 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix Profile for Anomaly Detection on Multidimensional Time Series
Sep 14, 2024



The Matrix Profile (MP), a versatile tool for time series data mining, has been shown effective in time series anomaly detection (TSAD). This paper delves into the problem of anomaly detection in multidimensional time series, a common occurrence in real-world applications. For instance, in a manufacturing factory, multiple sensors installed across the site collect time-varying data for analysis. The Matrix Profile, named for its role in profiling the matrix storing pairwise distance between subsequences of univariate time series, becomes complex in multidimensional scenarios. If the input univariate time series has n subsequences, the pairwise distance matrix is a n x n matrix. In a multidimensional time series with d dimensions, the pairwise distance information must be stored in a n x n x d tensor. In this paper, we first analyze different strategies for condensing this tensor into a profile vector. We then investigate the potential of extending the MP to efficiently find k-nearest neighbors for anomaly detection. Finally, we benchmark the multidimensional MP against 19 baseline methods on 119 multidimensional TSAD datasets. The experiments covers three learning setups: unsupervised, supervised, and semi-supervised. MP is the only method that consistently delivers high performance across all setups.
A Systematic Evaluation of Generated Time Series and Their Effects in Self-Supervised Pretraining
Aug 15, 2024



Self-supervised Pretrained Models (PTMs) have demonstrated remarkable performance in computer vision and natural language processing tasks. These successes have prompted researchers to design PTMs for time series data. In our experiments, most self-supervised time series PTMs were surpassed by simple supervised models. We hypothesize this undesired phenomenon may be caused by data scarcity. In response, we test six time series generation methods, use the generated data in pretraining in lieu of the real data, and examine the effects on classification performance. Our results indicate that replacing a real-data pretraining set with a greater volume of only generated samples produces noticeable improvement.
PUPAE: Intuitive and Actionable Explanations for Time Series Anomalies
Jan 16, 2024



In recent years there has been significant progress in time series anomaly detection. However, after detecting an (perhaps tentative) anomaly, can we explain it? Such explanations would be useful to triage anomalies. For example, in an oil refinery, should we respond to an anomaly by dispatching a hydraulic engineer, or an intern to replace the battery on a sensor? There have been some parallel efforts to explain anomalies, however many proposed techniques produce explanations that are indirect, and often seem more complex than the anomaly they seek to explain. Our review of the literature/checklists/user-manuals used by frontline practitioners in various domains reveals an interesting near-universal commonality. Most practitioners discuss, explain and report anomalies in the following format: The anomaly would be like normal data A, if not for the corruption B. The reader will appreciate that is a type of counterfactual explanation. In this work we introduce a domain agnostic counterfactual explanation technique to produce explanations for time series anomalies. As we will show, our method can produce both visual and text-based explanations that are objectively correct, intuitive and in many circumstances, directly actionable.
* 9 Page Manuscript, 1 Page Supplementary (Supplement not published in conference proceedings.)
Time Series Synthesis Using the Matrix Profile for Anonymization
Nov 05, 2023



Publishing and sharing data is crucial for the data mining community, allowing collaboration and driving open innovation. However, many researchers cannot release their data due to privacy regulations or fear of leaking confidential business information. To alleviate such issues, we propose the Time Series Synthesis Using the Matrix Profile (TSSUMP) method, where synthesized time series can be released in lieu of the original data. The TSSUMP method synthesizes time series by preserving similarity join information (i.e., Matrix Profile) while reducing the correlation between the synthesized and the original time series. As a result, neither the values for the individual time steps nor the local patterns (or shapes) from the original data can be recovered, yet the resulting data can be used for downstream tasks that data analysts are interested in. We concentrate on similarity joins because they are one of the most widely applied time series data mining routines across different data mining tasks. We test our method on a case study of ECG and gender masking prediction. In this case study, the gender information is not only removed from the synthesized time series, but the synthesized time series also preserves enough information from the original time series. As a result, unmodified data mining tools can obtain near-identical performance on the synthesized time series as on the original time series.
Temporal Treasure Hunt: Content-based Time Series Retrieval System for Discovering Insights
Nov 05, 2023



Time series data is ubiquitous across various domains such as finance, healthcare, and manufacturing, but their properties can vary significantly depending on the domain they originate from. The ability to perform Content-based Time Series Retrieval (CTSR) is crucial for identifying unknown time series examples. However, existing CTSR works typically focus on retrieving time series from a single domain database, which can be inadequate if the user does not know the source of the query time series. This limitation motivates us to investigate the CTSR problem in a scenario where the database contains time series from multiple domains. To facilitate this investigation, we introduce a CTSR benchmark dataset that comprises time series data from a variety of domains, such as motion, power demand, and traffic. This dataset is sourced from a publicly available time series classification dataset archive, making it easily accessible to researchers in the field. We compare several popular methods for modeling and retrieving time series data using this benchmark dataset. Additionally, we propose a novel distance learning model that outperforms the existing methods. Overall, our study highlights the importance of addressing the CTSR problem across multiple domains and provides a useful benchmark dataset for future research.
Multitask Learning for Time Series Data with 2D Convolution
Oct 10, 2023Multitask learning (MTL) aims to develop a unified model that can handle a set of closely related tasks simultaneously. By optimizing the model across multiple tasks, MTL generally surpasses its non-MTL counterparts in terms of generalizability. Although MTL has been extensively researched in various domains such as computer vision, natural language processing, and recommendation systems, its application to time series data has received limited attention. In this paper, we investigate the application of MTL to the time series classification (TSC) problem. However, when we integrate the state-of-the-art 1D convolution-based TSC model with MTL, the performance of the TSC model actually deteriorates. By comparing the 1D convolution-based models with the Dynamic Time Warping (DTW) distance function, it appears that the underwhelming results stem from the limited expressive power of the 1D convolutional layers. To overcome this challenge, we propose a novel design for a 2D convolution-based model that enhances the model's expressiveness. Leveraging this advantage, our proposed method outperforms competing approaches on both the UCR Archive and an industrial transaction TSC dataset.
An Efficient Content-based Time Series Retrieval System
Oct 05, 2023



A Content-based Time Series Retrieval (CTSR) system is an information retrieval system for users to interact with time series emerged from multiple domains, such as finance, healthcare, and manufacturing. For example, users seeking to learn more about the source of a time series can submit the time series as a query to the CTSR system and retrieve a list of relevant time series with associated metadata. By analyzing the retrieved metadata, users can gather more information about the source of the time series. Because the CTSR system is required to work with time series data from diverse domains, it needs a high-capacity model to effectively measure the similarity between different time series. On top of that, the model within the CTSR system has to compute the similarity scores in an efficient manner as the users interact with the system in real-time. In this paper, we propose an effective and efficient CTSR model that outperforms alternative models, while still providing reasonable inference runtimes. To demonstrate the capability of the proposed method in solving business problems, we compare it against alternative models using our in-house transaction data. Our findings reveal that the proposed model is the most suitable solution compared to others for our transaction data problem.
Toward a Foundation Model for Time Series Data
Oct 05, 2023



A foundation model is a machine learning model trained on a large and diverse set of data, typically using self-supervised learning-based pre-training techniques, that can be adapted to various downstream tasks. However, current research on time series pre-training has mostly focused on models pre-trained solely on data from a single domain, resulting in a lack of knowledge about other types of time series. However, current research on time series pre-training has predominantly focused on models trained exclusively on data from a single domain. As a result, these models possess domain-specific knowledge that may not be easily transferable to time series from other domains. In this paper, we aim to develop an effective time series foundation model by leveraging unlabeled samples from multiple domains. To achieve this, we repurposed the publicly available UCR Archive and evaluated four existing self-supervised learning-based pre-training methods, along with a novel method, on the datasets. We tested these methods using four popular neural network architectures for time series to understand how the pre-training methods interact with different network designs. Our experimental results show that pre-training improves downstream classification tasks by enhancing the convergence of the fine-tuning process. Furthermore, we found that the proposed pre-training method, when combined with the Transformer model, outperforms the alternatives.
Matrix Profile XXVII: A Novel Distance Measure for Comparing Long Time Series
Dec 09, 2022



The most useful data mining primitives are distance measures. With an effective distance measure, it is possible to perform classification, clustering, anomaly detection, segmentation, etc. For single-event time series Euclidean Distance and Dynamic Time Warping distance are known to be extremely effective. However, for time series containing cyclical behaviors, the semantic meaningfulness of such comparisons is less clear. For example, on two separate days the telemetry from an athlete workout routine might be very similar. The second day may change the order in of performing push-ups and squats, adding repetitions of pull-ups, or completely omitting dumbbell curls. Any of these minor changes would defeat existing time series distance measures. Some bag-of-features methods have been proposed to address this problem, but we argue that in many cases, similarity is intimately tied to the shapes of subsequences within these longer time series. In such cases, summative features will lack discrimination ability. In this work we introduce PRCIS, which stands for Pattern Representation Comparison in Series. PRCIS is a distance measure for long time series, which exploits recent progress in our ability to summarize time series with dictionaries. We will demonstrate the utility of our ideas on diverse tasks and datasets.
When is Early Classification of Time Series Meaningful?
Feb 23, 2021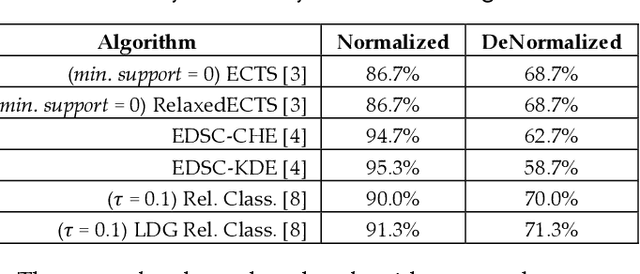
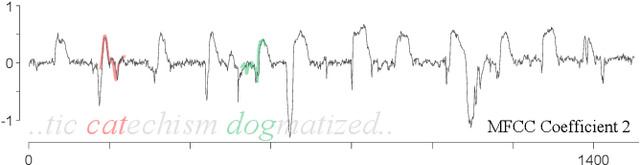
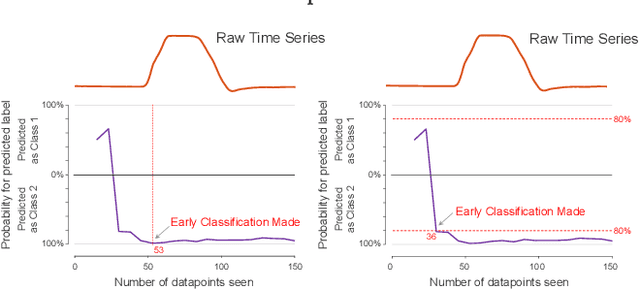
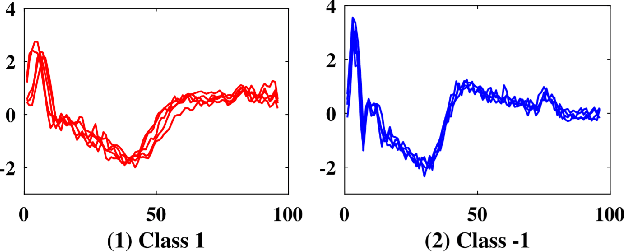
Since its introduction two decades ago, there has been increasing interest in the problem of early classification of time series. This problem generalizes classic time series classification to ask if we can classify a time series subsequence with sufficient accuracy and confidence after seeing only some prefix of a target pattern. The idea is that the earlier classification would allow us to take immediate action, in a domain in which some practical interventions are possible. For example, that intervention might be sounding an alarm or applying the brakes in an automobile. In this work, we make a surprising claim. In spite of the fact that there are dozens of papers on early classification of time series, it is not clear that any of them could ever work in a real-world setting. The problem is not with the algorithms per se but with the vague and underspecified problem description. Essentially all algorithms make implicit and unwarranted assumptions about the problem that will ensure that they will be plagued by false positives and false negatives even if their results suggested that they could obtain near-perfect results. We will explain our findings with novel insights and experiments and offer recommendations to the community.