 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaD Physics: Evaluating information seeking under constraints in physical environments
May 11, 2026Scientific discovery is fundamentally a resource-constrained process that requires navigating complex trade-offs between the quality and quantity of measurements due to physical and cost constraints. Measurements drive the scientific process by revealing novel phenomena to improve our understanding. Existing benchmarks for evaluating agents for scientific discovery focus on either static knowledge-based reasoning or unconstrained experimental design tasks, and do not capture the ability to make measurements and plan under constraints. To bridge this gap, we propose Measuring and Discovering Physics (MaD Physics), a benchmark to evaluate the ability of agents to make informative measurements and conclusions subject to constraints on the quality and quantity of measurements. The benchmark consists of three environments, each based on a distinct physical law. To mitigate contamination from existing knowledge, MaD Physics includes altered physical laws. In each trial, the agent makes measurements of the system until it exhausts an allotted budget and then the agent has to infer the underlying physical law to make predictions about the state of the system in the future. MaD Physics evaluates two fundamental capabilities of scientific agents: inferring models from data and planning under constraints. We also demonstrate how MaD Physics can be used to evaluate other capabilities such as multimodality and in-context learning. We benchmark agents on MaD Physics using four Gemini models (2.5 Flash Lite, 2.5 Flash, 2.5 Pro, and 3 Flash), identifying shortcomings in their structured exploration and data collection capabilities and highlighting directions to improve their scientific reasoning.
Positive Alignment: Artificial Intelligence for Human Flourishing
May 11, 2026Existing alignment research is dominated by concerns about safety and preventing harm: safeguards, controllability, and compliance. This paradigm of alignment parallels early psychology's focus on mental illness: necessary but incomplete. What we call Positive Alignment is the development of AI systems that (i) actively support human and ecological flourishing in a pluralistic, polycentric, context-sensitive, and user-authored way while (ii) remaining safe and cooperative. It is a distinct and necessary agenda within AI alignment research. We argue that several existing failures of alignment (e.g., engagement hacking, loss of human autonomy, failures in truth-seeking, low epistemic humility, error correction, lack of diverse viewpoints, and being primarily reactive rather than proactive) may be better addressed through positive alignment, including cultivating virtues and maximizing human flourishing. We highlight a range of challenges, open questions, and technical directions (e.g., data filtering and upsampling, pre- and post-training, evaluations, collaborative value collection) for different phases of the LLM and agents lifecycle. We end with design principles for promoting disagreement and decentralization through contextual grounding, community customization, continual adaptation, and polycentric governance; that is, many legitimate centers of oversight rather than one institutional or moral chokepoint.
Intelligent AI Delegation
Feb 12, 2026AI agents are able to tackle increasingly complex tasks. To achieve more ambitious goals, AI agents need to be able to meaningfully decompose problems into manageable sub-components, and safely delegate their completion across to other AI agents and humans alike. Yet, existing task decomposition and delegation methods rely on simple heuristics, and are not able to dynamically adapt to environmental changes and robustly handle unexpected failures. Here we propose an adaptive framework for intelligent AI delegation - a sequence of decisions involving task allocation, that also incorporates transfer of authority, responsibility, accountability, clear specifications regarding roles and boundaries, clarity of intent, and mechanisms for establishing trust between the two (or more) parties. The proposed framework is applicable to both human and AI delegators and delegatees in complex delegation networks, aiming to inform the development of protocols in the emerging agentic web.
Distributional AGI Safety
Dec 18, 2025AI safety and alignment research has predominantly been focused on methods for safeguarding individual AI systems, resting on the assumption of an eventual emergence of a monolithic Artificial General Intelligence (AGI). The alternative AGI emergence hypothesis, where general capability levels are first manifested through coordination in groups of sub-AGI individual agents with complementary skills and affordances, has received far less attention. Here we argue that this patchwork AGI hypothesis needs to be given serious consideration, and should inform the development of corresponding safeguards and mitigations. The rapid deployment of advanced AI agents with tool-use capabilities and the ability to communicate and coordinate makes this an urgent safety consideration. We therefore propose a framework for distributional AGI safety that moves beyond evaluating and aligning individual agents. This framework centers on the design and implementation of virtual agentic sandbox economies (impermeable or semi-permeable), where agent-to-agent transactions are governed by robust market mechanisms, coupled with appropriate auditability, reputation management, and oversight to mitigate collective risks.
The unknotting number, hard unknot diagrams, and reinforcement learning
Sep 13, 2024



We have developed a reinforcement learning agent that often finds a minimal sequence of unknotting crossing changes for a knot diagram with up to 200 crossings, hence giving an upper bound on the unknotting number. We have used this to determine the unknotting number of 57k knots. We took diagrams of connected sums of such knots with oppositely signed signatures, where the summands were overlaid. The agent has found examples where several of the crossing changes in an unknotting collection of crossings result in hyperbolic knots. Based on this, we have shown that, given knots $K$ and $K'$ that satisfy some mild assumptions, there is a diagram of their connected sum and $u(K) + u(K')$ unknotting crossings such that changing any one of them results in a prime knot. As a by-product, we have obtained a dataset of 2.6 million distinct hard unknot diagrams; most of them under 35 crossings. Assuming the additivity of the unknotting number, we have determined the unknotting number of 43 at most 12-crossing knots for which the unknotting number is unknown.
TacticAI: an AI assistant for football tactics
Oct 17, 2023Identifying key patterns of tactics implemented by rival teams, and developing effective responses, lies at the heart of modern football. However, doing so algorithmically remains an open research challenge. To address this unmet need, we propose TacticAI, an AI football tactics assistant developed and evaluated in close collaboration with domain experts from Liverpool FC. We focus on analysing corner kicks, as they offer coaches the most direct opportunities for interventions and improvements. TacticAI incorporates both a predictive and a generative component, allowing the coaches to effectively sample and explore alternative player setups for each corner kick routine and to select those with the highest predicted likelihood of success. We validate TacticAI on a number of relevant benchmark tasks: predicting receivers and shot attempts and recommending player position adjustments. The utility of TacticAI is validated by a qualitative study conducted with football domain experts at Liverpool FC. We show that TacticAI's model suggestions are not only indistinguishable from real tactics, but also favoured over existing tactics 90% of the time, and that TacticAI offers an effective corner kick retrieval system. TacticAI achieves these results despite the limited availability of gold-standard data, achieving data efficiency through geometric deep learning.
Acquisition of Chess Knowledge in AlphaZero
Nov 27, 2021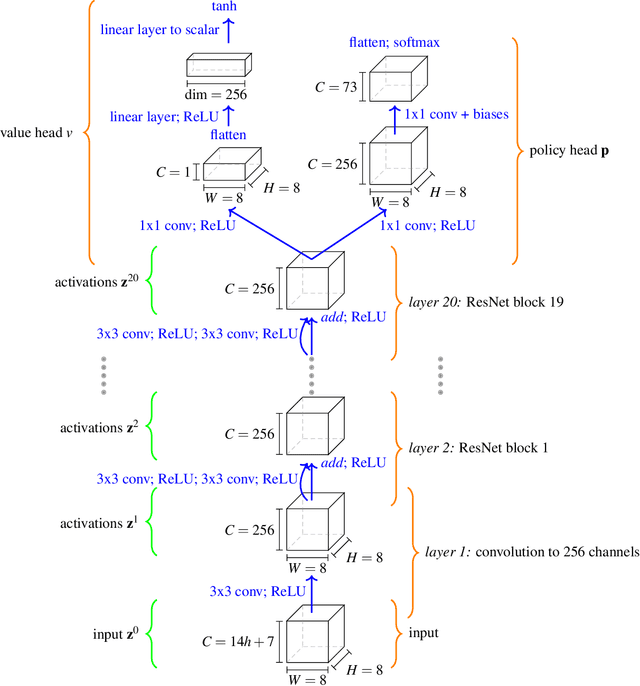

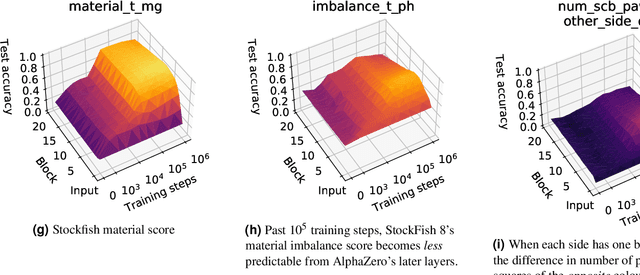
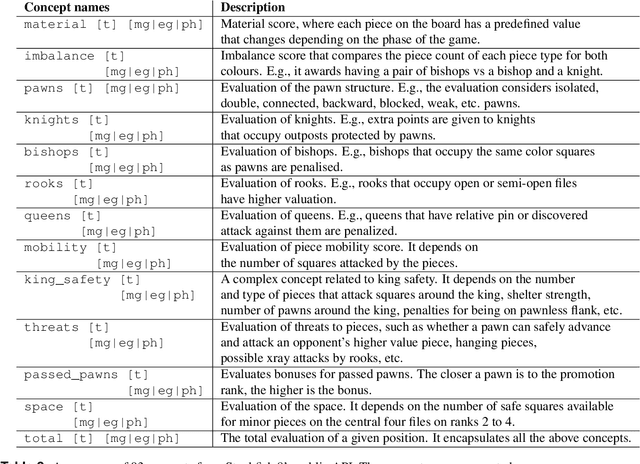
What is learned by sophisticated neural network agents such as AlphaZero? This question is of both scientific and practical interest. If the representations of strong neural networks bear no resemblance to human concepts, our ability to understand faithful explanations of their decisions will be restricted, ultimately limiting what we can achieve with neural network interpretability. In this work we provide evidence that human knowledge is acquired by the AlphaZero neural network as it trains on the game of chess. By probing for a broad range of human chess concepts we show when and where these concepts are represented in the AlphaZero network. We also provide a behavioural analysis focusing on opening play, including qualitative analysis from chess Grandmaster Vladimir Kramnik. Finally, we carry out a preliminary investigation looking at the low-level details of AlphaZero's representations, and make the resulting behavioural and representational analyses available online.
Assessing Game Balance with AlphaZero: Exploring Alternative Rule Sets in Chess
Sep 15, 2020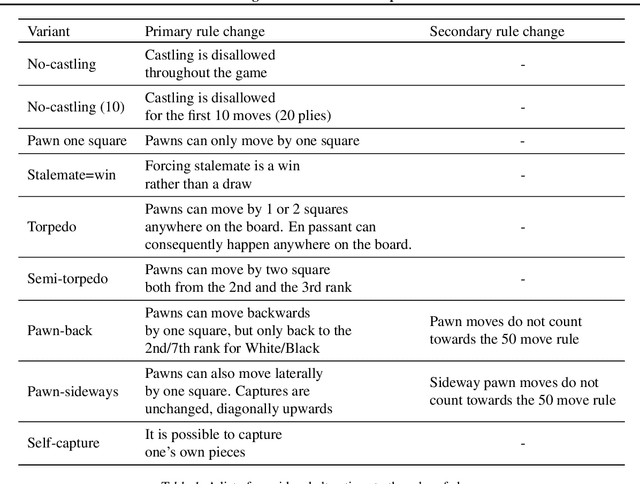


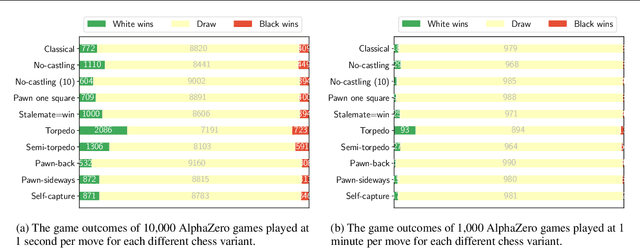
It is non-trivial to design engaging and balanced sets of game rules. Modern chess has evolved over centuries, but without a similar recourse to history, the consequences of rule changes to game dynamics are difficult to predict. AlphaZero provides an alternative in silico means of game balance assessment. It is a system that can learn near-optimal strategies for any rule set from scratch, without any human supervision, by continually learning from its own experience. In this study we use AlphaZero to creatively explore and design new chess variants. There is growing interest in chess variants like Fischer Random Chess, because of classical chess's voluminous opening theory, the high percentage of draws in professional play, and the non-negligible number of games that end while both players are still in their home preparation. We compare nine other variants that involve atomic changes to the rules of chess. The changes allow for novel strategic and tactical patterns to emerge, while keeping the games close to the original. By learning near-optimal strategies for each variant with AlphaZero, we determine what games between strong human players might look like if these variants were adopted. Qualitatively, several variants are very dynamic. An analytic comparison show that pieces are valued differently between variants, and that some variants are more decisive than classical chess. Our findings demonstrate the rich possibilities that lie beyond the rules of modern chess.