 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Concept Search: Predicting Compositional Errors From Feature Geometry
Jun 11, 2026Humans cannot always intuit what scenarios are most challenging to LLMs. Hoping to capture challenging edge cases, developers either design problems to be difficult for humans or curate extensive benchmarks. What if we could instead anticipate which scenarios a model will fail on? In this paper, we use an LLM's representational geometry to predict which concept combinations it will fail on. We attribute this compositional failure to interference between salient features. In tasks that require systematic composition - toy programmatic settings, multihop reasoning, multilingual factual recall - we find that when a pair of concepts is encoded near-orthogonally, the model reliably composes them. When their linear encodings are close, producing interference, the model fails to compose them. Our method reliably anticipates failure modes across different compositional tasks, without evaluating specific inputs. These results lay the groundwork to use representational geometry to identify high-risk examples, construct targeted stress tests, and provide a scalable foundation for active learning in real-world deployment.
What do Language Models Learn and When? The Implicit Curriculum Hypothesis
Apr 09, 2026Large language models (LLMs) can perform remarkably complex tasks, yet the fine-grained details of how these capabilities emerge during pretraining remain poorly understood. Scaling laws on validation loss tell us how much a model improves with additional compute, but not what skills it acquires in which order. To remedy this, we propose the Implicit Curriculum Hypothesis: pretraining follows a compositional and predictable curriculum across models and data mixtures. We test this by designing a suite of simple, composable tasks spanning retrieval, morphological transformations, coreference, logical reasoning, and mathematics. Using these tasks, we track emergence points across four model families spanning sizes from 410M-13B parameters. We find that emergence orderings of when models reach fixed accuracy thresholds are strikingly consistent ($ρ= .81$ across 45 model pairs), and that composite tasks most often emerge after their component tasks. Furthermore, we find that this structure is encoded in model representations: tasks with similar function vector representations also tend to follow similar trajectories in training. By using the space of representations derived from our task set, we can effectively predict the training trajectories of simple held-out compositional tasks throughout the course of pretraining ($R^2 = .68$-$.84$ across models) without previously evaluating them. Together, these results suggest that pretraining is more structured than loss curves reveal: skills emerge in a compositional order that is consistent across models and readable from their internals.
FOL-Pretrain: A complexity annotated corpus of first-order logic
May 20, 2025



Transformer-based large language models (LLMs) have demonstrated remarkable reasoning capabilities such as coding and solving mathematical problems to commonsense inference. While these tasks vary in complexity, they all require models to integrate and compute over structured information. Despite recent efforts to reverse-engineer LLM behavior through controlled experiments, our understanding of how these models internalize and execute complex algorithms remains limited. Progress has largely been confined to small-scale studies or shallow tasks such as basic arithmetic and grammatical pattern matching. One barrier to deeper understanding is the nature of pretraining data -- vast, heterogeneous, and often poorly annotated, making it difficult to isolate mechanisms of reasoning. To bridge this gap, we introduce a large-scale, fully open, complexity-annotated dataset of first-order logic reasoning traces, designed to probe and analyze algorithmic reasoning in LLMs. The dataset consists of 3.5 billion tokens, including 8.8 million LLM-augmented, human-annotated examples and 7.5 million synthetically generated examples. Each synthetic example is verifiably correct, produced by a custom automated theorem solver, and accompanied by metadata tracing its algorithmic provenance. We aim to provide a scalable, interpretable artifact for studying how LLMs learn and generalize symbolic reasoning processes, paving the way for more transparent and targeted investigations into the algorithmic capabilities of modern models.
Causal Interventions on Causal Paths: Mapping GPT-2's Reasoning From Syntax to Semantics
Oct 28, 2024



While interpretability research has shed light on some internal algorithms utilized by transformer-based LLMs, reasoning in natural language, with its deep contextuality and ambiguity, defies easy categorization. As a result, formulating clear and motivating questions for circuit analysis that rely on well-defined in-domain and out-of-domain examples required for causal interventions is challenging. Although significant work has investigated circuits for specific tasks, such as indirect object identification (IOI), deciphering natural language reasoning through circuits remains difficult due to its inherent complexity. In this work, we take initial steps to characterize causal reasoning in LLMs by analyzing clear-cut cause-and-effect sentences like "I opened an umbrella because it started raining," where causal interventions may be possible through carefully crafted scenarios using GPT-2 small. Our findings indicate that causal syntax is localized within the first 2-3 layers, while certain heads in later layers exhibit heightened sensitivity to nonsensical variations of causal sentences. This suggests that models may infer reasoning by (1) detecting syntactic cues and (2) isolating distinct heads in the final layers that focus on semantic relationships.
SCORE: A framework for Self-Contradictory Reasoning Evaluation
Nov 16, 2023



Large language models (LLMs) have demonstrated impressive reasoning ability in various language-based tasks. Despite many proposed reasoning methods aimed at enhancing performance in downstream tasks, two fundamental questions persist: Does reasoning genuinely support predictions, and how reliable is the quality of reasoning? In this paper, we propose a framework \textsc{SCORE} to analyze how well LLMs can reason. Specifically, we focus on self-contradictory reasoning, where reasoning does not support the prediction. We find that LLMs often contradict themselves when performing reasoning tasks that involve contextual information and commonsense. The model may miss evidence or use shortcuts, thereby exhibiting self-contradictory behaviors. We also employ the Point-of-View (POV) method, which probes models to generate reasoning from multiple perspectives, as a diagnostic tool for further analysis. We find that though LLMs may appear to perform well in one-perspective settings, they fail to stabilize such behavior in multi-perspectives settings. Even for correct predictions, the reasoning may be messy and incomplete, and LLMs can easily be led astray from good reasoning. \textsc{SCORE}'s results underscore the lack of robustness required for trustworthy reasoning and the urgency for further research to establish best practices for a comprehensive evaluation of reasoning beyond accuracy-based metrics.
On Retrieval Augmentation and the Limitations of Language Model Training
Nov 16, 2023Augmenting a language model (LM) with $k$-nearest neighbors (kNN) retrieval on its training data alone can decrease its perplexity, though the underlying reasons for this remains elusive. In this work, we first rule out one previously posited possibility -- the "softmax bottleneck." We further identify the MLP hurdle phenomenon, where the final MLP layer in LMs may impede LM optimization early on. We explore memorization and generalization in language models with two new datasets, where advanced model like GPT-3.5-turbo find generalizing to irrelevant information in the training data challenging. However, incorporating kNN retrieval to vanilla GPT-2 117M can consistently improve performance in this setting.
GupShup: An Annotated Corpus for Abstractive Summarization of Open-Domain Code-Switched Conversations
Apr 17, 2021
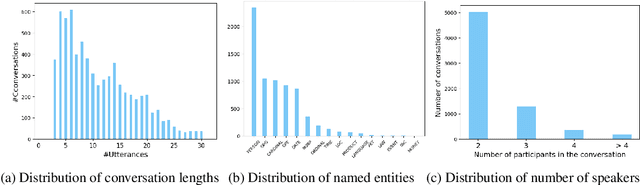
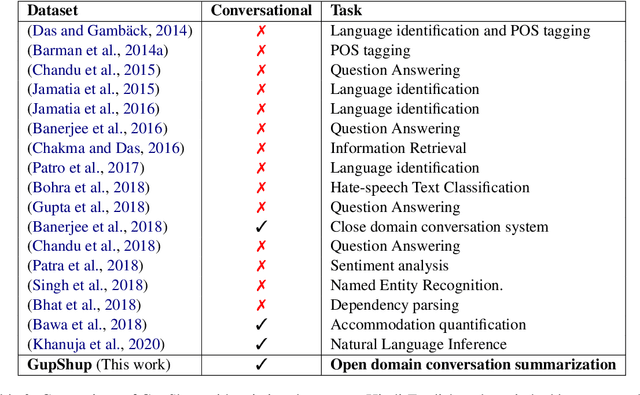

Code-switching is the communication phenomenon where speakers switch between different languages during a conversation. With the widespread adoption of conversational agents and chat platforms, code-switching has become an integral part of written conversations in many multi-lingual communities worldwide. This makes it essential to develop techniques for summarizing and understanding these conversations. Towards this objective, we introduce abstractive summarization of Hindi-English code-switched conversations and develop the first code-switched conversation summarization dataset - GupShup, which contains over 6,831 conversations in Hindi-English and their corresponding human-annotated summaries in English and Hindi-English. We present a detailed account of the entire data collection and annotation processes. We analyze the dataset using various code-switching statistics. We train state-of-the-art abstractive summarization models and report their performances using both automated metrics and human evaluation. Our results show that multi-lingual mBART and multi-view seq2seq models obtain the best performances on the new dataset