 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Evaluation of General Agents: Problem Definition and Comparison of Baseline Algorithms
Jan 12, 2026As intelligent agents become more generally-capable, i.e. able to master a wide variety of tasks, the complexity and cost of properly evaluating them rises significantly. Tasks that assess specific capabilities of the agents can be correlated and stochastic, requiring many samples for accurate comparisons, leading to added costs. In this paper, we propose a formal definition and a conceptual framework for active evaluation of agents across multiple tasks, which assesses the performance of ranking algorithms as a function of number of evaluation data samples. Rather than curating, filtering, or compressing existing data sets as a preprocessing step, we propose an online framing: on every iteration, the ranking algorithm chooses the task and agents to sample scores from. Then, evaluation algorithms report a ranking of agents on each iteration and their performance is assessed with respect to the ground truth ranking over time. Several baselines are compared under different experimental contexts, with synthetic generated data and simulated online access to real evaluation data from Atari game-playing agents. We find that the classical Elo rating system -- while it suffers from well-known failure modes, in theory -- is a consistently reliable choice for efficient reduction of ranking error in practice. A recently-proposed method, Soft Condorcet Optimization, shows comparable performance to Elo on synthetic data and significantly outperforms Elo on real Atari agent evaluation. When task variation from the ground truth is high, selecting tasks based on proportional representation leads to higher rate of ranking error reduction.
Soft Condorcet Optimization for Ranking of General Agents
Nov 04, 2024



A common way to drive progress of AI models and agents is to compare their performance on standardized benchmarks. Comparing the performance of general agents requires aggregating their individual performances across a potentially wide variety of different tasks. In this paper, we describe a novel ranking scheme inspired by social choice frameworks, called Soft Condorcet Optimization (SCO), to compute the optimal ranking of agents: the one that makes the fewest mistakes in predicting the agent comparisons in the evaluation data. This optimal ranking is the maximum likelihood estimate when evaluation data (which we view as votes) are interpreted as noisy samples from a ground truth ranking, a solution to Condorcet's original voting system criteria. SCO ratings are maximal for Condorcet winners when they exist, which we show is not necessarily true for the classical rating system Elo. We propose three optimization algorithms to compute SCO ratings and evaluate their empirical performance. When serving as an approximation to the Kemeny-Young voting method, SCO rankings are on average 0 to 0.043 away from the optimal ranking in normalized Kendall-tau distance across 865 preference profiles from the PrefLib open ranking archive. In a simulated noisy tournament setting, SCO achieves accurate approximations to the ground truth ranking and the best among several baselines when 59\% or more of the preference data is missing. Finally, SCO ranking provides the best approximation to the optimal ranking, measured on held-out test sets, in a problem containing 52,958 human players across 31,049 games of the classic seven-player game of Diplomacy.
TacticAI: an AI assistant for football tactics
Oct 17, 2023Identifying key patterns of tactics implemented by rival teams, and developing effective responses, lies at the heart of modern football. However, doing so algorithmically remains an open research challenge. To address this unmet need, we propose TacticAI, an AI football tactics assistant developed and evaluated in close collaboration with domain experts from Liverpool FC. We focus on analysing corner kicks, as they offer coaches the most direct opportunities for interventions and improvements. TacticAI incorporates both a predictive and a generative component, allowing the coaches to effectively sample and explore alternative player setups for each corner kick routine and to select those with the highest predicted likelihood of success. We validate TacticAI on a number of relevant benchmark tasks: predicting receivers and shot attempts and recommending player position adjustments. The utility of TacticAI is validated by a qualitative study conducted with football domain experts at Liverpool FC. We show that TacticAI's model suggestions are not only indistinguishable from real tactics, but also favoured over existing tactics 90% of the time, and that TacticAI offers an effective corner kick retrieval system. TacticAI achieves these results despite the limited availability of gold-standard data, achieving data efficiency through geometric deep learning.
BRExIt: On Opponent Modelling in Expert Iteration
May 31, 2022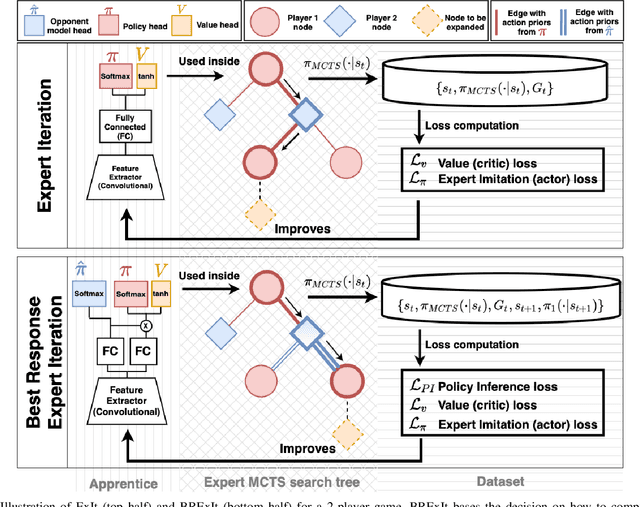
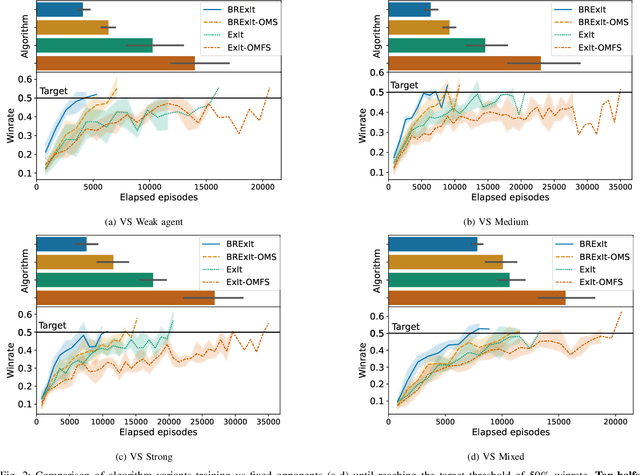
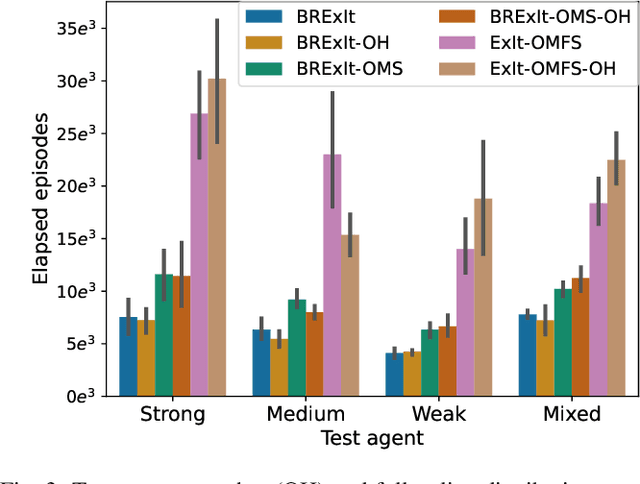
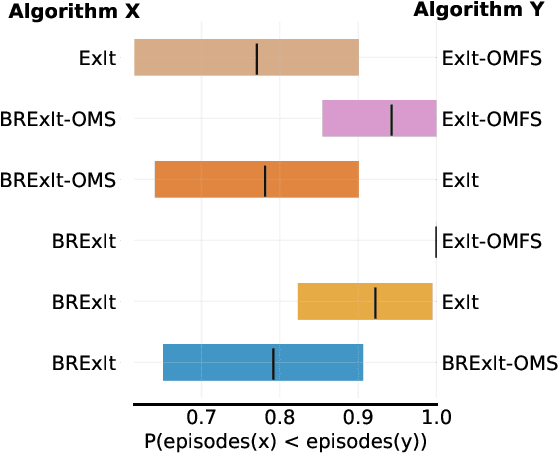
Finding a best response policy is a central objective in game theory and multi-agent learning, with modern population-based training approaches employing reinforcement learning algorithms as best-response oracles to improve play against candidate opponents (typically previously learnt policies). We propose Best Response Expert Iteration (BRExIt), which accelerates learning in games by incorporating opponent models into the state-of-the-art learning algorithm Expert Iteration (ExIt). BRExIt aims to (1) improve feature shaping in the apprentice, with a policy head predicting opponent policies as an auxiliary task, and (2) bias opponent moves in planning towards the given or learnt opponent model, to generate apprentice targets that better approximate a best response. In an empirical ablation on BRExIt's algorithmic variants in the game Connect4 against a set of fixed test agents, we provide statistical evidence that BRExIt learns well-performing policies with greater sample efficiency than ExIt.
Online Planning in POMDPs with Self-Improving Simulators
Jan 27, 2022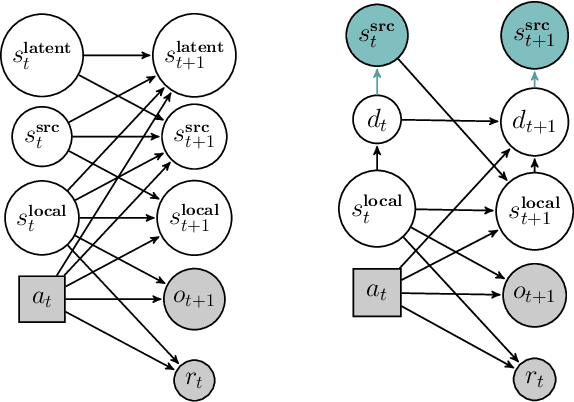

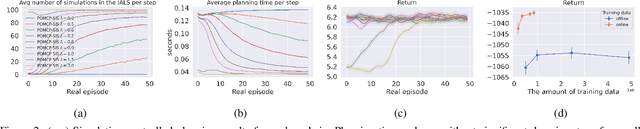

How can we plan efficiently in a large and complex environment when the time budget is limited? Given the original simulator of the environment, which may be computationally very demanding, we propose to learn online an approximate but much faster simulator that improves over time. To plan reliably and efficiently while the approximate simulator is learning, we develop a method that adaptively decides which simulator to use for every simulation, based on a statistic that measures the accuracy of the approximate simulator. This allows us to use the approximate simulator to replace the original simulator for faster simulations when it is accurate enough under the current context, thus trading off simulation speed and accuracy. Experimental results in two large domains show that when integrated with POMCP, our approach allows to plan with improving efficiency over time.
Automated Peer-to-peer Negotiation for Energy Contract Settlements in Residential Cooperatives
Nov 26, 2019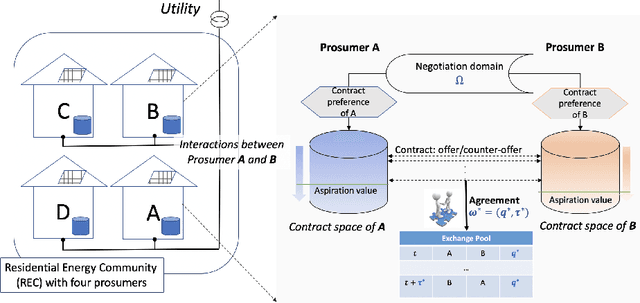

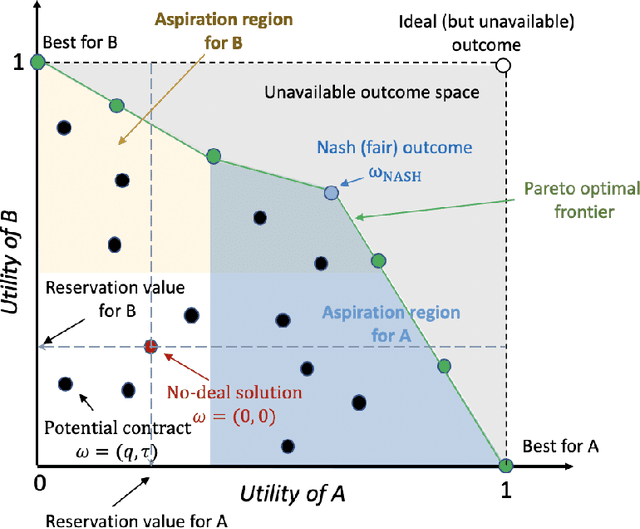

This paper presents an automated peer-to-peer negotiation strategy for settling energy contracts among prosumers in a Residential Energy Cooperative considering heterogeneity prosumer preferences. The heterogeneity arises from prosumers' evaluation of energy contracts through multiple societal and environmental criteria and the prosumers' private preferences over those criteria. The prosumers engage in bilateral negotiations with peers to mutually agree on periodical energy contracts/loans consisting of the energy volume to be exchanged at that period and the return time of the exchanged energy. The negotiating prosumers navigate through a common negotiation domain consisting of potential energy contracts and evaluate those contracts from their valuations on the entailed criteria against a utility function that is robust against generation and demand uncertainty. From the repeated interactions, a prosumer gradually learns about the compatibility of its peers in reaching energy contracts that are closer to Nash solutions. Empirical evaluation on real demand, generation and storage profiles -- in multiple system scales -- illustrates that the proposed negotiation based strategy can increase the system efficiency (measured by utilitarian social welfare) and fairness (measured by Nash social welfare) over a baseline strategy and an individual flexibility control strategy representing the status quo strategy. We thus elicit system benefits from peer-to-peer flexibility exchange already without any central coordination and market operator, providing a simple yet flexible and effective paradigm that complements existing markets.
Robust temporal difference learning for critical domains
Jan 23, 2019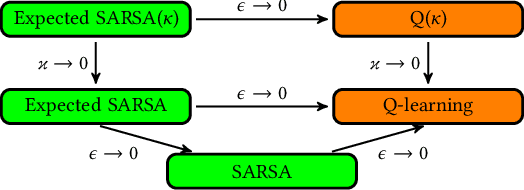

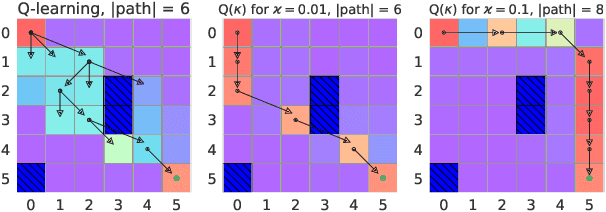
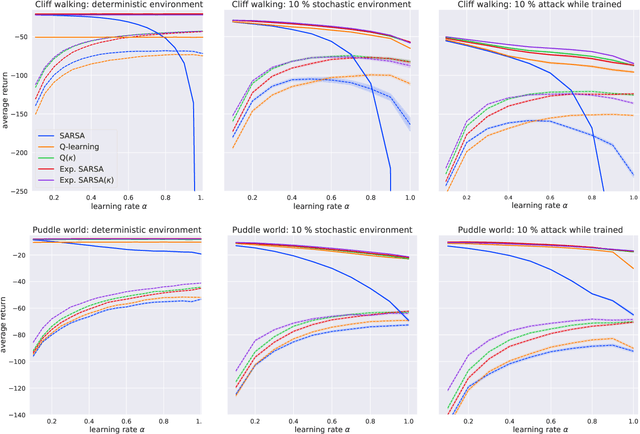
We present a new Q-function operator for temporal difference (TD) learning methods that explicitly encodes robustness against significant rare events (SRE) in critical domains. The operator, which we call the $\kappa$-operator, allows to learn a safe policy in a model-based fashion without actually observing the SRE. We introduce single- and multi-agent robust TD methods using the operator $\kappa$. We prove convergence of the operator to the optimal safe Q-function with respect to the model using the theory of Generalized Markov Decision Processes. In addition we prove convergence to the optimal Q-function of the original MDP given that the probability of SREs vanishes. Empirical evaluations demonstrate the superior performance of $\kappa$-based TD methods both in the early learning phase as well as in the final converged stage. In addition we show robustness of the proposed method to small model errors, as well as its applicability in a multi-agent context.
A Survey of Learning in Multiagent Environments: Dealing with Non-Stationarity
Jul 28, 2017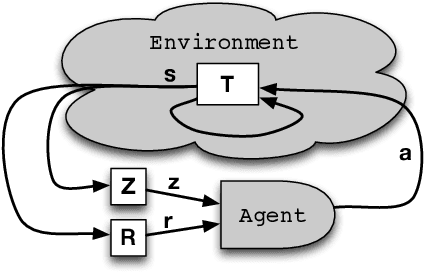
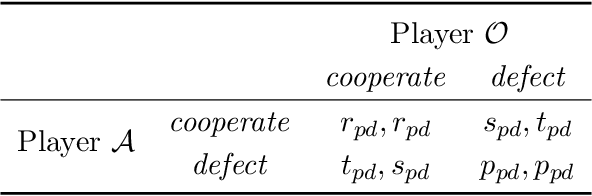
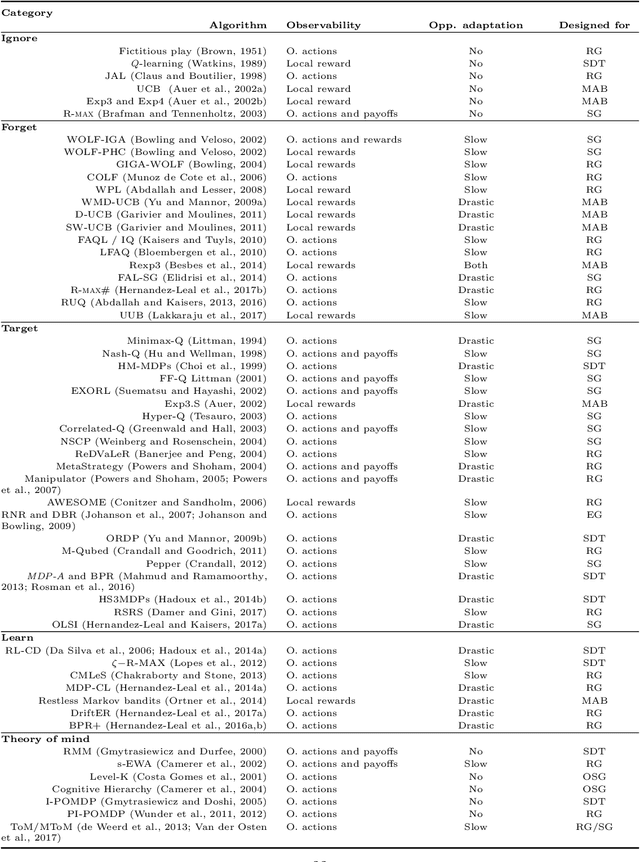
The key challenge in multiagent learning is learning a best response to the behaviour of other agents, which may be non-stationary: if the other agents adapt their strategy as well, the learning target moves. Disparate streams of research have approached non-stationarity from several angles, which make a variety of implicit assumptions that make it hard to keep an overview of the state of the art and to validate the innovation and significance of new works. This survey presents a coherent overview of work that addresses opponent-induced non-stationarity with tools from game theory, reinforcement learning and multi-armed bandits. Further, we reflect on the principle approaches how algorithms model and cope with this non-stationarity, arriving at a new framework and five categories (in increasing order of sophistication): ignore, forget, respond to target models, learn models, and theory of mind. A wide range of state-of-the-art algorithms is classified into a taxonomy, using these categories and key characteristics of the environment (e.g., observability) and adaptation behaviour of the opponents (e.g., smooth, abrupt). To clarify even further we present illustrative variations of one domain, contrasting the strengths and limitations of each category. Finally, we discuss in which environments the different approaches yield most merit, and point to promising avenues of future research.