 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausaLab: A Scalable Environment for Interactive Causal Discovery Toward AI Scientists
May 28, 2026We introduce CausaLab, a scalable environment for evaluating interactive causal discovery by LLM agents. Unlike prior evaluations, CausaLab evaluates both whether an agent can solve a problem using causal evidence and whether its answer is grounded in a faithful recovered causal mechanism. Each episode places an agent in a synthetic laboratory: it receives prior measurement records, intervenes on a manipulator crystal, and predicts the resonance frequency of a held-out reactor crystal governed by the same mechanism. The hidden data-generating process is a randomly sampled structural causal model (SCM), so success requires recovering both a causal graph and structural equations rather than recalling prior knowledge. Experiments show a persistent gap between prediction and mechanism recovery: in the purely observational 6-node setting, GPT-5.2-high reaches 92% task accuracy but only 0.471 all-edge $F_1$. Mixed observation-intervention strategies improve structural fidelity, while pure intervention remains difficult even for strong agents. We identify premature stopping as a major weakness and show that consistency verification mitigates it. CausaLab therefore separates predictive success from causal understanding and exposes current LLM agents' limits as experimental causal reasoners.
Towards a Universal Causal Reasoner
May 24, 2026Despite the importance of causal reasoning, training LLMs to reason causally remains underexplored. Existing data efforts mostly focus on benchmarking LLMs on specific aspects of causality, making them less suitable for training generalizable causal reasoners. To address this, we propose UniCo, a data generation framework that both (1) addresses 18 causal query types across Pearl's Causal Ladder and (2) translates natively symbolic examples into code and natural language forms to simulate real-world use cases where causal terms are not explicitly specified. To ensure data quality, UniCo grounds answers with exact causal inference and filters cases with reasoning shortcuts. Upon supervised finetuning with 66.6K UniCo-generated instances, Qwen3-4B, Qwen3-8B and Olmo-3-7B-Instruct achieve an average of 22.9% improvements across all 18 in-distribution query types, and 8.1% over state-of-the-art causal data generation frameworks on 7 established causal benchmarks outside the training distribution. More importantly, in real-world medical understanding, legal decision, and tabular reasoning, UniCo-trained models consistently display more faithful reasoning traces, outperforming the base models by an average of 20.2% in faithfulness metrics. These suggest that causality-centered training not only strengthens causal reasoning, but also equips LLMs with a causal mindset in general reasoning tasks.
Personalized Benchmarking: Evaluating LLMs by Individual Preferences
Apr 21, 2026With the rise in capabilities of large language models (LLMs) and their deployment in real-world tasks, evaluating LLM alignment with human preferences has become an important challenge. Current benchmarks average preferences across all users to compute aggregate ratings, overlooking individual user preferences when establishing model rankings. Since users have varying preferences in different contexts, we call for personalized LLM benchmarks that rank models according to individual needs. We compute personalized model rankings using ELO ratings and Bradley-Terry coefficients for 115 active Chatbot Arena users and analyze how user query characteristics (topics and writing style) relate to LLM ranking variations. We demonstrate that individual rankings of LLM models diverge dramatically from aggregate LLM rankings, with Bradley-Terry correlations averaging only $ρ= 0.04$ (57\% of users show near-zero or negative correlation) and ELO ratings showing moderate correlation ($ρ= 0.43$). Through topic modeling and style analysis, we find users exhibit substantial heterogeneity in topical interests and communication styles, influencing their model preferences. We further show that a compact combination of topic and style features provides a useful feature space for predicting user-specific model rankings. Our results provide strong quantitative evidence that aggregate benchmarks fail to capture individual preferences for most users, and highlight the importance of developing personalized benchmarks that rank LLM models according to individual user preferences.
Automatically Generating Hard Math Problems from Hypothesis-Driven Error Analysis
Apr 06, 2026Numerous math benchmarks exist to evaluate LLMs' mathematical capabilities. However, most involve extensive manual effort and are difficult to scale. Consequently, they cannot keep pace with LLM development or easily provide new instances to mitigate overfitting. Some researchers have proposed automatic benchmark generation methods, but few focus on identifying the specific math concepts and skills on which LLMs are error-prone, and most can only generate category-specific benchmarks. To address these limitations, we propose a new math benchmark generation pipeline that uses AI-generated hypotheses to identify the specific math concepts and skills that LLMs struggle with, and then generates new benchmark problems targeting these weaknesses. Experiments show that hypothesis accuracy positively correlates with the difficulty of the generated problems: problems generated from the most accurate hypotheses reduce Llama-3.3-70B-Instruct's accuracy to as low as 45%, compared to 77% on the original MATH benchmark. Furthermore, our pipeline is highly adaptable and can be applied beyond math to explore a wide range of LLM capabilities, making it a valuable tool for investigating how LLMs perform across different domains.
Executable Counterfactuals: Improving LLMs' Causal Reasoning Through Code
Oct 02, 2025Counterfactual reasoning, a hallmark of intelligence, consists of three steps: inferring latent variables from observations (abduction), constructing alternatives (interventions), and predicting their outcomes (prediction). This skill is essential for advancing LLMs' causal understanding and expanding their applications in high-stakes domains such as scientific research. However, existing efforts in assessing LLM's counterfactual reasoning capabilities tend to skip the abduction step, effectively reducing to interventional reasoning and leading to overestimation of LLM performance. To address this, we introduce executable counterfactuals, a novel framework that operationalizes causal reasoning through code and math problems. Our framework explicitly requires all three steps of counterfactual reasoning and enables scalable synthetic data creation with varying difficulty, creating a frontier for evaluating and improving LLM's reasoning. Our results reveal substantial drop in accuracy (25-40%) from interventional to counterfactual reasoning for SOTA models like o4-mini and Claude-4-Sonnet. To address this gap, we construct a training set comprising counterfactual code problems having if-else condition and test on out-of-domain code structures (e.g. having while-loop); we also test whether a model trained on code would generalize to counterfactual math word problems. While supervised finetuning on stronger models' reasoning traces improves in-domain performance of Qwen models, it leads to a decrease in accuracy on OOD tasks such as counterfactual math problems. In contrast, reinforcement learning induces the core cognitive behaviors and generalizes to new domains, yielding gains over the base model on both code (improvement of 1.5x-2x) and math problems. Analysis of the reasoning traces reinforces these findings and highlights the promise of RL for improving LLMs' counterfactual reasoning.
From Feedback to Checklists: Grounded Evaluation of AI-Generated Clinical Notes
Jul 23, 2025



AI-generated clinical notes are increasingly used in healthcare, but evaluating their quality remains a challenge due to high subjectivity and limited scalability of expert review. Existing automated metrics often fail to align with real-world physician preferences. To address this, we propose a pipeline that systematically distills real user feedback into structured checklists for note evaluation. These checklists are designed to be interpretable, grounded in human feedback, and enforceable by LLM-based evaluators. Using deidentified data from over 21,000 clinical encounters, prepared in accordance with the HIPAA safe harbor standard, from a deployed AI medical scribe system, we show that our feedback-derived checklist outperforms baseline approaches in our offline evaluations in coverage, diversity, and predictive power for human ratings. Extensive experiments confirm the checklist's robustness to quality-degrading perturbations, significant alignment with clinician preferences, and practical value as an evaluation methodology. In offline research settings, the checklist can help identify notes likely to fall below our chosen quality thresholds.
AbsenceBench: Language Models Can't Tell What's Missing
Jun 13, 2025



Large language models (LLMs) are increasingly capable of processing long inputs and locating specific information within them, as evidenced by their performance on the Needle in a Haystack (NIAH) test. However, while models excel at recalling surprising information, they still struggle to identify clearly omitted information. We introduce AbsenceBench to assesses LLMs' capacity to detect missing information across three domains: numerical sequences, poetry, and GitHub pull requests. AbsenceBench asks models to identify which pieces of a document were deliberately removed, given access to both the original and edited contexts. Despite the apparent straightforwardness of these tasks, our experiments reveal that even state-of-the-art models like Claude-3.7-Sonnet achieve only 69.6% F1-score with a modest average context length of 5K tokens. Our analysis suggests this poor performance stems from a fundamental limitation: Transformer attention mechanisms cannot easily attend to "gaps" in documents since these absences don't correspond to any specific keys that can be attended to. Overall, our results and analysis provide a case study of the close proximity of tasks where models are already superhuman (NIAH) and tasks where models breakdown unexpectedly (AbsenceBench).
The Curious Language Model: Strategic Test-Time Information Acquisition
Jun 10, 2025


Decision-makers often possess insufficient information to render a confident decision. In these cases, the decision-maker can often undertake actions to acquire the necessary information about the problem at hand, e.g., by consulting knowledgeable authorities or by conducting experiments. Importantly, different levers of information acquisition come with different costs, posing the challenge of selecting the actions that are both informative and cost-effective. In this work, we propose CuriosiTree, a heuristic-based, test-time policy for zero-shot information acquisition in large language models (LLMs). CuriosiTree employs a greedy tree search to estimate the expected information gain of each action and strategically chooses actions based on a balance of anticipated information gain and associated cost. Empirical validation in a clinical diagnosis simulation shows that CuriosiTree enables cost-effective integration of heterogenous sources of information, and outperforms baseline action selection strategies in selecting action sequences that enable accurate diagnosis.
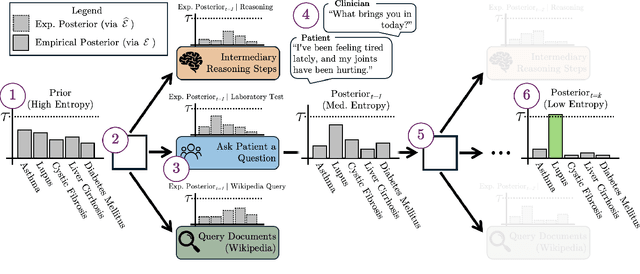
CLEAR: A Clinically-Grounded Tabular Framework for Radiology Report Evaluation
May 22, 2025
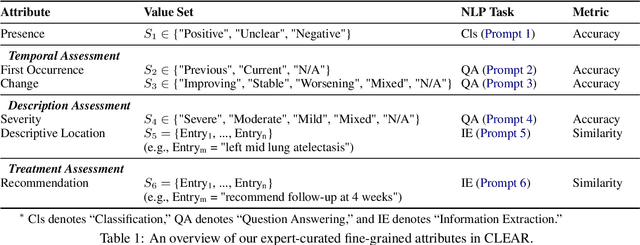
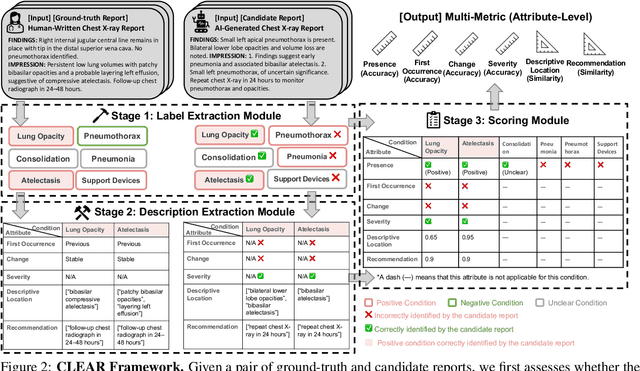
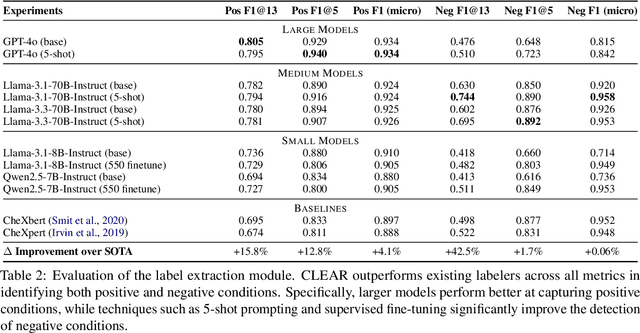
Existing metrics often lack the granularity and interpretability to capture nuanced clinical differences between candidate and ground-truth radiology reports, resulting in suboptimal evaluation. We introduce a Clinically-grounded tabular framework with Expert-curated labels and Attribute-level comparison for Radiology report evaluation (CLEAR). CLEAR not only examines whether a report can accurately identify the presence or absence of medical conditions, but also assesses whether it can precisely describe each positively identified condition across five key attributes: first occurrence, change, severity, descriptive location, and recommendation. Compared to prior works, CLEAR's multi-dimensional, attribute-level outputs enable a more comprehensive and clinically interpretable evaluation of report quality. Additionally, to measure the clinical alignment of CLEAR, we collaborate with five board-certified radiologists to develop CLEAR-Bench, a dataset of 100 chest X-ray reports from MIMIC-CXR, annotated across 6 curated attributes and 13 CheXpert conditions. Our experiments show that CLEAR achieves high accuracy in extracting clinical attributes and provides automated metrics that are strongly aligned with clinical judgment.
Concept Incongruence: An Exploration of Time and Death in Role Playing
May 20, 2025Consider this prompt "Draw a unicorn with two horns". Should large language models (LLMs) recognize that a unicorn has only one horn by definition and ask users for clarifications, or proceed to generate something anyway? We introduce concept incongruence to capture such phenomena where concept boundaries clash with each other, either in user prompts or in model representations, often leading to under-specified or mis-specified behaviors. In this work, we take the first step towards defining and analyzing model behavior under concept incongruence. Focusing on temporal boundaries in the Role-Play setting, we propose three behavioral metrics--abstention rate, conditional accuracy, and answer rate--to quantify model behavior under incongruence due to the role's death. We show that models fail to abstain after death and suffer from an accuracy drop compared to the Non-Role-Play setting. Through probing experiments, we identify two main causes: (i) unreliable encoding of the "death" state across different years, leading to unsatisfactory abstention behavior, and (ii) role playing causes shifts in the model's temporal representations, resulting in accuracy drops. We leverage these insights to improve consistency in the model's abstention and answer behaviors. Our findings suggest that concept incongruence leads to unexpected model behaviors and point to future directions on improving model behavior under concept incongruence.