 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Plug-In RIS: A Novel Approach to Fully Passive Reconfigurable Intelligent Surfaces
Nov 16, 2023
This paper presents a promising design concept for reconfigurable intelligent surfaces (RISs), named plug-in RIS, wherein the RIS is plugged into an appropriate position in the environment, adjusted once according to the location of both base station and blocked region, and operates with fixed beams to enhance the system performance. The plug-in RIS is a novel system design, streamlining RIS-assisted millimeter-wave (mmWave) communication without requiring decoupling two parts of the end-to-end channel, traditional control signal transmission, and online RIS configuration. In plug-in RIS-aided transmission, the transmitter efficiently activates specific regions of the divided large RIS by employing hybrid beamforming techniques, each with predetermined phase adjustments tailored to reflect signals to desired user locations. This user-centric approach enhances connectivity and overall user experience by dynamically illuminating the targeted user based on location. By introducing plug-in RIS's theoretical framework, design principles, and performance evaluation, we demonstrate its potential to revolutionize mmWave communications in limited channel state information (CSI) scenarios. Simulation results illustrate that plug-in RIS provides power/cost-efficient solutions to overcome blockage in the mmWave communication system and a striking convergence in average bit error rate and achievable rate performance with traditional full CSI-enabled RIS solutions.
SCORE: A framework for Self-Contradictory Reasoning Evaluation
Nov 16, 2023Large language models (LLMs) have demonstrated impressive reasoning ability in various language-based tasks. Despite many proposed reasoning methods aimed at enhancing performance in downstream tasks, two fundamental questions persist: Does reasoning genuinely support predictions, and how reliable is the quality of reasoning? In this paper, we propose a framework \textsc{SCORE} to analyze how well LLMs can reason. Specifically, we focus on self-contradictory reasoning, where reasoning does not support the prediction. We find that LLMs often contradict themselves when performing reasoning tasks that involve contextual information and commonsense. The model may miss evidence or use shortcuts, thereby exhibiting self-contradictory behaviors. We also employ the Point-of-View (POV) method, which probes models to generate reasoning from multiple perspectives, as a diagnostic tool for further analysis. We find that though LLMs may appear to perform well in one-perspective settings, they fail to stabilize such behavior in multi-perspectives settings. Even for correct predictions, the reasoning may be messy and incomplete, and LLMs can easily be led astray from good reasoning. \textsc{SCORE}'s results underscore the lack of robustness required for trustworthy reasoning and the urgency for further research to establish best practices for a comprehensive evaluation of reasoning beyond accuracy-based metrics.
A Knowledge Distillation Approach for Sepsis Outcome Prediction from Multivariate Clinical Time Series
Nov 16, 2023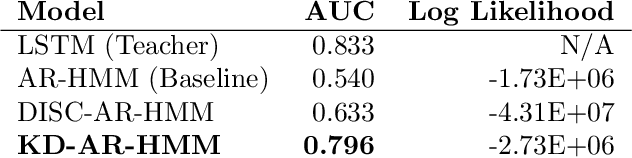
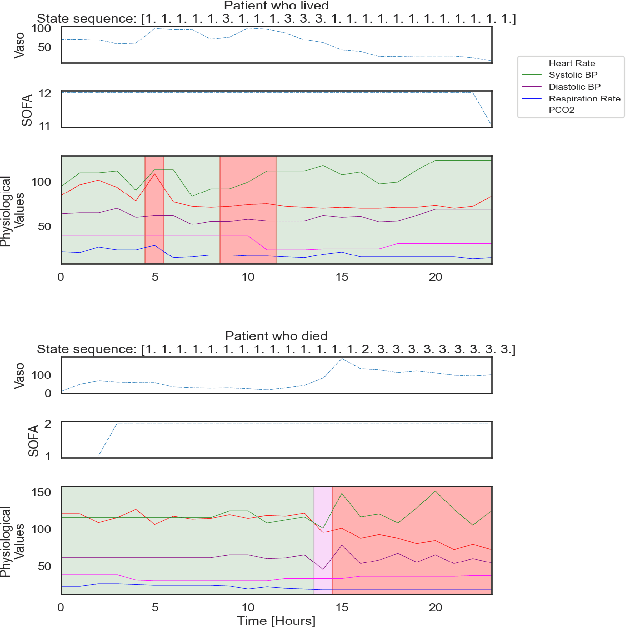
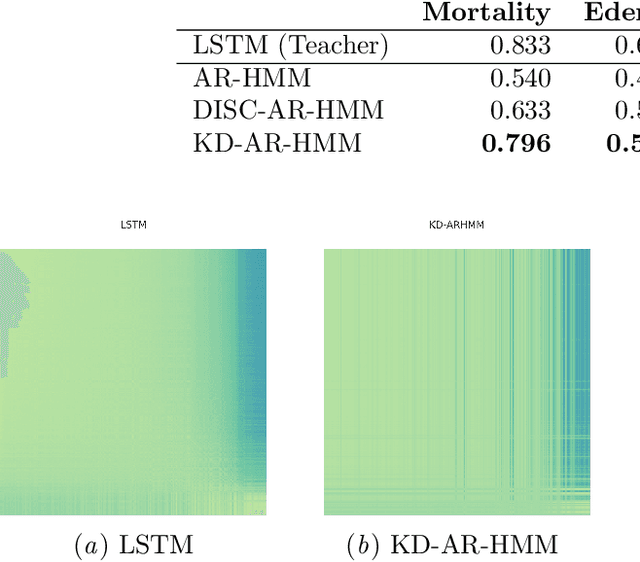

Sepsis is a life-threatening condition triggered by an extreme infection response. Our objective is to forecast sepsis patient outcomes using their medical history and treatments, while learning interpretable state representations to assess patients' risks in developing various adverse outcomes. While neural networks excel in outcome prediction, their limited interpretability remains a key issue. In this work, we use knowledge distillation via constrained variational inference to distill the knowledge of a powerful "teacher" neural network model with high predictive power to train a "student" latent variable model to learn interpretable hidden state representations to achieve high predictive performance for sepsis outcome prediction. Using real-world data from the MIMIC-IV database, we trained an LSTM as the "teacher" model to predict mortality for sepsis patients, given information about their recent history of vital signs, lab values and treatments. For our student model, we use an autoregressive hidden Markov model (AR-HMM) to learn interpretable hidden states from patients' clinical time series, and use the posterior distribution of the learned state representations to predict various downstream outcomes, including hospital mortality, pulmonary edema, need for diuretics, dialysis, and mechanical ventilation. Our results show that our approach successfully incorporates the constraint to achieve high predictive power similar to the teacher model, while maintaining the generative performance.
Index Modulation-based Information Harvesting for Far-Field RF Power Transfer
Sep 21, 2023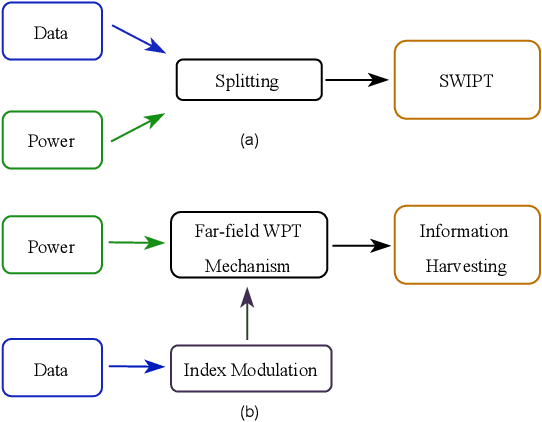
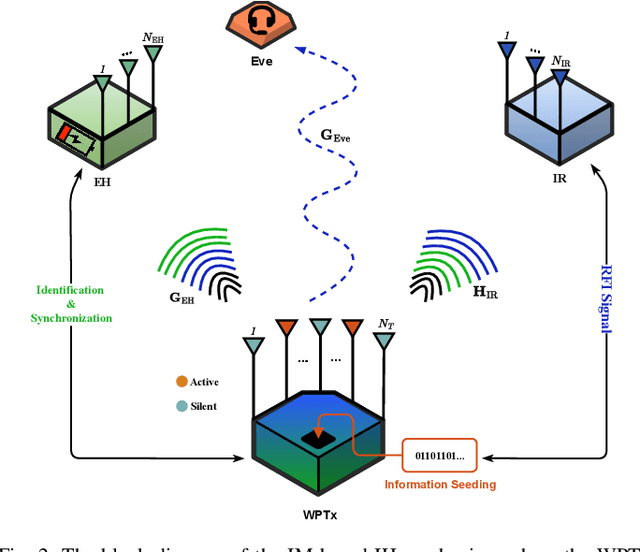
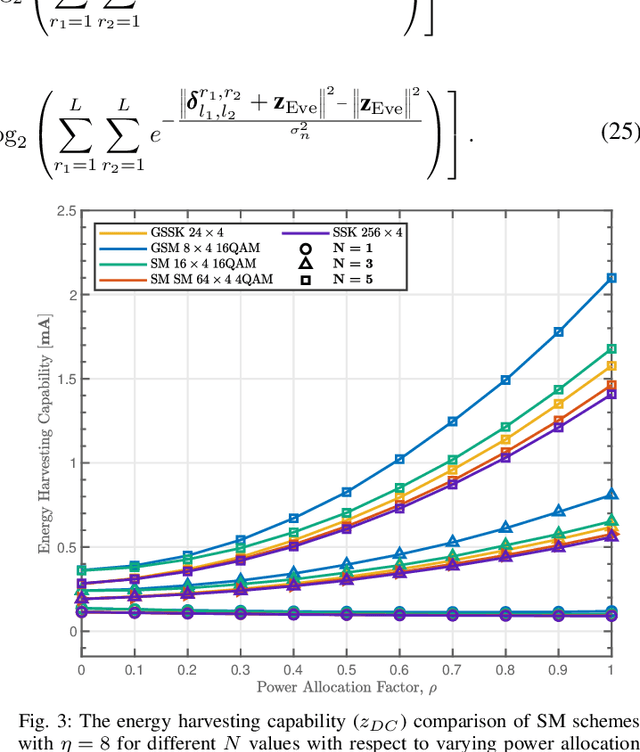
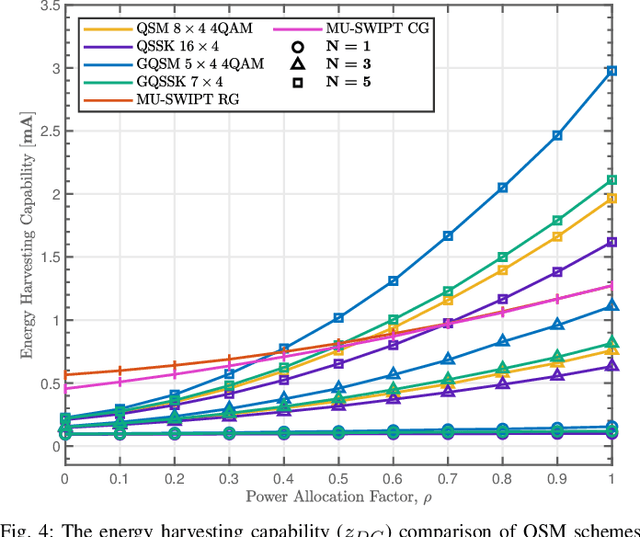
While wireless information transmission (WIT) is evolving into its sixth generation (6G), maintaining terminal operations that rely on limited battery capacities has become one of the most paramount challenges for Internet-of-Things (IoT) platforms. In this respect, there exists a growing interest in energy harvesting technology from ambient resources, and wireless power transfer (WPT) can be the key solution towards enabling battery-less infrastructures referred to as zero-power communication technology. Indeed, eclectic integration approaches between WPT and WIT mechanisms are becoming a vital necessity to limit the need for replacing batteries. Beyond the conventional separation between data and power components of the emitted waveforms, as in simultaneous wireless information and power transfer (SWIPT) mechanisms, a novel protocol referred to as information harvesting (IH) has recently emerged. IH leverages existing WPT mechanisms for data communication by incorporating index modulation (IM) techniques on top of the existing far-field power transfer mechanism. In this paper, a unified framework for the IM-based IH mechanisms has been presented where the feasibility of various IM techniques are evaluated based on different performance metrics. The presented results demonstrate the substantial potential to enable data communication within existing far-field WPT systems, particularly in the context of next-generation IoT wireless networks.
Image Patch-Matching with Graph-Based Learning in Street Scenes
Nov 08, 2023Matching landmark patches from a real-time image captured by an on-vehicle camera with landmark patches in an image database plays an important role in various computer perception tasks for autonomous driving. Current methods focus on local matching for regions of interest and do not take into account spatial neighborhood relationships among the image patches, which typically correspond to objects in the environment. In this paper, we construct a spatial graph with the graph vertices corresponding to patches and edges capturing the spatial neighborhood information. We propose a joint feature and metric learning model with graph-based learning. We provide a theoretical basis for the graph-based loss by showing that the information distance between the distributions conditioned on matched and unmatched pairs is maximized under our framework. We evaluate our model using several street-scene datasets and demonstrate that our approach achieves state-of-the-art matching results.
Can Machine Learning Uncover Insights into Vehicle Travel Demand from Our Built Environment?
Nov 10, 2023In this paper, we propose a machine learning-based approach to address the lack of ability for designers to optimize urban land use planning from the perspective of vehicle travel demand. Research shows that our computational model can help designers quickly obtain feedback on the vehicle travel demand, which includes its total amount and temporal distribution based on the urban function distribution designed by the designers. It also assists in design optimization and evaluation of the urban function distribution from the perspective of vehicle travel. We obtain the city function distribution information and vehicle hours traveled (VHT) information by collecting the city point-of-interest (POI) data and online vehicle data. The artificial neural networks (ANNs) with the best performance in prediction are selected. By using data sets collected in different regions for mutual prediction and remapping the predictions onto a map for visualization, we evaluate the extent to which the computational model sees use across regions in an attempt to reduce the workload of future urban researchers. Finally, we demonstrate the application of the computational model to help designers obtain feedback on vehicle travel demand in the built environment and combine it with genetic algorithms to optimize the current state of the urban environment to provide recommendations to designers.
Time Series Synthesis Using the Matrix Profile for Anonymization
Nov 05, 2023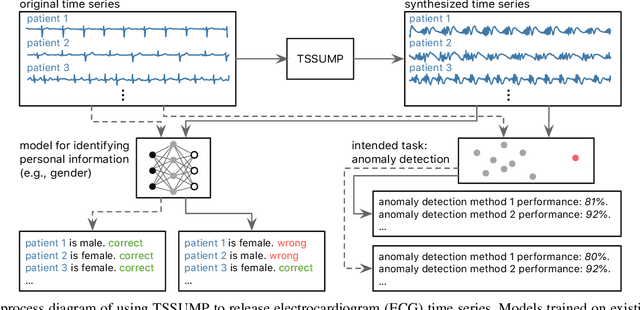
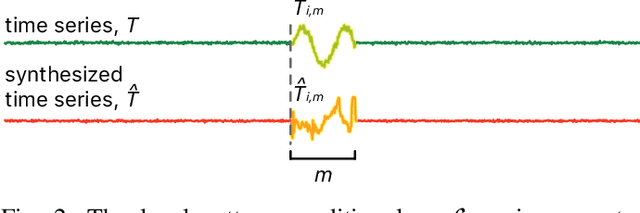
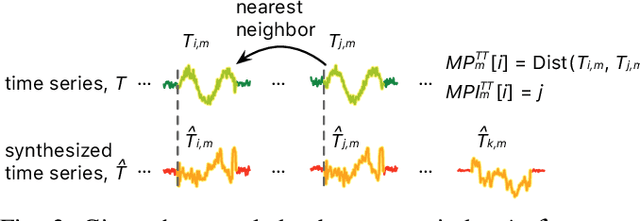
Publishing and sharing data is crucial for the data mining community, allowing collaboration and driving open innovation. However, many researchers cannot release their data due to privacy regulations or fear of leaking confidential business information. To alleviate such issues, we propose the Time Series Synthesis Using the Matrix Profile (TSSUMP) method, where synthesized time series can be released in lieu of the original data. The TSSUMP method synthesizes time series by preserving similarity join information (i.e., Matrix Profile) while reducing the correlation between the synthesized and the original time series. As a result, neither the values for the individual time steps nor the local patterns (or shapes) from the original data can be recovered, yet the resulting data can be used for downstream tasks that data analysts are interested in. We concentrate on similarity joins because they are one of the most widely applied time series data mining routines across different data mining tasks. We test our method on a case study of ECG and gender masking prediction. In this case study, the gender information is not only removed from the synthesized time series, but the synthesized time series also preserves enough information from the original time series. As a result, unmodified data mining tools can obtain near-identical performance on the synthesized time series as on the original time series.
Behavior Optimized Image Generation
Nov 18, 2023The last few years have witnessed great success on image generation, which has crossed the acceptance thresholds of aesthetics, making it directly applicable to personal and commercial applications. However, images, especially in marketing and advertising applications, are often created as a means to an end as opposed to just aesthetic concerns. The goal can be increasing sales, getting more clicks, likes, or image sales (in the case of stock businesses). Therefore, the generated images need to perform well on these key performance indicators (KPIs), in addition to being aesthetically good. In this paper, we make the first endeavor to answer the question of "How can one infuse the knowledge of the end-goal within the image generation process itself to create not just better-looking images but also "better-performing'' images?''. We propose BoigLLM, an LLM that understands both image content and user behavior. BoigLLM knows how an image should look to get a certain required KPI. We show that BoigLLM outperforms 13x larger models such as GPT-3.5 and GPT-4 in this task, demonstrating that while these state-of-the-art models can understand images, they lack information on how these images perform in the real world. To generate actual pixels of behavior-conditioned images, we train a diffusion-based model (BoigSD) to align with a proposed BoigLLM-defined reward. We show the performance of the overall pipeline on two datasets covering two different behaviors: a stock dataset with the number of forward actions as the KPI and a dataset containing tweets with the total likes as the KPI, denoted as BoigBench. To advance research in the direction of utility-driven image generation and understanding, we release BoigBench, a benchmark dataset containing 168 million enterprise tweets with their media, brand account names, time of post, and total likes.
LT-ViT: A Vision Transformer for multi-label Chest X-ray classification
Nov 13, 2023Vision Transformers (ViTs) are widely adopted in medical imaging tasks, and some existing efforts have been directed towards vision-language training for Chest X-rays (CXRs). However, we envision that there still exists a potential for improvement in vision-only training for CXRs using ViTs, by aggregating information from multiple scales, which has been proven beneficial for non-transformer networks. Hence, we have developed LT-ViT, a transformer that utilizes combined attention between image tokens and randomly initialized auxiliary tokens that represent labels. Our experiments demonstrate that LT-ViT (1) surpasses the state-of-the-art performance using pure ViTs on two publicly available CXR datasets, (2) is generalizable to other pre-training methods and therefore is agnostic to model initialization, and (3) enables model interpretability without grad-cam and its variants.
On The Truthfulness of 'Surprisingly Likely' Responses of Large Language Models
Nov 13, 2023The surprisingly likely criterion in the seminal work of Prelec (the Bayesian Truth Serum) guarantees truthfulness in a game-theoretic multi-agent setting, by rewarding rational agents to maximise the expected information gain with their answers w.r.t. their probabilistic beliefs. We investigate the relevance of a similar criterion for responses of LLMs. We hypothesize that if the surprisingly likely criterion works in LLMs, under certain conditions, the responses that maximize the reward under this criterion should be more accurate than the responses that only maximize the posterior probability. Using benchmarks including the TruthfulQA benchmark and using openly available LLMs: GPT-2 and LLaMA-2, we show that the method indeed improves the accuracy significantly (for example, upto 24 percentage points aggregate improvement on TruthfulQA and upto 70 percentage points improvement on individual categories of questions).