 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCliff Tokens: Identifying Single-Token Failure Triggers in LLM Mathematical Reasoning
Jun 25, 2026Large language models (LLMs) reach high accuracy in mathematical reasoning, but individual traces on the same problem diverge; some arrive at the correct answer while others fail. Prior work analyzes failure at the step, chunk, or sentence level, or at tokens where failure has already occurred. Neither identifies the precise token that triggers the shift toward failure. We introduce the cliff token, a token where the token-wise potential drops significantly under an adaptive threshold that scales with the local token-wise potential, based on a one-sided two-proportion z-test. Across seven models and three mathematical reasoning benchmarks (GSM1K, MATH500, AIME 2025), cliff tokens act as failure triggers; deleting the first cliff token and resampling recovers pass@64 to 1.0, while keeping it limits recovery to between 0.71 and 1.00. We further introduce a cliff taxonomy of deterministic, uncertain, and sampled-off cliffs, defined by greedy choice and token entropy. Each type has distinct probabilistic characteristics, and the taxonomy generalizes across model scales. Finally, we validate the taxonomy via single-token preference optimization at cliff positions (Cliff-DPO). Trained on GSM8K, Cliff-DPO improves accuracy across benchmarks by up to +6.6. Optimizing at uncertain and sampled-off cliffs improves reasoning, while deterministic cliffs do not.
CIRF: Tokenizing Chain-of-Thoughts into Reusable Functional Units for Efficient Latent Reasoning in Large Language Models
May 27, 2026Implicit Chain-of-Thought (CoT) reduces the inference cost of large language models by internalizing the explicit rationales. However, existing approaches typically lack alignment with explicit rationales and adaptivity to example complexity. In this work, we propose CIRF (\textit{\underline{C}hain-of-thoughts \underline{I}nto \underline{R}eusable \underline{F}unctional units}), an implicit CoT framework that performs reasoning as a dynamic sequence of discrete functional tokens. CIRF assigns a functional token to each semantically coherent reasoning unit in explicit CoT traces. The model is then fine-tuned to autoregressively generate functional tokens and their optional results, followed by the final answer. This design aligns latent reasoning with a sequence of functional units, facilitating parallel training, explicit rationale alignment, and adaptive reasoning. Extensive experiments on mathematical, symbolic, and commonsense reasoning benchmarks show that CIRF provides a favorable accuracy-latency trade-off compared with state-of-the-art implicit CoT methods. Further analyses demonstrate that CIRF constructs distinct, interpretable functional tokens, leading to consistent performance improvements.
A Gradient Accumulation Method for Dense Retriever under Memory Constraint
Jun 18, 2024



InfoNCE loss is commonly used to train dense retriever in information retrieval tasks. It is well known that a large batch is essential to stable and effective training with InfoNCE loss, which requires significant hardware resources. Due to the dependency of large batch, dense retriever has bottleneck of application and research. Recently, memory reduction methods have been broadly adopted to resolve the hardware bottleneck by decomposing forward and backward or using a memory bank. However, current methods still suffer from slow and unstable training. To address these issues, we propose \longmodelname\ (\modelname), a stable and efficient memory reduction method for dense retriever trains that uses a dual memory bank structure to leverage previously generated query and passage representations. Experiments on widely used five information retrieval datasets indicate that \modelname\ can surpass not only existing memory reduction methods but also high-resource scenario. Moreover, theoretical analysis and experimental results confirm that \modelname\ provides more stable dual-encoder training than current memory bank utilization methods.
Navigating the Path of Writing: Outline-guided Text Generation with Large Language Models
Apr 22, 2024



Large Language Models (LLMs) have significantly impacted the writing process, enabling collaborative content creation and enhancing productivity. However, generating high-quality, user-aligned text remains challenging. In this paper, we propose Writing Path, a framework that uses explicit outlines to guide LLMs in generating goal-oriented, high-quality pieces of writing. Our approach draws inspiration from structured writing planning and reasoning paths, focusing on capturing and reflecting user intentions throughout the writing process. We construct a diverse dataset from unstructured blog posts to benchmark writing performance and introduce a comprehensive evaluation framework assessing the quality of outlines and generated texts. Our evaluations with GPT-3.5-turbo, GPT-4, and HyperCLOVA X demonstrate that the Writing Path approach significantly enhances text quality according to both LLMs and human evaluations. This study highlights the potential of integrating writing-specific techniques into LLMs to enhance their ability to meet the diverse writing needs of users.
CheckEval: Robust Evaluation Framework using Large Language Model via Checklist
Mar 27, 2024



We introduce CheckEval, a novel evaluation framework using Large Language Models, addressing the challenges of ambiguity and inconsistency in current evaluation methods. CheckEval addresses these challenges by dividing evaluation criteria into detailed sub-aspects and constructing a checklist of Boolean questions for each, simplifying the evaluation. This approach not only renders the process more interpretable but also significantly enhances the robustness and reliability of results by focusing on specific evaluation dimensions. Validated through a focused case study using the SummEval benchmark, CheckEval indicates a strong correlation with human judgments. Furthermore, it demonstrates a highly consistent Inter-Annotator Agreement. These findings highlight the effectiveness of CheckEval for objective, flexible, and precise evaluations. By offering a customizable and interactive framework, CheckEval sets a new standard for the use of LLMs in evaluation, responding to the evolving needs of the field and establishing a clear method for future LLM-based evaluation.
RAPID: Training-free Retrieval-based Log Anomaly Detection with PLM considering Token-level information
Nov 09, 2023



As the IT industry advances, system log data becomes increasingly crucial. Many computer systems rely on log texts for management due to restricted access to source code. The need for log anomaly detection is growing, especially in real-world applications, but identifying anomalies in rapidly accumulating logs remains a challenging task. Traditional deep learning-based anomaly detection models require dataset-specific training, leading to corresponding delays. Notably, most methods only focus on sequence-level log information, which makes the detection of subtle anomalies harder, and often involve inference processes that are difficult to utilize in real-time. We introduce RAPID, a model that capitalizes on the inherent features of log data to enable anomaly detection without training delays, ensuring real-time capability. RAPID treats logs as natural language, extracting representations using pre-trained language models. Given that logs can be categorized based on system context, we implement a retrieval-based technique to contrast test logs with the most similar normal logs. This strategy not only obviates the need for log-specific training but also adeptly incorporates token-level information, ensuring refined and robust detection, particularly for unseen logs. We also propose the core set technique, which can reduce the computational cost needed for comparison. Experimental results show that even without training on log data, RAPID demonstrates competitive performance compared to prior models and achieves the best performance on certain datasets. Through various research questions, we verified its capability for real-time detection without delay.
Painsight: An Extendable Opinion Mining Framework for Detecting Pain Points Based on Online Customer Reviews
Jun 03, 2023



As the e-commerce market continues to expand and online transactions proliferate, customer reviews have emerged as a critical element in shaping the purchasing decisions of prospective buyers. Previous studies have endeavored to identify key aspects of customer reviews through the development of sentiment analysis models and topic models. However, extracting specific dissatisfaction factors remains a challenging task. In this study, we delineate the pain point detection problem and propose Painsight, an unsupervised framework for automatically extracting distinct dissatisfaction factors from customer reviews without relying on ground truth labels. Painsight employs pre-trained language models to construct sentiment analysis and topic models, leveraging attribution scores derived from model gradients to extract dissatisfaction factors. Upon application of the proposed methodology to customer review data spanning five product categories, we successfully identified and categorized dissatisfaction factors within each group, as well as isolated factors for each type. Notably, Painsight outperformed benchmark methods, achieving substantial performance enhancements and exceptional results in human evaluations.
DSTEA: Dialogue State Tracking with Entity Adaptive Pre-training
Jul 08, 2022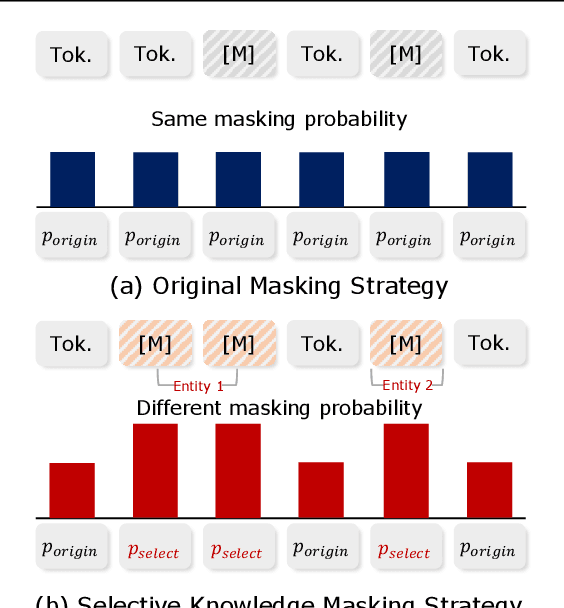
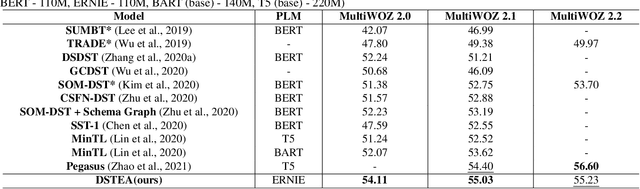
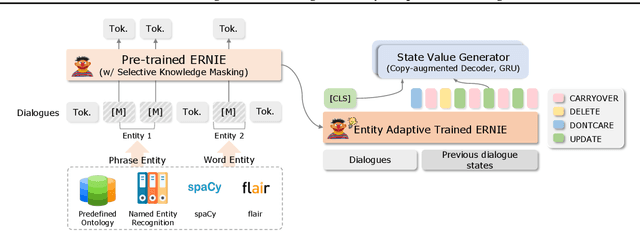
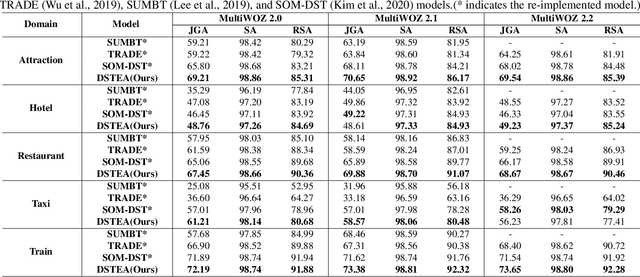
Dialogue state tracking (DST) is a core sub-module of a dialogue system, which aims to extract the appropriate belief state (domain-slot-value) from a system and user utterances. Most previous studies have attempted to improve performance by increasing the size of the pre-trained model or using additional features such as graph relations. In this study, we propose dialogue state tracking with entity adaptive pre-training (DSTEA), a system in which key entities in a sentence are more intensively trained by the encoder of the DST model. DSTEA extracts important entities from input dialogues in four ways, and then applies selective knowledge masking to train the model effectively. Although DSTEA conducts only pre-training without directly infusing additional knowledge to the DST model, it achieved better performance than the best-known benchmark models on MultiWOZ 2.0, 2.1, and 2.2. The effectiveness of DSTEA was verified through various comparative experiments with regard to the entity type and different adaptive settings.
Mismatch between Multi-turn Dialogue and its Evaluation Metric in Dialogue State Tracking
Mar 31, 2022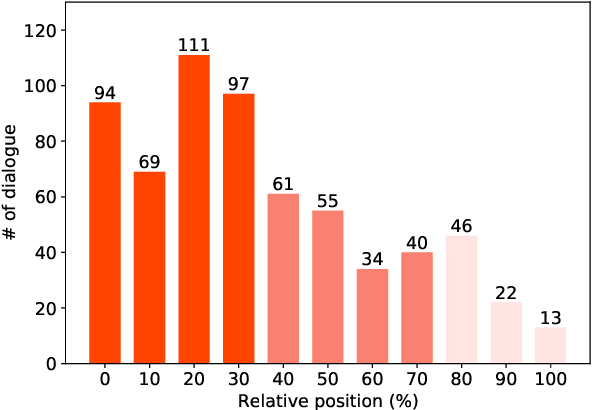
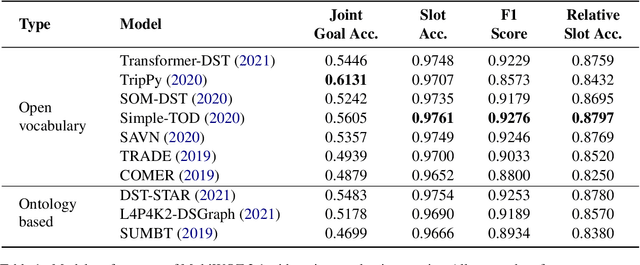
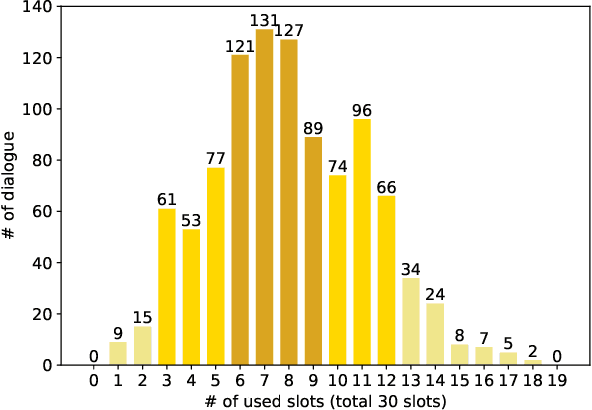
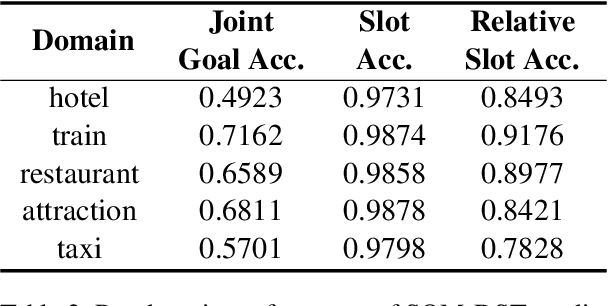
Dialogue state tracking (DST) aims to extract essential information from multi-turn dialogue situations and take appropriate actions. A belief state, one of the core pieces of information, refers to the subject and its specific content, and appears in the form of domain-slot-value. The trained model predicts "accumulated" belief states in every turn, and joint goal accuracy and slot accuracy are mainly used to evaluate the prediction; however, we specify that the current evaluation metrics have a critical limitation when evaluating belief states accumulated as the dialogue proceeds, especially in the most used MultiWOZ dataset. Additionally, we propose relative slot accuracy to complement existing metrics. Relative slot accuracy does not depend on the number of predefined slots, and allows intuitive evaluation by assigning relative scores according to the turn of each dialogue. This study also encourages not solely the reporting of joint goal accuracy, but also various complementary metrics in DST tasks for the sake of a realistic evaluation.
LAnoBERT : System Log Anomaly Detection based on BERT Masked Language Model
Nov 20, 2021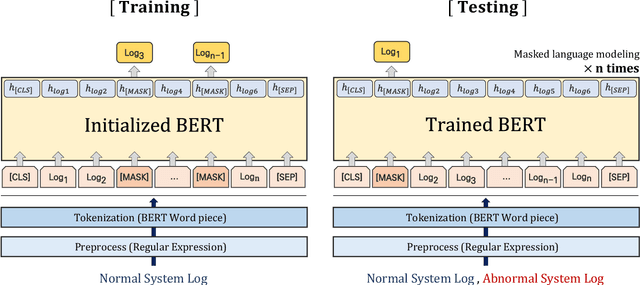
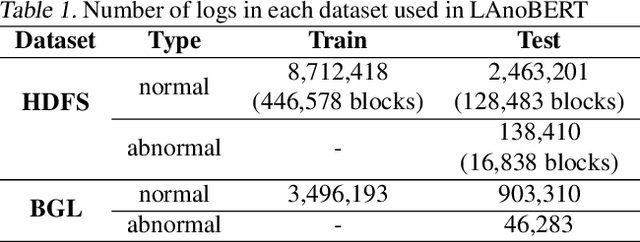


The system log generated in a computer system refers to large-scale data that are collected simultaneously and used as the basic data for determining simple errors and detecting external adversarial intrusion or the abnormal behaviors of insiders. The aim of system log anomaly detection is to promptly identify anomalies while minimizing human intervention, which is a critical problem in the industry. Previous studies performed anomaly detection through algorithms after converting various forms of log data into a standardized template using a parser. These methods involved generating a template for refining the log key. Particularly, a template corresponding to a specific event should be defined in advance for all the log data using which the information within the log key may get lost.In this study, we propose LAnoBERT, a parser free system log anomaly detection method that uses the BERT model, exhibiting excellent natural language processing performance. The proposed method, LAnoBERT, learns the model through masked language modeling, which is a BERT-based pre-training method, and proceeds with unsupervised learning-based anomaly detection using the masked language modeling loss function per log key word during the inference process. LAnoBERT achieved better performance compared to previous methodology in an experiment conducted using benchmark log datasets, HDFS, and BGL, and also compared to certain supervised learning-based models.