 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs plantar thermography a valid digital biomarker for characterising diabetic foot ulceration risk?
Jul 05, 2024


Background: In the absence of prospective data on diabetic foot ulcers (DFU), cross-sectional associations with causal risk factors (peripheral neuropathy, and peripheral arterial disease (PAD)) could be used to establish the validity of plantar thermography for DFU risk stratification. Methods: First, we investigated the associations between the intrinsic clusters of plantar thermographic images with several DFU risk factors using an unsupervised deep-learning framework. We then studied associations between obtained thermography clusters and DFU risk factors. Second, to identify those associations with predictive power, we used supervised learning to train Convolutional Neural Network (CNN) regression/classification models that predicted the risk factor based on the thermograph (and visual) input. Findings: Our dataset comprised 282 thermographs from type 2 diabetes mellitus patients (aged 56.31 +- 9.18 years, 51.42 % males). On clustering, we found two overlapping clusters (silhouette score = 0.10, indicating weak separation). There was strong evidence for associations between assigned clusters and several factors related to diabetic foot ulceration such as peripheral neuropathy, PAD, number of diabetes complications, and composite DFU risk prediction scores such as Martins-Mendes, PODUS-2020, and SIGN. However, models predicting said risk factors had poor performances. Interpretation: The strong associations between intrinsic thermography clusters and several DFU risk factors support the validity of using thermography for characterising DFU risk. However, obtained associations did not prove to be predictive, likely due to, spectrum bias, or because thermography and classical risk factors characterise incompletely overlapping portions of the DFU risk construct. Our findings highlight the challenges in standardising ground truths when defining novel digital biomarkers.
The Potential and Pitfalls of using a Large Language Model such as ChatGPT or GPT-4 as a Clinical Assistant
Jul 16, 2023



Recent studies have demonstrated promising performance of ChatGPT and GPT-4 on several medical domain tasks. However, none have assessed its performance using a large-scale real-world electronic health record database, nor have evaluated its utility in providing clinical diagnostic assistance for patients across a full range of disease presentation. We performed two analyses using ChatGPT and GPT-4, one to identify patients with specific medical diagnoses using a real-world large electronic health record database and the other, in providing diagnostic assistance to healthcare workers in the prospective evaluation of hypothetical patients. Our results show that GPT-4 across disease classification tasks with chain of thought and few-shot prompting can achieve performance as high as 96% F1 scores. For patient assessment, GPT-4 can accurately diagnose three out of four times. However, there were mentions of factually incorrect statements, overlooking crucial medical findings, recommendations for unnecessary investigations and overtreatment. These issues coupled with privacy concerns, make these models currently inadequate for real world clinical use. However, limited data and time needed for prompt engineering in comparison to configuration of conventional machine learning workflows highlight their potential for scalability across healthcare applications.
Predicting Model Failure using Saliency Maps in Autonomous Driving Systems
May 19, 2019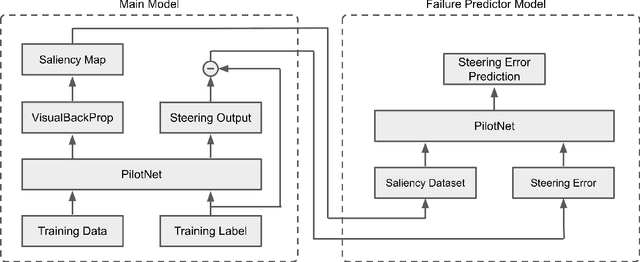
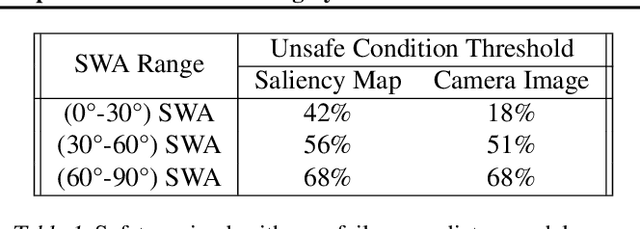
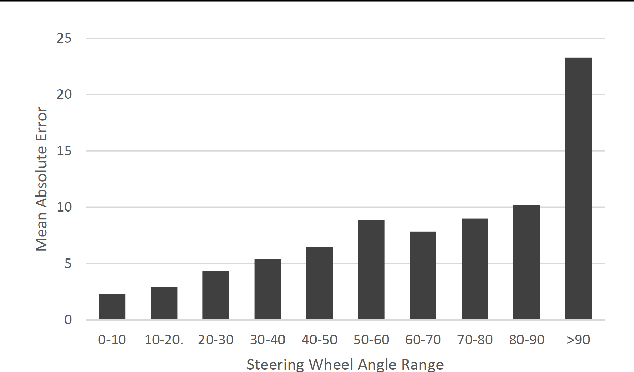

While machine learning systems show high success rate in many complex tasks, research shows they can also fail in very unexpected situations. Rise of machine learning products in safety-critical industries cause an increase in attention in evaluating model robustness and estimating failure probability in machine learning systems. In this work, we propose a design to train a student model -- a failure predictor -- to predict the main model's error for input instances based on their saliency map. We implement and review the preliminary results of our failure predictor model on an autonomous vehicle steering control system as an example of safety-critical applications.