 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
An Empirical Study on Fertility Proposals Using Multi-Grained Topic Analysis Methods
Jul 22, 2023
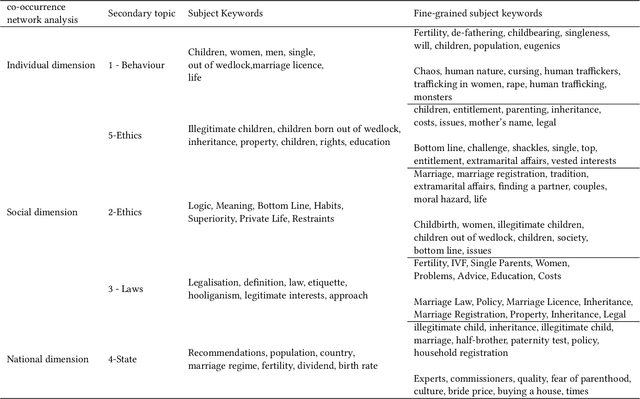
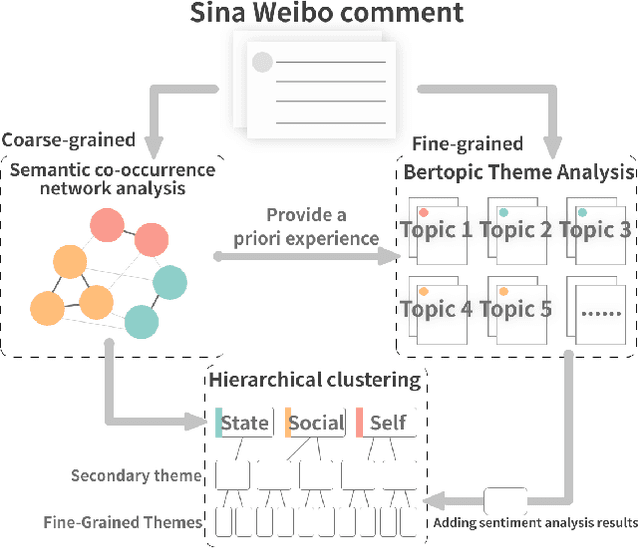
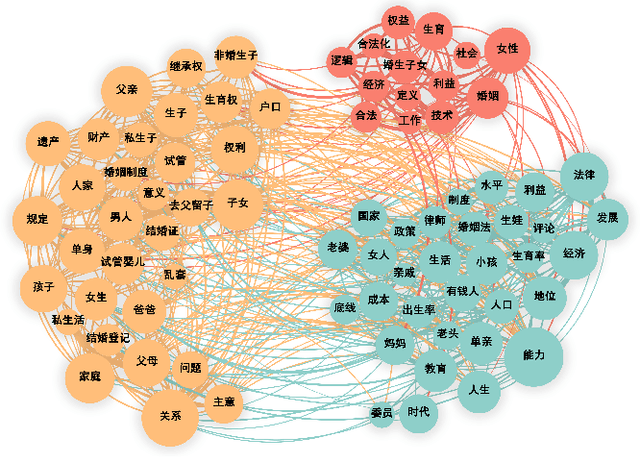
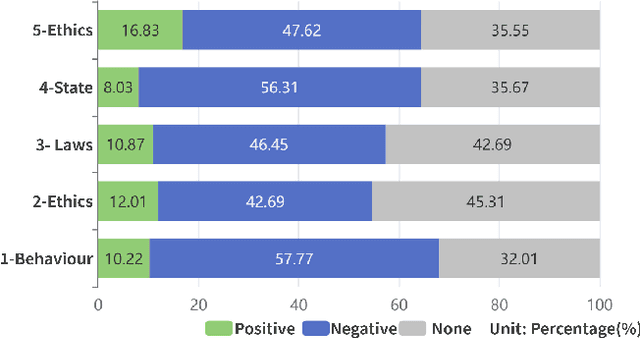
Fertility issues are closely related to population security, in 60 years China's population for the first time in a negative growth trend, the change of fertility policy is of great concern to the community. 2023 "two sessions" proposal "suggests that the country in the form of legislation, the birth of the registration of the cancellation of the marriage restriction" This topic was once a hot topic on the Internet, and "unbundling" the relationship between birth registration and marriage has become the focus of social debate. In this paper, we adopt co-occurrence semantic analysis, topic analysis and sentiment analysis to conduct multi-granularity semantic analysis of microblog comments. It is found that the discussion on the proposal of "removing marriage restrictions from birth registration" involves the individual, society and the state at three dimensions, and is detailed into social issues such as personal behaviour, social ethics and law, and national policy, with people's sentiment inclined to be negative in most of the topics. Based on this, eight proposals were made to provide a reference for governmental decision making and to form a reference method for researching public opinion on political issues.
Painsight: An Extendable Opinion Mining Framework for Detecting Pain Points Based on Online Customer Reviews
Jun 03, 2023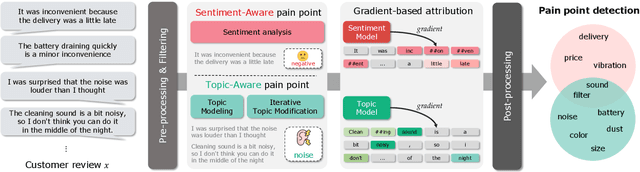
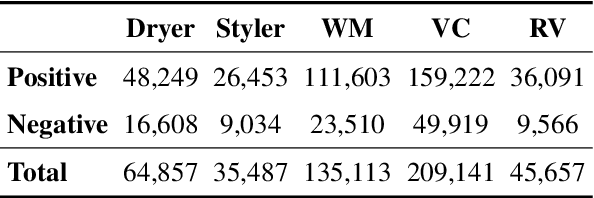
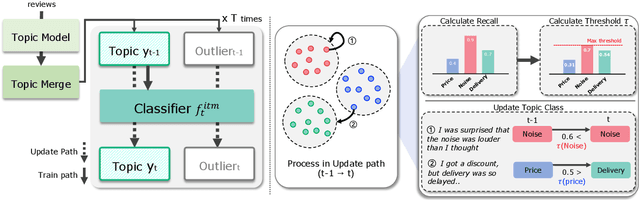
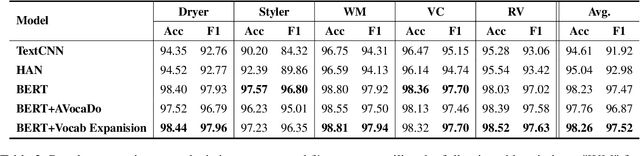
As the e-commerce market continues to expand and online transactions proliferate, customer reviews have emerged as a critical element in shaping the purchasing decisions of prospective buyers. Previous studies have endeavored to identify key aspects of customer reviews through the development of sentiment analysis models and topic models. However, extracting specific dissatisfaction factors remains a challenging task. In this study, we delineate the pain point detection problem and propose Painsight, an unsupervised framework for automatically extracting distinct dissatisfaction factors from customer reviews without relying on ground truth labels. Painsight employs pre-trained language models to construct sentiment analysis and topic models, leveraging attribution scores derived from model gradients to extract dissatisfaction factors. Upon application of the proposed methodology to customer review data spanning five product categories, we successfully identified and categorized dissatisfaction factors within each group, as well as isolated factors for each type. Notably, Painsight outperformed benchmark methods, achieving substantial performance enhancements and exceptional results in human evaluations.
A Knowledge-Enhanced Adversarial Model for Cross-lingual Structured Sentiment Analysis
May 31, 2022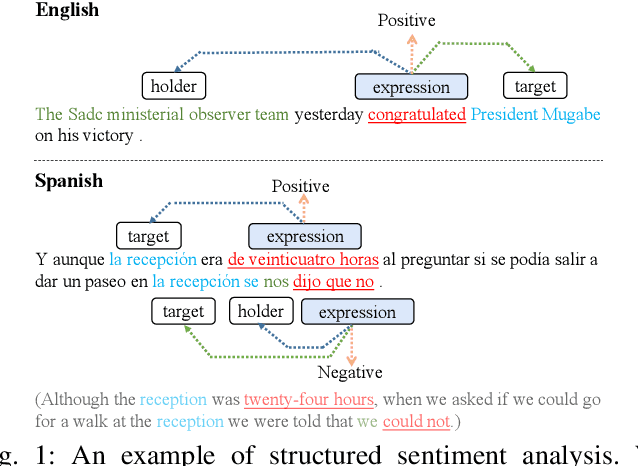
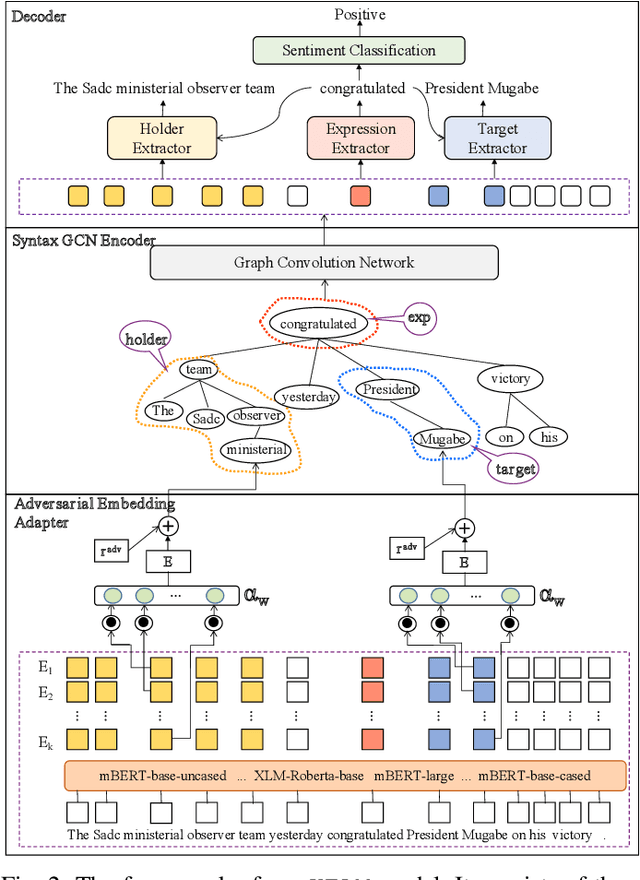
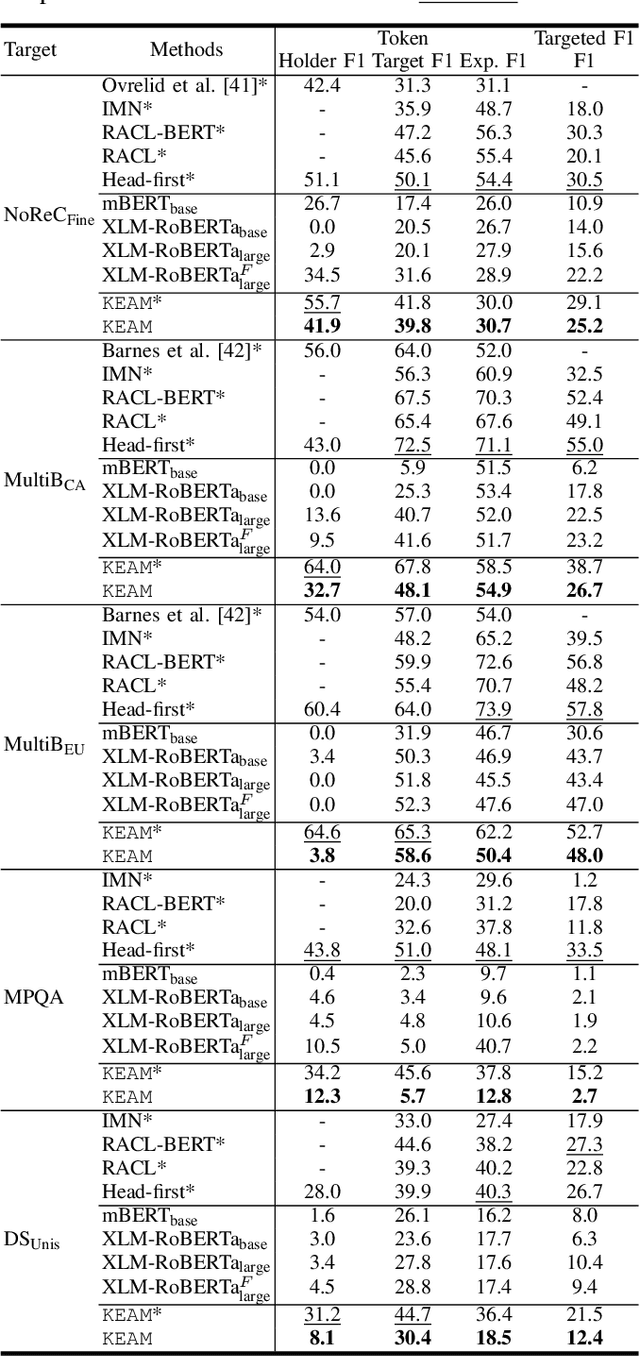
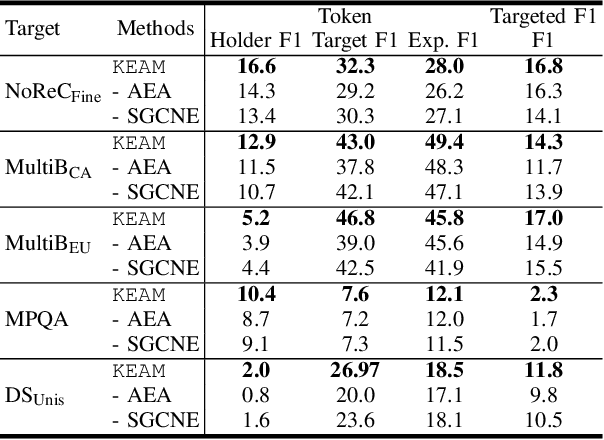
Structured sentiment analysis, which aims to extract the complex semantic structures such as holders, expressions, targets, and polarities, has obtained widespread attention from both industry and academia. Unfortunately, the existing structured sentiment analysis datasets refer to a few languages and are relatively small, limiting neural network models' performance. In this paper, we focus on the cross-lingual structured sentiment analysis task, which aims to transfer the knowledge from the source language to the target one. Notably, we propose a Knowledge-Enhanced Adversarial Model (\texttt{KEAM}) with both implicit distributed and explicit structural knowledge to enhance the cross-lingual transfer. First, we design an adversarial embedding adapter for learning an informative and robust representation by capturing implicit semantic information from diverse multi-lingual embeddings adaptively. Then, we propose a syntax GCN encoder to transfer the explicit semantic information (e.g., universal dependency tree) among multiple languages. We conduct experiments on five datasets and compare \texttt{KEAM} with both the supervised and unsupervised methods. The extensive experimental results show that our \texttt{KEAM} model outperforms all the unsupervised baselines in various metrics.
Sentiment Analysis of Covid-related Reddits
May 13, 2022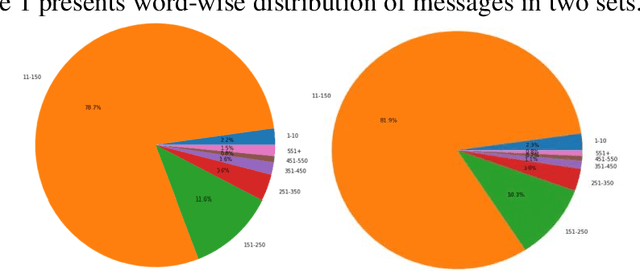
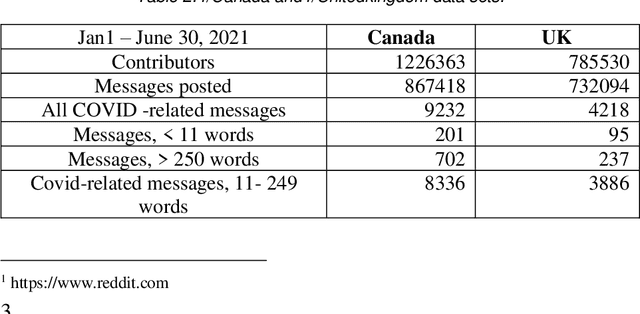
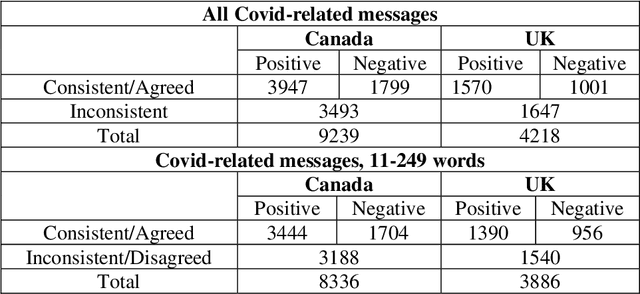
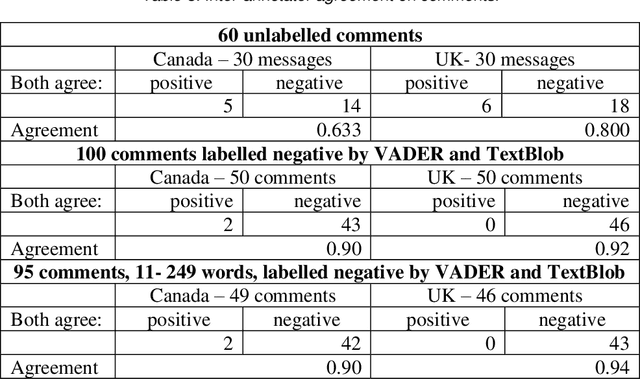
This paper focuses on Sentiment Analysis of Covid-19 related messages from the r/Canada and r/Unitedkingdom subreddits of Reddit. We apply manual annotation and three Machine Learning algorithms to analyze sentiments conveyed in those messages. We use VADER and TextBlob to label messages for Machine Learning experiments. Our results show that removal of shortest and longest messages improves VADER and TextBlob agreement on positive sentiments and F-score of sentiment classification by all the three algorithms
Reasoning Implicit Sentiment with Chain-of-Thought Prompting
May 25, 2023
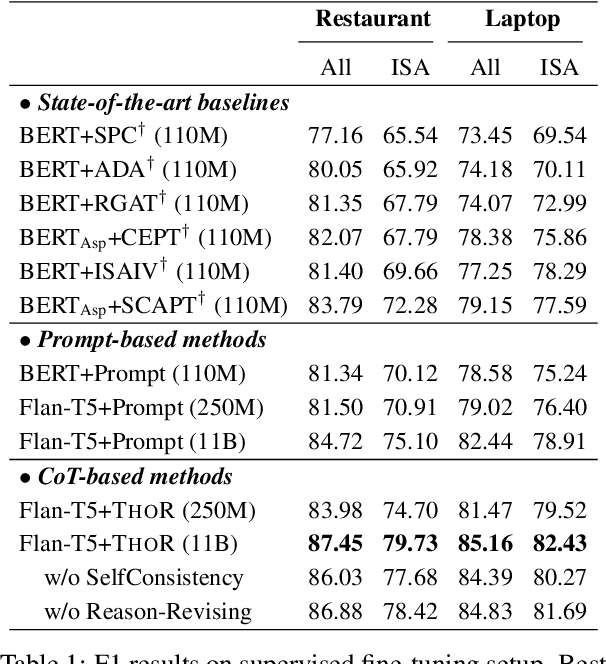

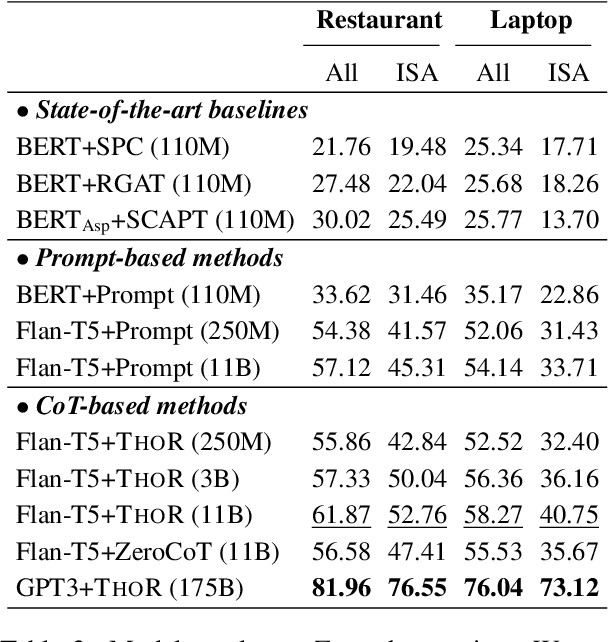
While sentiment analysis systems try to determine the sentiment polarities of given targets based on the key opinion expressions in input texts, in implicit sentiment analysis (ISA) the opinion cues come in an implicit and obscure manner. Thus detecting implicit sentiment requires the common-sense and multi-hop reasoning ability to infer the latent intent of opinion. Inspired by the recent chain-of-thought (CoT) idea, in this work we introduce a Three-hop Reasoning (THOR) CoT framework to mimic the human-like reasoning process for ISA. We design a three-step prompting principle for THOR to step-by-step induce the implicit aspect, opinion, and finally the sentiment polarity. Our THOR+Flan-T5 (11B) pushes the state-of-the-art (SoTA) by over 6% F1 on supervised setup. More strikingly, THOR+GPT3 (175B) boosts the SoTA by over 50% F1 on zero-shot setting. Our code is at https://github.com/scofield7419/THOR-ISA.
DiaASQ: A Benchmark of Conversational Aspect-based Sentiment Quadruple Analysis
Nov 10, 2022
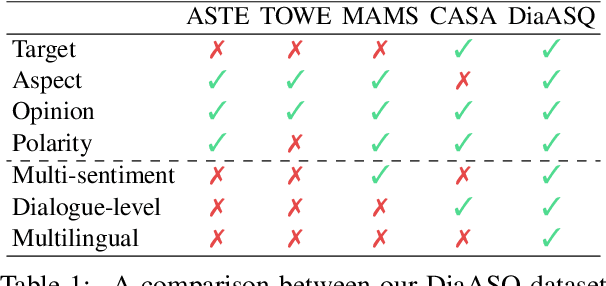
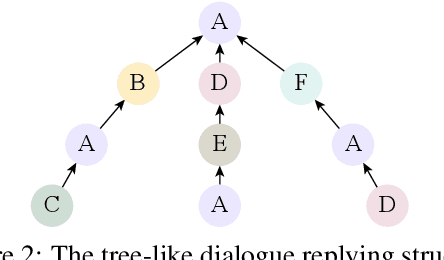
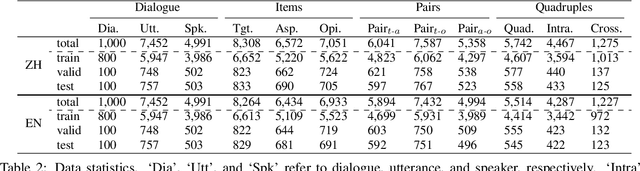
The rapid development of aspect-based sentiment analysis (ABSA) within recent decades shows great potential for real-world society. The current ABSA works, however, are mostly limited to the scenario of a single text piece, leaving the study in dialogue contexts unexplored. In this work, we introduce a novel task of conversational aspect-based sentiment quadruple analysis, namely DiaASQ, aiming to detect the sentiment quadruple of target-aspect-opinion-sentiment in a dialogue. DiaASQ bridges the gap between fine-grained sentiment analysis and conversational opinion mining. We manually construct a large-scale, high-quality Chinese dataset and also obtain the English version dataset via manual translation. We deliberately propose a neural model to benchmark the task. It advances in effectively performing end-to-end quadruple prediction and manages to incorporate rich dialogue-specific and discourse feature representations for better cross-utterance quadruple extraction. We finally point out several potential future works to facilitate the follow-up research of this new task. The DiaASQ data is open at https://github.com/unikcc/DiaASQ
Adaptive Prompt Learning-based Few-Shot Sentiment Analysis
May 15, 2022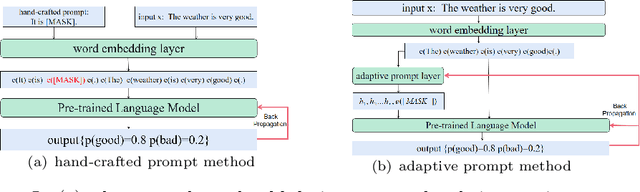
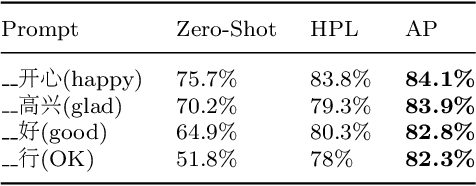
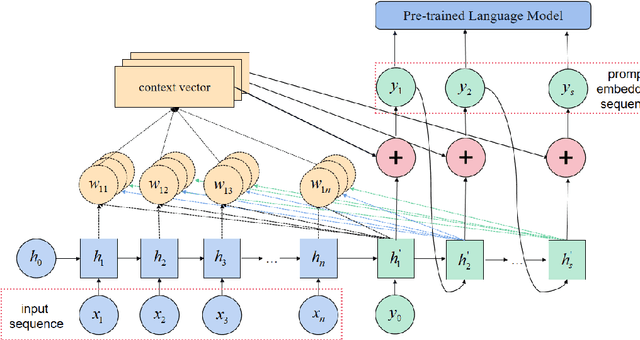
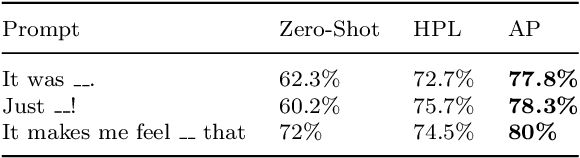
In the field of natural language processing, sentiment analysis via deep learning has a excellent performance by using large labeled datasets. Meanwhile, labeled data are insufficient in many sentiment analysis, and obtaining these data is time-consuming and laborious. Prompt learning devotes to resolving the data deficiency by reformulating downstream tasks with the help of prompt. In this way, the appropriate prompt is very important for the performance of the model. This paper proposes an adaptive prompting(AP) construction strategy using seq2seq-attention structure to acquire the semantic information of the input sequence. Then dynamically construct adaptive prompt which can not only improve the quality of the prompt, but also can effectively generalize to other fields by pre-trained prompt which is constructed by existing public labeled data. The experimental results on FewCLUE datasets demonstrate that the proposed method AP can effectively construct appropriate adaptive prompt regardless of the quality of hand-crafted prompt and outperform the state-of-the-art baselines.
Emoji Prediction using Transformer Models
Jul 05, 2023
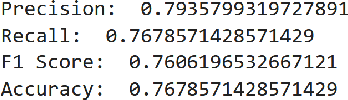
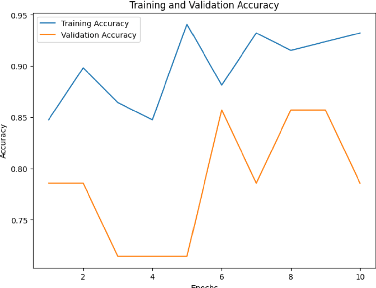
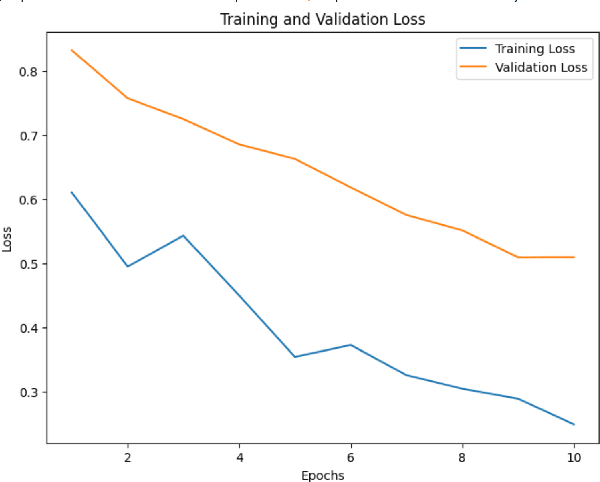
In recent years, the use of emojis in social media has increased dramatically, making them an important element in understanding online communication. However, predicting the meaning of emojis in a given text is a challenging task due to their ambiguous nature. In this study, we propose a transformer-based approach for emoji prediction using BERT, a widely-used pre-trained language model. We fine-tuned BERT on a large corpus of text containing both text and emojis to predict the most appropriate emoji for a given text. Our experimental results demonstrate that our approach outperforms several state-of-the-art models in predicting emojis with an accuracy of over 75 \% This work has potential applications in natural language processing, sentiment analysis, and social media marketing.
Abstractive Summarization of Large Document Collections Using GPT
Oct 09, 2023This paper proposes a method of abstractive summarization designed to scale to document collections instead of individual documents. Our approach applies a combination of semantic clustering, document size reduction within topic clusters, semantic chunking of a cluster's documents, GPT-based summarization and concatenation, and a combined sentiment and text visualization of each topic to support exploratory data analysis. Statistical comparison of our results to existing state-of-the-art systems BART, BRIO, PEGASUS, and MoCa using ROGUE summary scores showed statistically equivalent performance with BART and PEGASUS on the CNN/Daily Mail test dataset, and with BART on the Gigaword test dataset. This finding is promising since we view document collection summarization as more challenging than individual document summarization. We conclude with a discussion of how issues of scale are
Sentiment-Aware Word and Sentence Level Pre-training for Sentiment Analysis
Oct 19, 2022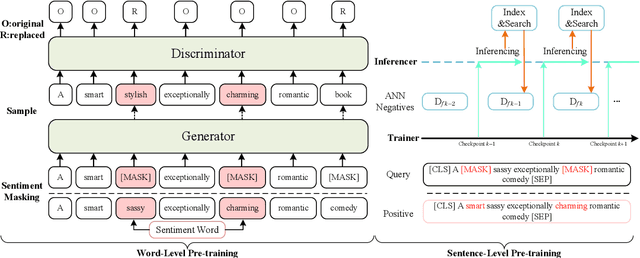
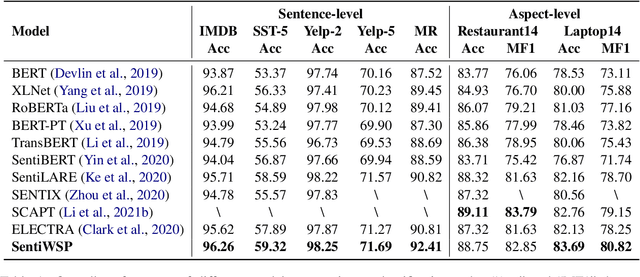
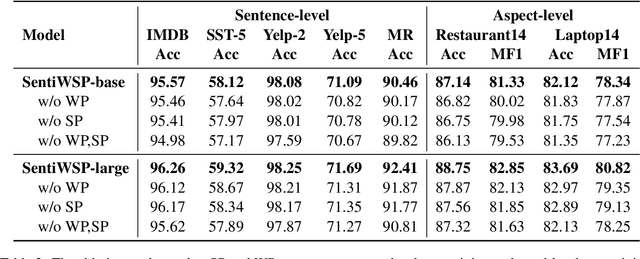
Most existing pre-trained language representation models (PLMs) are sub-optimal in sentiment analysis tasks, as they capture the sentiment information from word-level while under-considering sentence-level information. In this paper, we propose SentiWSP, a novel Sentiment-aware pre-trained language model with combined Word-level and Sentence-level Pre-training tasks. The word level pre-training task detects replaced sentiment words, via a generator-discriminator framework, to enhance the PLM's knowledge about sentiment words. The sentence level pre-training task further strengthens the discriminator via a contrastive learning framework, with similar sentences as negative samples, to encode sentiments in a sentence. Extensive experimental results show that SentiWSP achieves new state-of-the-art performance on various sentence-level and aspect-level sentiment classification benchmarks. We have made our code and model publicly available at https://github.com/XMUDM/SentiWSP.