 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Contrastive Denoising Score for Text-guided Latent Diffusion Image Editing
Nov 30, 2023
With the remarkable advent of text-to-image diffusion models, image editing methods have become more diverse and continue to evolve. A promising recent approach in this realm is Delta Denoising Score (DDS) - an image editing technique based on Score Distillation Sampling (SDS) framework that leverages the rich generative prior of text-to-image diffusion models. However, relying solely on the difference between scoring functions is insufficient for preserving specific structural elements from the original image, a crucial aspect of image editing. Inspired by the similarity and importance differences between DDS and the contrastive learning for unpaired image-to-image translation (CUT), here we present an embarrassingly simple yet very powerful modification of DDS, called Contrastive Denoising Score (CDS), for latent diffusion models (LDM). Specifically, to enforce structural correspondence between the input and output while maintaining the controllability of contents, we introduce a straightforward approach to regulate structural consistency using CUT loss within the DDS framework. To calculate this loss, instead of employing auxiliary networks, we utilize the intermediate features of LDM, in particular, those from the self-attention layers, which possesses rich spatial information. Our approach enables zero-shot image-to-image translation and neural radiance field (NeRF) editing, achieving a well-balanced interplay between maintaining the structural details and transforming content. Qualitative results and comparisons demonstrates the effectiveness of our proposed method. Project page with code is available at https://hyelinnam.github.io/CDS/.
Perception of Misalignment States for Sky Survey Telescopes with the Digital Twin and the Deep Neural Networks
Nov 30, 2023Sky survey telescopes play a critical role in modern astronomy, but misalignment of their optical elements can introduce significant variations in point spread functions, leading to reduced data quality. To address this, we need a method to obtain misalignment states, aiding in the reconstruction of accurate point spread functions for data processing methods or facilitating adjustments of optical components for improved image quality. Since sky survey telescopes consist of many optical elements, they result in a vast array of potential misalignment states, some of which are intricately coupled, posing detection challenges. However, by continuously adjusting the misalignment states of optical elements, we can disentangle coupled states. Based on this principle, we propose a deep neural network to extract misalignment states from continuously varying point spread functions in different field of views. To ensure sufficient and diverse training data, we recommend employing a digital twin to obtain data for neural network training. Additionally, we introduce the state graph to store misalignment data and explore complex relationships between misalignment states and corresponding point spread functions, guiding the generation of training data from experiments. Once trained, the neural network estimates misalignment states from observation data, regardless of the impacts caused by atmospheric turbulence, noise, and limited spatial sampling rates in the detector. The method proposed in this paper could be used to provide prior information for the active optics system and the optical system alignment.
Entity-Aspect-Opinion-Sentiment Quadruple Extraction for Fine-grained Sentiment Analysis
Nov 28, 2023Product reviews often contain a large number of implicit aspects and object-attribute co-existence cases. Unfortunately, many existing studies in Aspect-Based Sentiment Analysis (ABSA) have overlooked this issue, which can make it difficult to extract opinions comprehensively and fairly. In this paper, we propose a new task called Entity-Aspect-Opinion-Sentiment Quadruple Extraction (EASQE), which aims to hierarchically decompose aspect terms into entities and aspects to avoid information loss, non-exclusive annotations, and opinion misunderstandings in ABSA tasks. To facilitate research in this new task, we have constructed four datasets (Res14-EASQE, Res15-EASQE, Res16-EASQE, and Lap14-EASQE) based on the SemEval Restaurant and Laptop datasets. We have also proposed a novel two-stage sequence-tagging based Trigger-Opinion framework as the baseline for the EASQE task. Empirical evaluations show that our Trigger-Opinion framework can generate satisfactory EASQE results and can also be applied to other ABSA tasks, significantly outperforming state-of-the-art methods. We have made the four datasets and source code of Trigger-Opinion publicly available to facilitate further research in this area.
HandyPriors: Physically Consistent Perception of Hand-Object Interactions with Differentiable Priors
Nov 28, 2023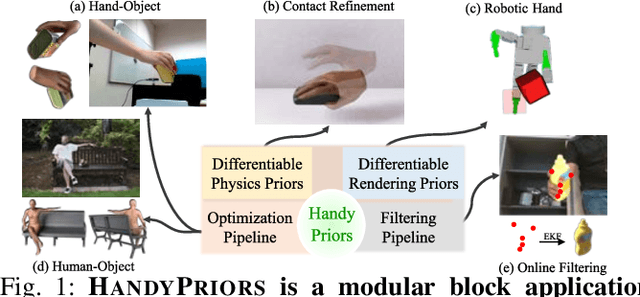
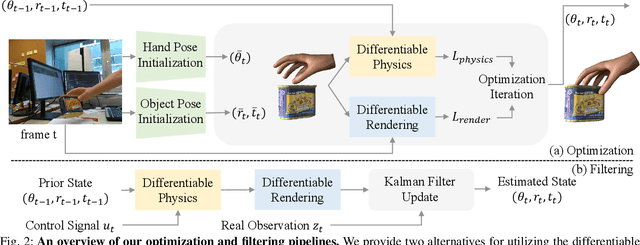
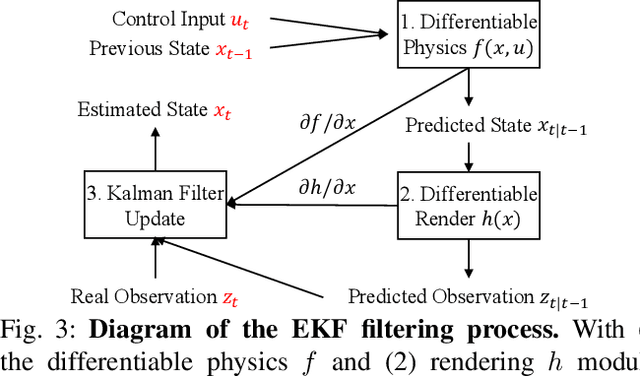

Various heuristic objectives for modeling hand-object interaction have been proposed in past work. However, due to the lack of a cohesive framework, these objectives often possess a narrow scope of applicability and are limited by their efficiency or accuracy. In this paper, we propose HandyPriors, a unified and general pipeline for pose estimation in human-object interaction scenes by leveraging recent advances in differentiable physics and rendering. Our approach employs rendering priors to align with input images and segmentation masks along with physics priors to mitigate penetration and relative-sliding across frames. Furthermore, we present two alternatives for hand and object pose estimation. The optimization-based pose estimation achieves higher accuracy, while the filtering-based tracking, which utilizes the differentiable priors as dynamics and observation models, executes faster. We demonstrate that HandyPriors attains comparable or superior results in the pose estimation task, and that the differentiable physics module can predict contact information for pose refinement. We also show that our approach generalizes to perception tasks, including robotic hand manipulation and human-object pose estimation in the wild.
StyleCap: Automatic Speaking-Style Captioning from Speech Based on Speech and Language Self-supervised Learning Models
Nov 28, 2023We propose StyleCap, a method to generate natural language descriptions of speaking styles appearing in speech. Although most of conventional techniques for para-/non-linguistic information recognition focus on the category classification or the intensity estimation of pre-defined labels, they cannot provide the reasoning of the recognition result in an interpretable manner. As a first step towards an end-to-end method for generating speaking-style prompts from speech, i.e., automatic speaking-style captioning, StyleCap uses paired data of speech and natural language descriptions to train neural networks that predict prefix vectors fed into a large language model (LLM)-based text decoder from a speech representation vector. We explore an appropriate text decoder and speech feature representation suitable for this new task. The experimental results demonstrate that our StyleCap leveraging richer LLMs for the text decoder, speech self-supervised learning (SSL) features, and sentence rephrasing augmentation improves the accuracy and diversity of generated speaking-style captions. Samples of speaking-style captions generated by our StyleCap are publicly available.
Utility Fairness in Contextual Dynamic Pricing with Demand Learning
Nov 28, 2023This paper introduces a novel contextual bandit algorithm for personalized pricing under utility fairness constraints in scenarios with uncertain demand, achieving an optimal regret upper bound. Our approach, which incorporates dynamic pricing and demand learning, addresses the critical challenge of fairness in pricing strategies. We first delve into the static full-information setting to formulate an optimal pricing policy as a constrained optimization problem. Here, we propose an approximation algorithm for efficiently and approximately computing the ideal policy. We also use mathematical analysis and computational studies to characterize the structures of optimal contextual pricing policies subject to fairness constraints, deriving simplified policies which lays the foundations of more in-depth research and extensions. Further, we extend our study to dynamic pricing problems with demand learning, establishing a non-standard regret lower bound that highlights the complexity added by fairness constraints. Our research offers a comprehensive analysis of the cost of fairness and its impact on the balance between utility and revenue maximization. This work represents a step towards integrating ethical considerations into algorithmic efficiency in data-driven dynamic pricing.
Pragmatic Radiology Report Generation
Nov 28, 2023When pneumonia is not found on a chest X-ray, should the report describe this negative observation or omit it? We argue that this question cannot be answered from the X-ray alone and requires a pragmatic perspective, which captures the communicative goal that radiology reports serve between radiologists and patients. However, the standard image-to-text formulation for radiology report generation fails to incorporate such pragmatic intents. Following this pragmatic perspective, we demonstrate that the indication, which describes why a patient comes for an X-ray, drives the mentions of negative observations and introduce indications as additional input to report generation. With respect to the output, we develop a framework to identify uninferable information from the image as a source of model hallucinations, and limit them by cleaning groundtruth reports. Finally, we use indications and cleaned groundtruth reports to develop pragmatic models, and show that they outperform existing methods not only in new pragmatics-inspired metrics (+4.3 Negative F1) but also in standard metrics (+6.3 Positive F1 and +11.0 BLEU-2).
A Short Overview of 6G V2X Communication Standards
Nov 28, 2023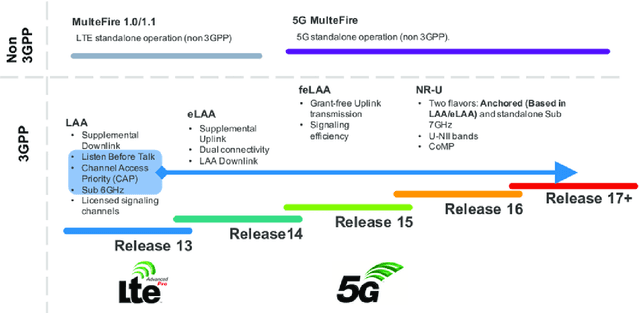
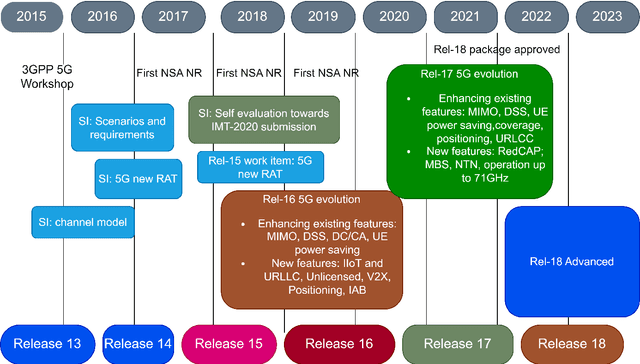
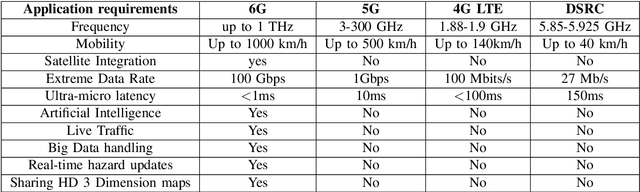
We are on the verge of a new age of linked autonomous cars with unheard-of user experiences, dramatically improved air quality and road safety, extremely varied transportation settings, and a plethora of cutting-edge apps. A substantially improved Vehicle-to-Everything (V2X) communication network that can simultaneously support massive hyper-fast, ultra-reliable, and low-latency information exchange is necessary to achieve this ambitious goal. These needs of the upcoming V2X are expected to be satisfied by the Sixth Generation (6G) communication system. In this article, we start by introducing the history of V2X communications by giving details on the current, developing, and future developments. We compare the applications of communication technologies such as Wi-Fi, LTE, 5G, and 6G. we focus on the new technologies for 6G V2X which are brain-vehicle interface, blocked-based V2X, and Machine Learning (ML). To achieve this, we provide a summary of the most recent ML developments in 6G vehicle networks. we discuss the security challenges of 6G V2X. We address the strengths, open challenges, development, and improving areas of further study in this field.
Multi-Channel Cross Modal Detection of Synthetic Face Images
Nov 28, 2023Synthetically generated face images have shown to be indistinguishable from real images by humans and as such can lead to a lack of trust in digital content as they can, for instance, be used to spread misinformation. Therefore, the need to develop algorithms for detecting entirely synthetic face images is apparent. Of interest are images generated by state-of-the-art deep learning-based models, as these exhibit a high level of visual realism. Recent works have demonstrated that detecting such synthetic face images under realistic circumstances remains difficult as new and improved generative models are proposed with rapid speed and arbitrary image post-processing can be applied. In this work, we propose a multi-channel architecture for detecting entirely synthetic face images which analyses information both in the frequency and visible spectra using Cross Modal Focal Loss. We compare the proposed architecture with several related architectures trained using Binary Cross Entropy and show in cross-model experiments that the proposed architecture supervised using Cross Modal Focal Loss, in general, achieves most competitive performance.
Towards Full-scene Domain Generalization in Multi-agent Collaborative Bird's Eye View Segmentation for Connected and Autonomous Driving
Nov 28, 2023Collaborative perception has recently gained significant attention in autonomous driving, improving perception quality by enabling the exchange of additional information among vehicles. However, deploying collaborative perception systems can lead to domain shifts due to diverse environmental conditions and data heterogeneity among connected and autonomous vehicles (CAVs). To address these challenges, we propose a unified domain generalization framework applicable in both training and inference stages of collaborative perception. In the training phase, we introduce an Amplitude Augmentation (AmpAug) method to augment low-frequency image variations, broadening the model's ability to learn across various domains. We also employ a meta-consistency training scheme to simulate domain shifts, optimizing the model with a carefully designed consistency loss to encourage domain-invariant representations. In the inference phase, we introduce an intra-system domain alignment mechanism to reduce or potentially eliminate the domain discrepancy among CAVs prior to inference. Comprehensive experiments substantiate the effectiveness of our method in comparison with the existing state-of-the-art works. Code will be released at https://github.com/DG-CAVs/DG-CoPerception.git.