 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEOPose : Exemplar-based object reposing using Generalized Pose Correspondences
May 06, 2025



Reposing objects in images has a myriad of applications, especially for e-commerce where several variants of product images need to be produced quickly. In this work, we leverage the recent advances in unsupervised keypoint correspondence detection between different object images of the same class to propose an end-to-end framework for generic object reposing. Our method, EOPose, takes a target pose-guidance image as input and uses its keypoint correspondence with the source object image to warp and re-render the latter into the target pose using a novel three-step approach. Unlike generative approaches, our method also preserves the fine-grained details of the object such as its exact colors, textures, and brand marks. We also prepare a new dataset of paired objects based on the Objaverse dataset to train and test our network. EOPose produces high-quality reposing output as evidenced by different image quality metrics (PSNR, SSIM and FID). Besides a description of the method and the dataset, the paper also includes detailed ablation and user studies to indicate the efficacy of the proposed method
DoPTA: Improving Document Layout Analysis using Patch-Text Alignment
Dec 17, 2024



The advent of multimodal learning has brought a significant improvement in document AI. Documents are now treated as multimodal entities, incorporating both textual and visual information for downstream analysis. However, works in this space are often focused on the textual aspect, using the visual space as auxiliary information. While some works have explored pure vision based techniques for document image understanding, they require OCR identified text as input during inference, or do not align with text in their learning procedure. Therefore, we present a novel image-text alignment technique specially designed for leveraging the textual information in document images to improve performance on visual tasks. Our document encoder model DoPTA - trained with this technique demonstrates strong performance on a wide range of document image understanding tasks, without requiring OCR during inference. Combined with an auxiliary reconstruction objective, DoPTA consistently outperforms larger models, while using significantly lesser pre-training compute. DoPTA also sets new state-of-the art results on D4LA, and FUNSD, two challenging document visual analysis benchmarks.
LOCATE: Self-supervised Object Discovery via Flow-guided Graph-cut and Bootstrapped Self-training
Aug 22, 2023Learning object segmentation in image and video datasets without human supervision is a challenging problem. Humans easily identify moving salient objects in videos using the gestalt principle of common fate, which suggests that what moves together belongs together. Building upon this idea, we propose a self-supervised object discovery approach that leverages motion and appearance information to produce high-quality object segmentation masks. Specifically, we redesign the traditional graph cut on images to include motion information in a linear combination with appearance information to produce edge weights. Remarkably, this step produces object segmentation masks comparable to the current state-of-the-art on multiple benchmarks. To further improve performance, we bootstrap a segmentation network trained on these preliminary masks as pseudo-ground truths to learn from its own outputs via self-training. We demonstrate the effectiveness of our approach, named LOCATE, on multiple standard video object segmentation, image saliency detection, and object segmentation benchmarks, achieving results on par with and, in many cases surpassing state-of-the-art methods. We also demonstrate the transferability of our approach to novel domains through a qualitative study on in-the-wild images. Additionally, we present extensive ablation analysis to support our design choices and highlight the contribution of each component of our proposed method.
FODVid: Flow-guided Object Discovery in Videos
Jul 10, 2023



Segmentation of objects in a video is challenging due to the nuances such as motion blurring, parallax, occlusions, changes in illumination, etc. Instead of addressing these nuances separately, we focus on building a generalizable solution that avoids overfitting to the individual intricacies. Such a solution would also help us save enormous resources involved in human annotation of video corpora. To solve Video Object Segmentation (VOS) in an unsupervised setting, we propose a new pipeline (FODVid) based on the idea of guiding segmentation outputs using flow-guided graph-cut and temporal consistency. Basically, we design a segmentation model incorporating intra-frame appearance and flow similarities, and inter-frame temporal continuation of the objects under consideration. We perform an extensive experimental analysis of our straightforward methodology on the standard DAVIS16 video benchmark. Though simple, our approach produces results comparable (within a range of ~2 mIoU) to the existing top approaches in unsupervised VOS. The simplicity and effectiveness of our technique opens up new avenues for research in the video domain.
SARC: Soft Actor Retrospective Critic
Jun 28, 2023



The two-time scale nature of SAC, which is an actor-critic algorithm, is characterised by the fact that the critic estimate has not converged for the actor at any given time, but since the critic learns faster than the actor, it ensures eventual consistency between the two. Various strategies have been introduced in literature to learn better gradient estimates to help achieve better convergence. Since gradient estimates depend upon the critic, we posit that improving the critic can provide a better gradient estimate for the actor at each time. Utilizing this, we propose Soft Actor Retrospective Critic (SARC), where we augment the SAC critic loss with another loss term - retrospective loss - leading to faster critic convergence and consequently, better policy gradient estimates for the actor. An existing implementation of SAC can be easily adapted to SARC with minimal modifications. Through extensive experimentation and analysis, we show that SARC provides consistent improvement over SAC on benchmark environments. We plan to open-source the code and all experiment data at: https://github.com/sukritiverma1996/SARC.
Parameter Efficient Local Implicit Image Function Network for Face Segmentation
Mar 27, 2023Face parsing is defined as the per-pixel labeling of images containing human faces. The labels are defined to identify key facial regions like eyes, lips, nose, hair, etc. In this work, we make use of the structural consistency of the human face to propose a lightweight face-parsing method using a Local Implicit Function network, FP-LIIF. We propose a simple architecture having a convolutional encoder and a pixel MLP decoder that uses 1/26th number of parameters compared to the state-of-the-art models and yet matches or outperforms state-of-the-art models on multiple datasets, like CelebAMask-HQ and LaPa. We do not use any pretraining, and compared to other works, our network can also generate segmentation at different resolutions without any changes in the input resolution. This work enables the use of facial segmentation on low-compute or low-bandwidth devices because of its higher FPS and smaller model size.
Towards Estimating Transferability using Hard Subsets
Jan 17, 2023



As transfer learning techniques are increasingly used to transfer knowledge from the source model to the target task, it becomes important to quantify which source models are suitable for a given target task without performing computationally expensive fine tuning. In this work, we propose HASTE (HArd Subset TransfErability), a new strategy to estimate the transferability of a source model to a particular target task using only a harder subset of target data. By leveraging the internal and output representations of model, we introduce two techniques, one class agnostic and another class specific, to identify harder subsets and show that HASTE can be used with any existing transferability metric to improve their reliability. We further analyze the relation between HASTE and the optimal average log likelihood as well as negative conditional entropy and empirically validate our theoretical bounds. Our experimental results across multiple source model architectures, target datasets, and transfer learning tasks show that HASTE modified metrics are consistently better or on par with the state of the art transferability metrics.
One-Shot Doc Snippet Detection: Powering Search in Document Beyond Text
Sep 12, 2022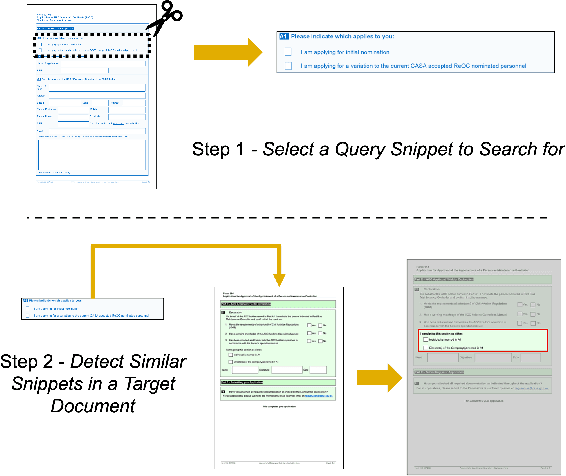


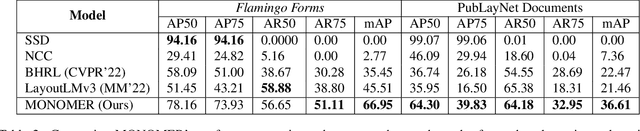
Active consumption of digital documents has yielded scope for research in various applications, including search. Traditionally, searching within a document has been cast as a text matching problem ignoring the rich layout and visual cues commonly present in structured documents, forms, etc. To that end, we ask a mostly unexplored question: "Can we search for other similar snippets present in a target document page given a single query instance of a document snippet?". We propose MONOMER to solve this as a one-shot snippet detection task. MONOMER fuses context from visual, textual, and spatial modalities of snippets and documents to find query snippet in target documents. We conduct extensive ablations and experiments showing MONOMER outperforms several baselines from one-shot object detection (BHRL), template matching, and document understanding (LayoutLMv3). Due to the scarcity of relevant data for the task at hand, we train MONOMER on programmatically generated data having many visually similar query snippets and target document pairs from two datasets - Flamingo Forms and PubLayNet. We also do a human study to validate the generated data.
Video2Skill: Adapting Events in Demonstration Videos to Skills in an Environment using Cyclic MDP Homomorphisms
Sep 09, 2021
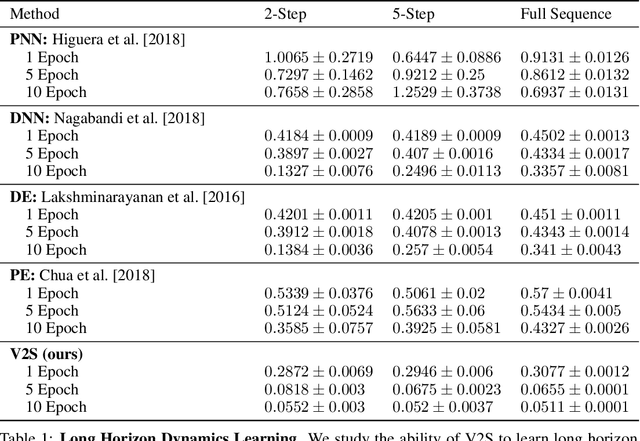
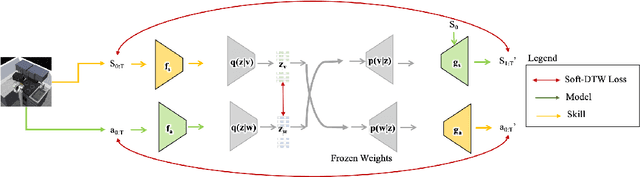
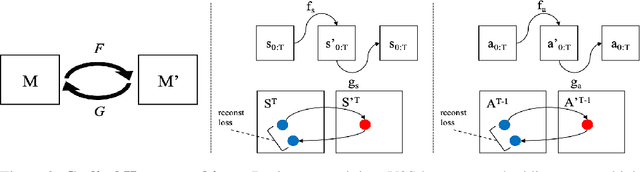
Humans excel at learning long-horizon tasks from demonstrations augmented with textual commentary, as evidenced by the burgeoning popularity of tutorial videos online. Intuitively, this capability can be separated into 2 distinct subtasks - first, dividing a long-horizon demonstration sequence into semantically meaningful events; second, adapting such events into meaningful behaviors in one's own environment. Here, we present Video2Skill (V2S), which attempts to extend this capability to artificial agents by allowing a robot arm to learn from human cooking videos. We first use sequence-to-sequence Auto-Encoder style architectures to learn a temporal latent space for events in long-horizon demonstrations. We then transfer these representations to the robotic target domain, using a small amount of offline and unrelated interaction data (sequences of state-action pairs of the robot arm controlled by an expert) to adapt these events into actionable representations, i.e., skills. Through experiments, we demonstrate that our approach results in self-supervised analogy learning, where the agent learns to draw analogies between motions in human demonstration data and behaviors in the robotic environment. We also demonstrate the efficacy of our approach on model learning - demonstrating how Video2Skill utilizes prior knowledge from human demonstration to outperform traditional model learning of long-horizon dynamics. Finally, we demonstrate the utility of our approach for non-tabula rasa decision-making, i.e, utilizing video demonstration for zero-shot skill generation.
Form2Seq : A Framework for Higher-Order Form Structure Extraction
Jul 09, 2021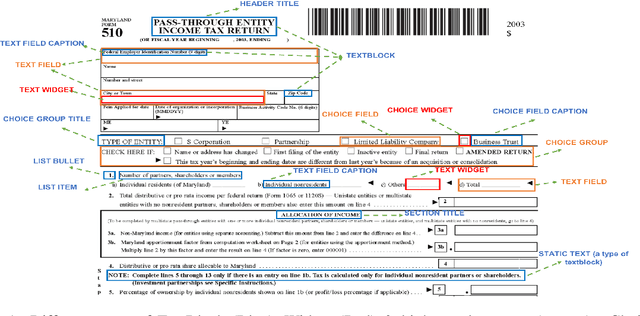
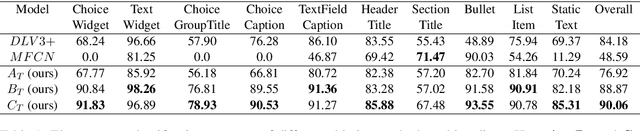
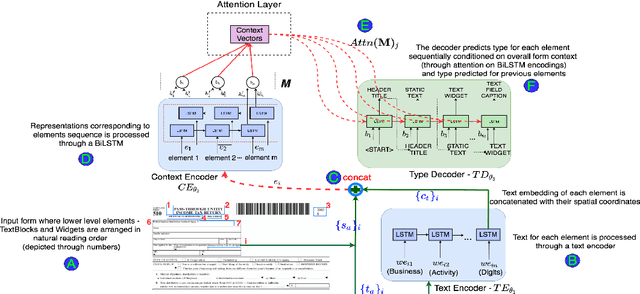
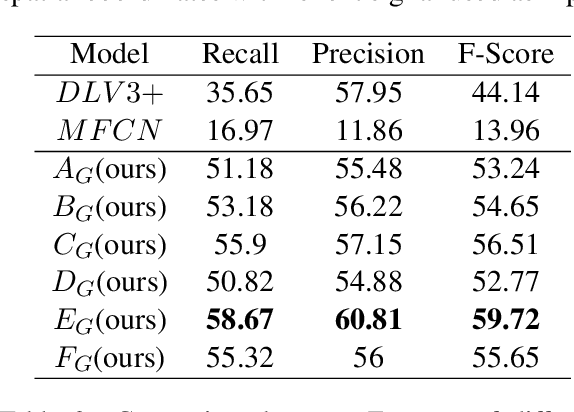
Document structure extraction has been a widely researched area for decades with recent works performing it as a semantic segmentation task over document images using fully-convolution networks. Such methods are limited by image resolution due to which they fail to disambiguate structures in dense regions which appear commonly in forms. To mitigate this, we propose Form2Seq, a novel sequence-to-sequence (Seq2Seq) inspired framework for structure extraction using text, with a specific focus on forms, which leverages relative spatial arrangement of structures. We discuss two tasks; 1) Classification of low-level constituent elements (TextBlock and empty fillable Widget) into ten types such as field captions, list items, and others; 2) Grouping lower-level elements into higher-order constructs, such as Text Fields, ChoiceFields and ChoiceGroups, used as information collection mechanism in forms. To achieve this, we arrange the constituent elements linearly in natural reading order, feed their spatial and textual representations to Seq2Seq framework, which sequentially outputs prediction of each element depending on the final task. We modify Seq2Seq for grouping task and discuss improvements obtained through cascaded end-to-end training of two tasks versus training in isolation. Experimental results show the effectiveness of our text-based approach achieving an accuracy of 90% on classification task and an F1 of 75.82, 86.01, 61.63 on groups discussed above respectively, outperforming segmentation baselines. Further we show our framework achieves state of the results for table structure recognition on ICDAR 2013 dataset.