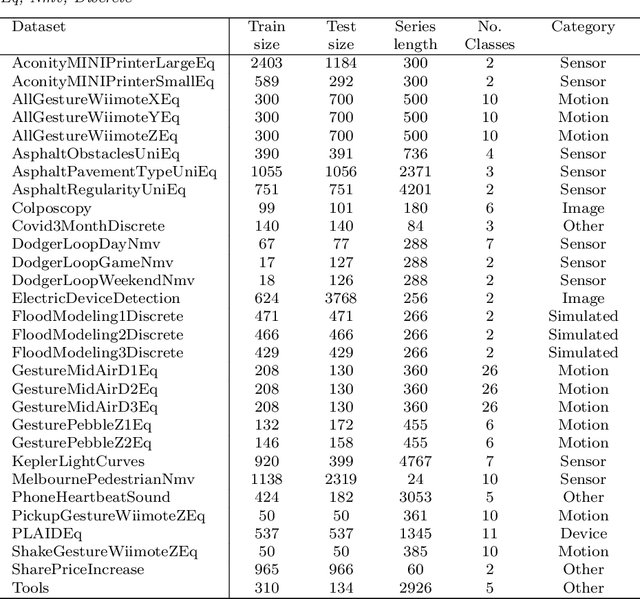
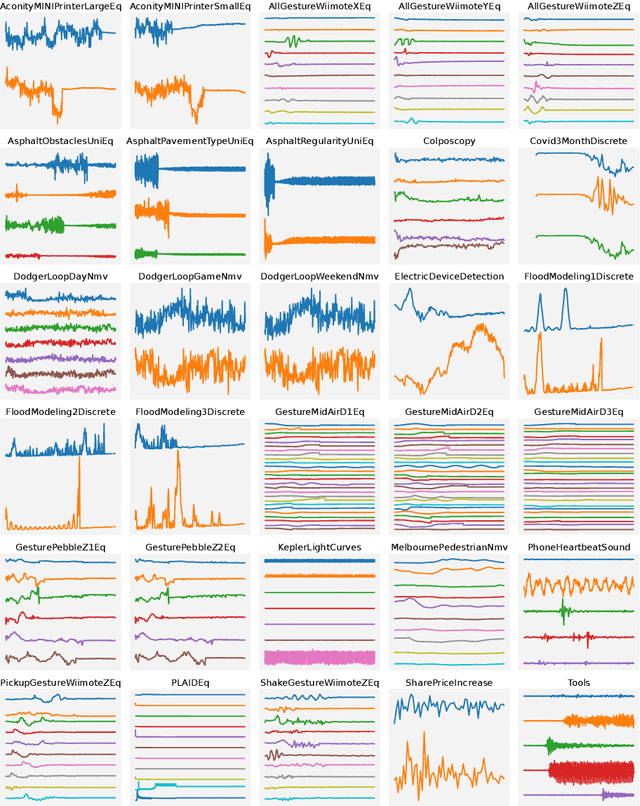
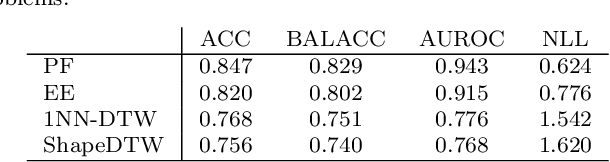
In 2017, a research paper compared 18 Time Series Classification (TSC) algorithms on 85 datasets from the University of California, Riverside (UCR) archive. This study, commonly referred to as a `bake off', identified that only nine algorithms performed significantly better than the Dynamic Time Warping (DTW) and Rotation Forest benchmarks that were used. The study categorised each algorithm by the type of feature they extract from time series data, forming a taxonomy of five main algorithm types. This categorisation of algorithms alongside the provision of code and accessible results for reproducibility has helped fuel an increase in popularity of the TSC field. Over six years have passed since this bake off, the UCR archive has expanded to 112 datasets and there have been a large number of new algorithms proposed. We revisit the bake off, seeing how each of the proposed categories have advanced since the original publication, and evaluate the performance of newer algorithms against the previous best-of-category using an expanded UCR archive. We extend the taxonomy to include three new categories to reflect recent developments. Alongside the originally proposed distance, interval, shapelet, dictionary and hybrid based algorithms, we compare newer convolution and feature based algorithms as well as deep learning approaches. We introduce 30 classification datasets either recently donated to the archive or reformatted to the TSC format, and use these to further evaluate the best performing algorithm from each category. Overall, we find that two recently proposed algorithms, Hydra+MultiROCKET and HIVE-COTEv2, perform significantly better than other approaches on both the current and new TSC problems.
Using Large Language Models to Provide Explanatory Feedback to Human Tutors
Jun 27, 2023
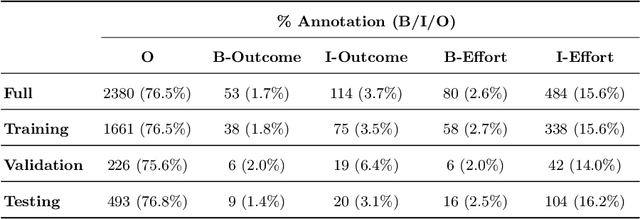

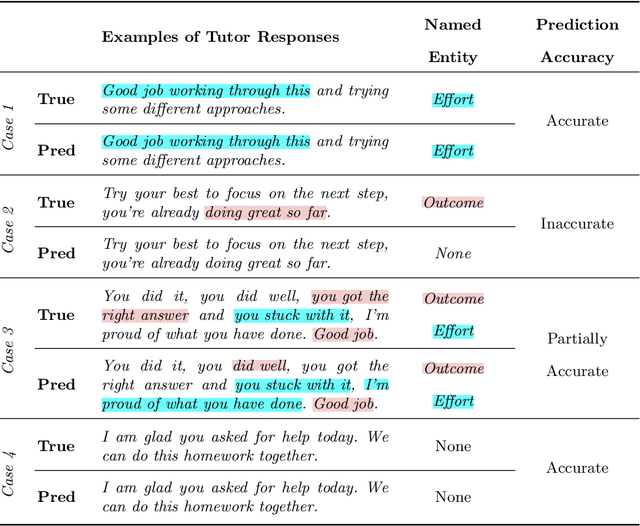
Research demonstrates learners engaging in the process of producing explanations to support their reasoning, can have a positive impact on learning. However, providing learners real-time explanatory feedback often presents challenges related to classification accuracy, particularly in domain-specific environments, containing situationally complex and nuanced responses. We present two approaches for supplying tutors real-time feedback within an online lesson on how to give students effective praise. This work-in-progress demonstrates considerable accuracy in binary classification for corrective feedback of effective, or effort-based (F1 score = 0.811), and ineffective, or outcome-based (F1 score = 0.350), praise responses. More notably, we introduce progress towards an enhanced approach of providing explanatory feedback using large language model-facilitated named entity recognition, which can provide tutors feedback, not only while engaging in lessons, but can potentially suggest real-time tutor moves. Future work involves leveraging large language models for data augmentation to improve accuracy, while also developing an explanatory feedback interface.
TodyNet: Temporal Dynamic Graph Neural Network for Multivariate Time Series Classification
Apr 11, 2023Multivariate time series classification (MTSC) is an important data mining task, which can be effectively solved by popular deep learning technology. Unfortunately, the existing deep learning-based methods neglect the hidden dependencies in different dimensions and also rarely consider the unique dynamic features of time series, which lack sufficient feature extraction capability to obtain satisfactory classification accuracy. To address this problem, we propose a novel temporal dynamic graph neural network (TodyNet) that can extract hidden spatio-temporal dependencies without undefined graph structure. It enables information flow among isolated but implicit interdependent variables and captures the associations between different time slots by dynamic graph mechanism, which further improves the classification performance of the model. Meanwhile, the hierarchical representations of graphs cannot be learned due to the limitation of GNNs. Thus, we also design a temporal graph pooling layer to obtain a global graph-level representation for graph learning with learnable temporal parameters. The dynamic graph, graph information propagation, and temporal convolution are jointly learned in an end-to-end framework. The experiments on 26 UEA benchmark datasets illustrate that the proposed TodyNet outperforms existing deep learning-based methods in the MTSC tasks.
Tiny-PPG: A Lightweight Deep Neural Network for Real-Time Detection of Motion Artifacts in Photoplethysmogram Signals on Edge Devices
May 05, 2023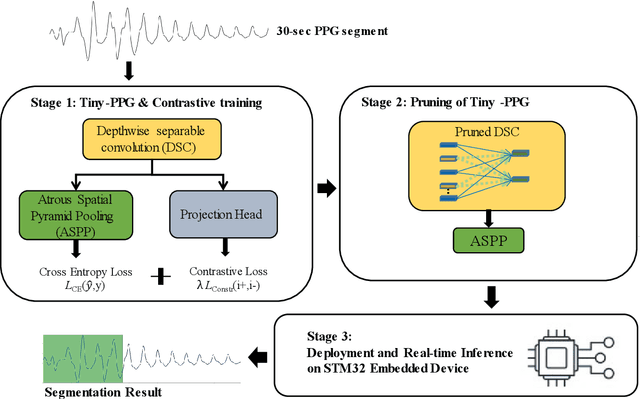
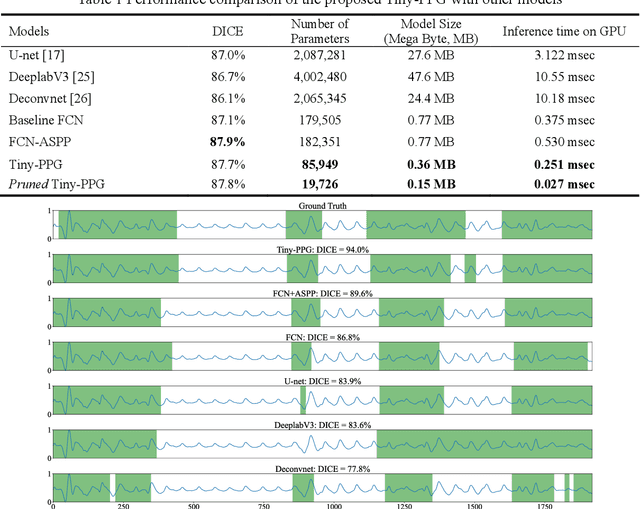
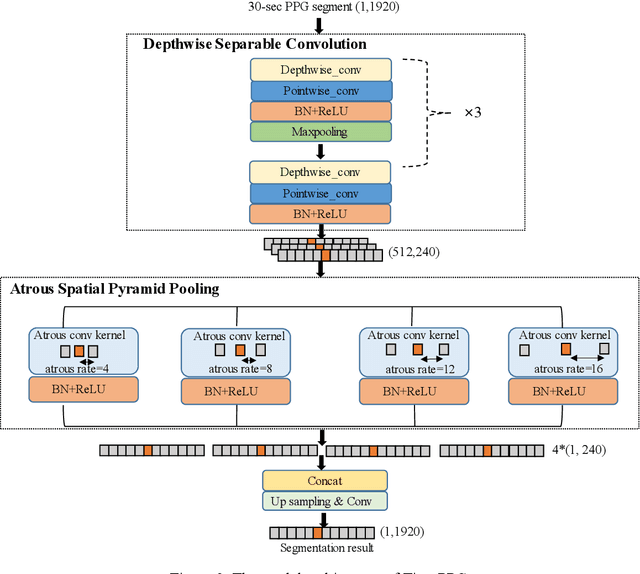
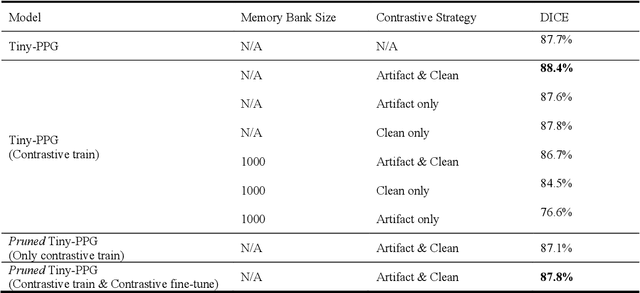
Photoplethysmogram (PPG) signals are easily contaminated by motion artifacts in real-world settings, despite their widespread use in Internet-of-Things (IoT) based wearable and smart health devices for cardiovascular health monitoring. This study proposed a lightweight deep neural network, called Tiny-PPG, for accurate and real-time PPG artifact segmentation on IoT edge devices. The model was trained and tested on a public dataset, PPG DaLiA, which featured complex artifacts with diverse lengths and morphologies during various daily activities of 15 subjects using a watch-type device (Empatica E4). The model structure, training method and loss function were specifically designed to balance detection accuracy and speed for real-time PPG artifact detection in resource-constrained embedded devices. To optimize the model size and capability in multi-scale feature representation, the model employed deep separable convolution and atrous spatial pyramid pooling modules, respectively. Additionally, the contrastive loss was also utilized to further optimize the feature embeddings. With additional model pruning, Tiny-PPG achieved state-of-the-art detection accuracy of 87.8% while only having 19,726 model parameters (0.15 megabytes), and was successfully deployed on an STM32 embedded system for real-time PPG artifact detection. Therefore, this study provides an effective solution for resource-constraint IoT smart health devices in PPG artifact detection.
CareFall: Automatic Fall Detection through Wearable Devices and AI Methods
Jul 11, 2023
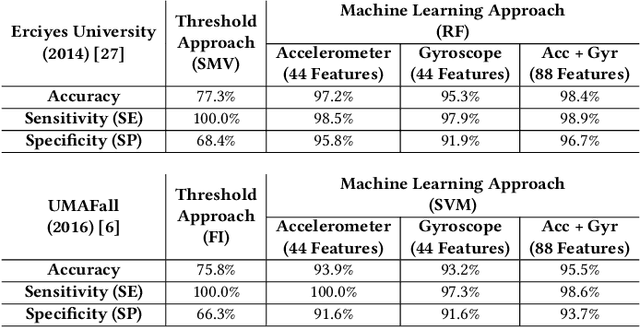
The aging population has led to a growing number of falls in our society, affecting global public health worldwide. This paper presents CareFall, an automatic Fall Detection System (FDS) based on wearable devices and Artificial Intelligence (AI) methods. CareFall considers the accelerometer and gyroscope time signals extracted from a smartwatch. Two different approaches are used for feature extraction and classification: i) threshold-based, and ii) machine learning-based. Experimental results on two public databases show that the machine learning-based approach, which combines accelerometer and gyroscope information, outperforms the threshold-based approach in terms of accuracy, sensitivity, and specificity. This research contributes to the design of smart and user-friendly solutions to mitigate the negative consequences of falls among older people.
Sequential Manipulation Planning for Over-actuated Unmanned Aerial Manipulators
Jul 11, 2023
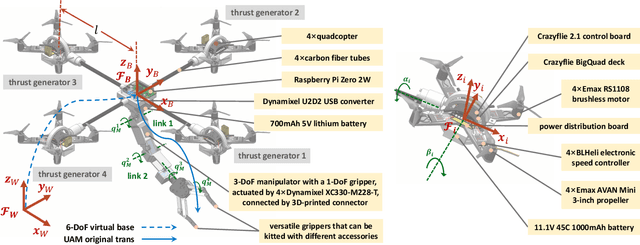
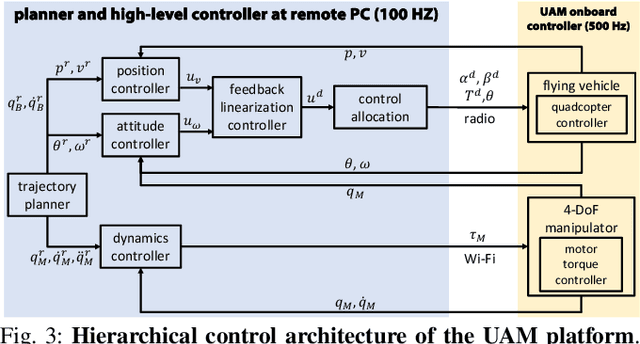
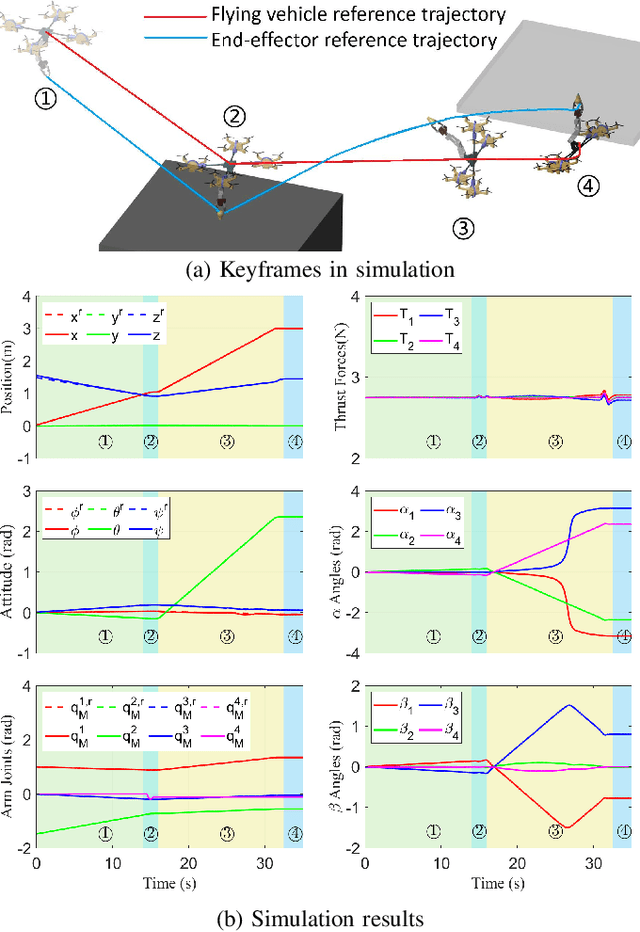
We investigate the sequential manipulation planning problem for unmanned aerial manipulators (UAMs). Unlike prior work that primarily focuses on one-step manipulation tasks, sequential manipulations require coordinated motions of a UAM's floating base, the manipulator, and the object being manipulated, entailing a unified kinematics and dynamics model for motion planning under designated constraints. By leveraging a virtual kinematic chain (VKC)-based motion planning framework that consolidates components' kinematics into one chain, the sequential manipulation task of a UAM can be planned as a whole, yielding more coordinated motions. Integrating the kinematics and dynamics models with a hierarchical control framework, we demonstrate, for the first time, an over-actuated UAM achieves a series of new sequential manipulation capabilities in both simulation and experiment.
Making the Most Out of the Limited Context Length: Predictive Power Varies with Clinical Note Type and Note Section
Jul 13, 2023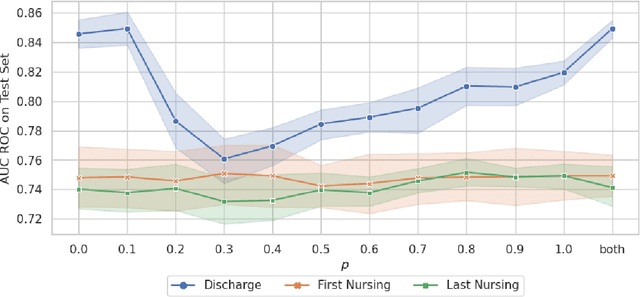
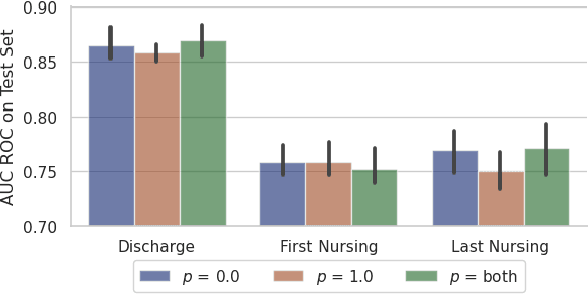
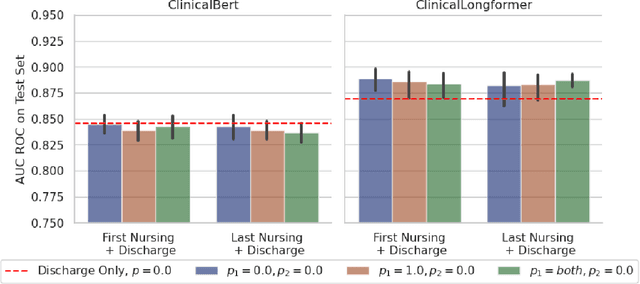
Recent advances in large language models have led to renewed interest in natural language processing in healthcare using the free text of clinical notes. One distinguishing characteristic of clinical notes is their long time span over multiple long documents. The unique structure of clinical notes creates a new design choice: when the context length for a language model predictor is limited, which part of clinical notes should we choose as the input? Existing studies either choose the inputs with domain knowledge or simply truncate them. We propose a framework to analyze the sections with high predictive power. Using MIMIC-III, we show that: 1) predictive power distribution is different between nursing notes and discharge notes and 2) combining different types of notes could improve performance when the context length is large. Our findings suggest that a carefully selected sampling function could enable more efficient information extraction from clinical notes.
* Our code is publicly available on GitHub (https://github.com/nyuolab/EfficientTransformer)
Intent-calibrated Self-training for Answer Selection in Open-domain Dialogues
Jul 13, 2023Answer selection in open-domain dialogues aims to select an accurate answer from candidates. Recent success of answer selection models hinges on training with large amounts of labeled data. However, collecting large-scale labeled data is labor-intensive and time-consuming. In this paper, we introduce the predicted intent labels to calibrate answer labels in a self-training paradigm. Specifically, we propose the intent-calibrated self-training (ICAST) to improve the quality of pseudo answer labels through the intent-calibrated answer selection paradigm, in which we employ pseudo intent labels to help improve pseudo answer labels. We carry out extensive experiments on two benchmark datasets with open-domain dialogues. The experimental results show that ICAST outperforms baselines consistently with 1%, 5% and 10% labeled data. Specifically, it improves 2.06% and 1.00% of F1 score on the two datasets, compared with the strongest baseline with only 5% labeled data.