 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DOMINO: Domain-invariant Hyperdimensional Classification for Multi-Sensor Time Series Data
Aug 18, 2023
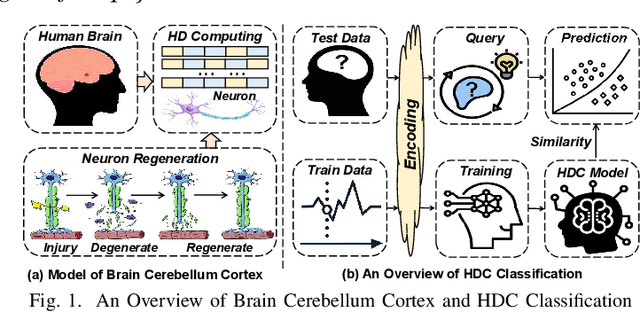
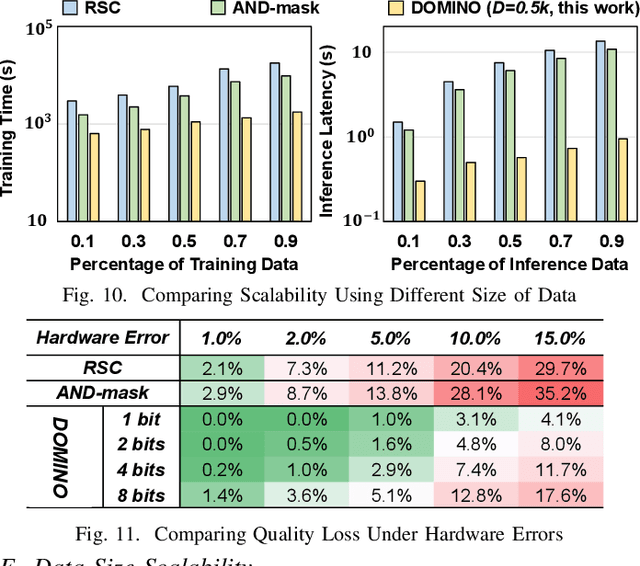
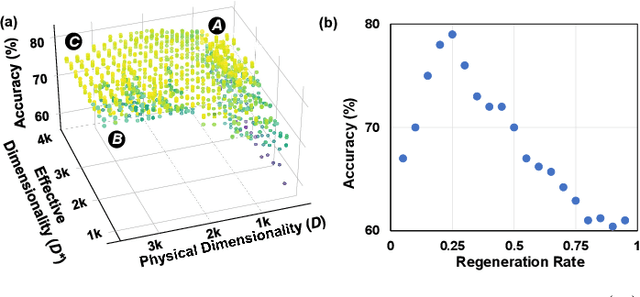
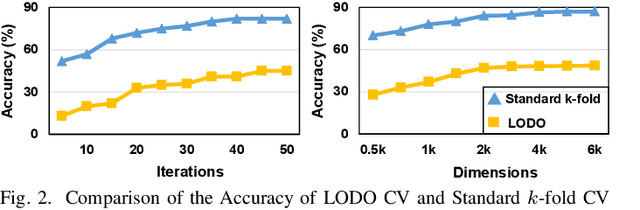
With the rapid evolution of the Internet of Things, many real-world applications utilize heterogeneously connected sensors to capture time-series information. Edge-based machine learning (ML) methodologies are often employed to analyze locally collected data. However, a fundamental issue across data-driven ML approaches is distribution shift. It occurs when a model is deployed on a data distribution different from what it was trained on, and can substantially degrade model performance. Additionally, increasingly sophisticated deep neural networks (DNNs) have been proposed to capture spatial and temporal dependencies in multi-sensor time series data, requiring intensive computational resources beyond the capacity of today's edge devices. While brain-inspired hyperdimensional computing (HDC) has been introduced as a lightweight solution for edge-based learning, existing HDCs are also vulnerable to the distribution shift challenge. In this paper, we propose DOMINO, a novel HDC learning framework addressing the distribution shift problem in noisy multi-sensor time-series data. DOMINO leverages efficient and parallel matrix operations on high-dimensional space to dynamically identify and filter out domain-variant dimensions. Our evaluation on a wide range of multi-sensor time series classification tasks shows that DOMINO achieves on average 2.04% higher accuracy than state-of-the-art (SOTA) DNN-based domain generalization techniques, and delivers 16.34x faster training and 2.89x faster inference. More importantly, DOMINO performs notably better when learning from partially labeled and highly imbalanced data, providing 10.93x higher robustness against hardware noises than SOTA DNNs.
Tree-Planner: Efficient Close-loop Task Planning with Large Language Models
Oct 12, 2023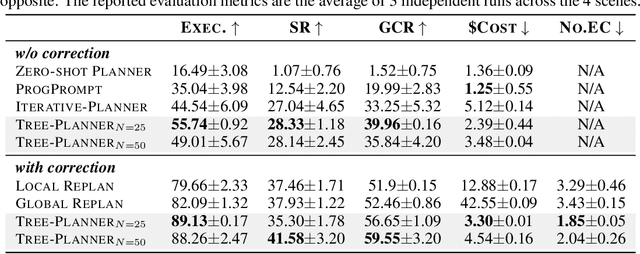
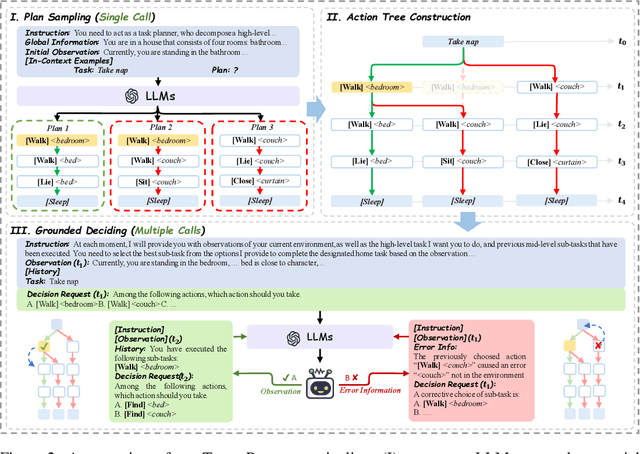
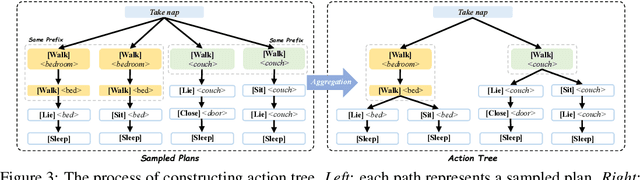

This paper studies close-loop task planning, which refers to the process of generating a sequence of skills (a plan) to accomplish a specific goal while adapting the plan based on real-time observations. Recently, prompting Large Language Models (LLMs) to generate actions iteratively has become a prevalent paradigm due to its superior performance and user-friendliness. However, this paradigm is plagued by two inefficiencies: high token consumption and redundant error correction, both of which hinder its scalability for large-scale testing and applications. To address these issues, we propose Tree-Planner, which reframes task planning with LLMs into three distinct phases: plan sampling, action tree construction, and grounded deciding. Tree-Planner starts by using an LLM to sample a set of potential plans before execution, followed by the aggregation of them to form an action tree. Finally, the LLM performs a top-down decision-making process on the tree, taking into account real-time environmental information. Experiments show that Tree-Planner achieves state-of-the-art performance while maintaining high efficiency. By decomposing LLM queries into a single plan-sampling call and multiple grounded-deciding calls, a considerable part of the prompt are less likely to be repeatedly consumed. As a result, token consumption is reduced by 92.2% compared to the previously best-performing model. Additionally, by enabling backtracking on the action tree as needed, the correction process becomes more flexible, leading to a 40.5% decrease in error corrections. Project page: https://tree-planner.github.io/
Learning Stackable and Skippable LEGO Bricks for Efficient, Reconfigurable, and Variable-Resolution Diffusion Modeling
Oct 10, 2023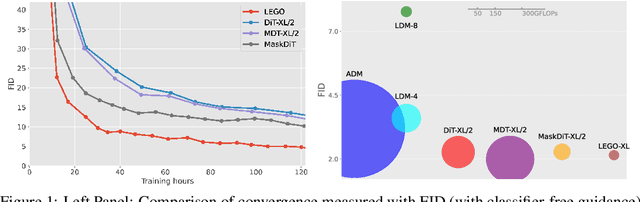


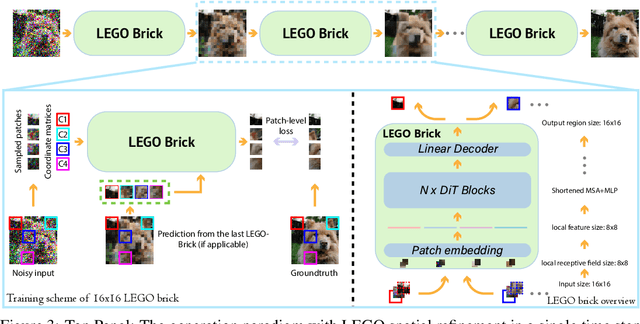
Diffusion models excel at generating photo-realistic images but come with significant computational costs in both training and sampling. While various techniques address these computational challenges, a less-explored issue is designing an efficient and adaptable network backbone for iterative refinement. Current options like U-Net and Vision Transformer often rely on resource-intensive deep networks and lack the flexibility needed for generating images at variable resolutions or with a smaller network than used in training. This study introduces LEGO bricks, which seamlessly integrate Local-feature Enrichment and Global-content Orchestration. These bricks can be stacked to create a test-time reconfigurable diffusion backbone, allowing selective skipping of bricks to reduce sampling costs and generate higher-resolution images than the training data. LEGO bricks enrich local regions with an MLP and transform them using a Transformer block while maintaining a consistent full-resolution image across all bricks. Experimental results demonstrate that LEGO bricks enhance training efficiency, expedite convergence, and facilitate variable-resolution image generation while maintaining strong generative performance. Moreover, LEGO significantly reduces sampling time compared to other methods, establishing it as a valuable enhancement for diffusion models.
Hieros: Hierarchical Imagination on Structured State Space Sequence World Models
Oct 10, 2023One of the biggest challenges to modern deep reinforcement learning (DRL) algorithms is sample efficiency. Many approaches learn a world model in order to train an agent entirely in imagination, eliminating the need for direct environment interaction during training. However, these methods often suffer from either a lack of imagination accuracy, exploration capabilities, or runtime efficiency. We propose Hieros, a hierarchical policy that learns time abstracted world representations and imagines trajectories at multiple time scales in latent space. Hieros uses an S5 layer-based world model, which predicts next world states in parallel during training and iteratively during environment interaction. Due to the special properties of S5 layers, our method can train in parallel and predict next world states iteratively during imagination. This allows for more efficient training than RNN-based world models and more efficient imagination than Transformer-based world models. We show that our approach outperforms the state of the art in terms of mean and median normalized human score on the Atari 100k benchmark, and that our proposed world model is able to predict complex dynamics very accurately. We also show that Hieros displays superior exploration capabilities compared to existing approaches.
Implementation of Fuzzy Control Algorithm in Two-Wheeled Differential Drive Platform
Oct 11, 2023Designing and developing Artificial Intelligence controllers on separately dedicated chips have many advantages. This report reviews the development of a real-time fuzzy logic controller for optimizing locomotion control of a two-wheeled differential drive platform using an Arduino Uno board. Based on the Raspberry Pi board, fuzzy sets are used to optimize color recognition, enabling the color sensor to correctly recognize color at long distances, across a wide range of light intensity, and with high fault tolerance.
A Modified EXP3 and Its Adaptive Variant in Adversarial Bandits with Multi-User Delayed Feedback
Oct 17, 2023For the adversarial multi-armed bandit problem with delayed feedback, we consider that the delayed feedback results are from multiple users and are unrestricted on internal distribution. As the player picks an arm, feedback from multiple users may not be received instantly yet after an arbitrary delay of time which is unknown to the player in advance. For different users in a round, the delays in feedback have no latent correlation. Thus, we formulate an adversarial multi-armed bandit problem with multi-user delayed feedback and design a modified EXP3 algorithm named MUD-EXP3, which makes a decision at each round by considering the importance-weighted estimator of the received feedback from different users. On the premise of known terminal round index $T$, the number of users $M$, the number of arms $N$, and upper bound of delay $d_{max}$, we prove a regret of $\mathcal{O}(\sqrt{TM^2\ln{N}(N\mathrm{e}+4d_{max})})$. Furthermore, for the more common case of unknown $T$, an adaptive algorithm named AMUD-EXP3 is proposed with a sublinear regret with respect to $T$. Finally, extensive experiments are conducted to indicate the correctness and effectiveness of our algorithms.
WaveFlex: A Smart Surface for Private CBRS Wireless Cellular Networks
Oct 17, 2023We present the design and implementation of WaveFlex, the first smart surface that enhances Private LTE/5G networks operating under the shared-license framework in the Citizens Broadband Radio Service frequency band. WaveFlex works in the presence of frequency diversity: multiple nearby base stations operating on different frequencies, as dictated by a Spectrum Access System coordinator. It also handles time dynamism: due to the dynamic sharing rules of the band, base stations occasionally switch channels, especially when priority users enter the network. Finally, WaveFlex operates independently of the network itself, not requiring access to nor modification of the base station or mobile users, yet it remain compliant with and effective on prevailing cellular protocols. We have designed and fabricated WaveFlex on a custom multi-layer PCB, software defined radio-based network monitor, and supporting control software and hardware. Our experimental evaluation benchmarks an operational Private LTE network running at full line rate. Results demonstrate an 8.50 dB average SNR gain, and an average throughput gain of 4.36 Mbps for a single small cell, and 3.19 Mbps for four small cells, in a realistic indoor office scenario.
Towards Operationalizing Social Bonding in Human-Robot Dyads
Oct 17, 2023With momentum increasing in the use of social robots as long-term assistive and collaborative partners, humans developing social bonds with these artificial agents appears to be inevitable. In human-human dyads, social bonding plays a powerful role in regulating behaviours, emotions, and even health. If this is to extend to human-robot dyads, the phenomenology of such relationships (including their emergence and stability) must be better understood. In this paper, we discuss potential approaches towards operationalizing the phenomenon of social bonding between human-robot dyads. We will discuss a number of biobehavioural proxies of social bonding, moving away from existing approaches that use subjective, psychological measures, and instead grounding our approach in some of the evolutionary, neurobiological and physiological correlates of social bond formation in natural systems: (a) reductions in physiological stress (the ''social buffering'' phenomenon), (b) narrowing of spatial proximity between dyads, and (c) inter-dyad behavioural synchrony. We provide relevant evolutionary support for each proposed component, with suggestions and considerations for how they can be recorded in (real-time) human-robot interaction scenarios. With this, we aim to inspire more robust operationalisation of ''social bonding'' between human and artificial (robotic) agents.
Innovative Methods for Non-Destructive Inspection of Handwritten Documents
Oct 17, 2023Handwritten document analysis is an area of forensic science, with the goal of establishing authorship of documents through examination of inherent characteristics. Law enforcement agencies use standard protocols based on manual processing of handwritten documents. This method is time-consuming, is often subjective in its evaluation, and is not replicable. To overcome these limitations, in this paper we present a framework capable of extracting and analyzing intrinsic measures of manuscript documents related to text line heights, space between words, and character sizes using image processing and deep learning techniques. The final feature vector for each document involved consists of the mean and standard deviation for every type of measure collected. By quantifying the Euclidean distance between the feature vectors of the documents to be compared, authorship can be discerned. We also proposed a new and challenging dataset consisting of 362 handwritten manuscripts written on paper and digital devices by 124 different people. Our study pioneered the comparison between traditionally handwritten documents and those produced with digital tools (e.g., tablets). Experimental results demonstrate the ability of our method to objectively determine authorship in different writing media, outperforming the state of the art.
TacticAI: an AI assistant for football tactics
Oct 17, 2023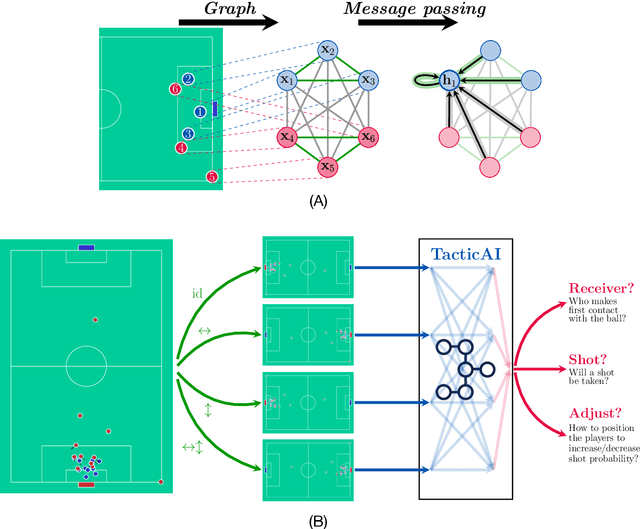
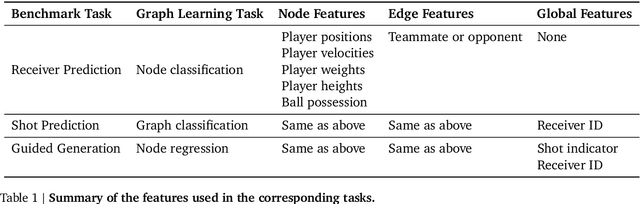
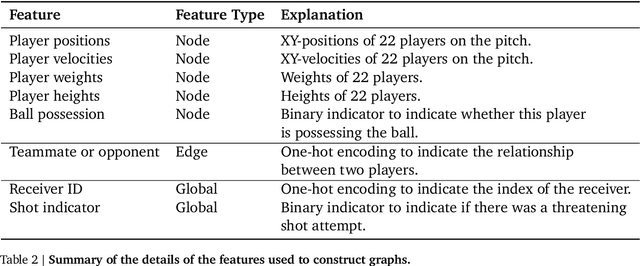
Identifying key patterns of tactics implemented by rival teams, and developing effective responses, lies at the heart of modern football. However, doing so algorithmically remains an open research challenge. To address this unmet need, we propose TacticAI, an AI football tactics assistant developed and evaluated in close collaboration with domain experts from Liverpool FC. We focus on analysing corner kicks, as they offer coaches the most direct opportunities for interventions and improvements. TacticAI incorporates both a predictive and a generative component, allowing the coaches to effectively sample and explore alternative player setups for each corner kick routine and to select those with the highest predicted likelihood of success. We validate TacticAI on a number of relevant benchmark tasks: predicting receivers and shot attempts and recommending player position adjustments. The utility of TacticAI is validated by a qualitative study conducted with football domain experts at Liverpool FC. We show that TacticAI's model suggestions are not only indistinguishable from real tactics, but also favoured over existing tactics 90% of the time, and that TacticAI offers an effective corner kick retrieval system. TacticAI achieves these results despite the limited availability of gold-standard data, achieving data efficiency through geometric deep learning.