 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Revisiting the Optimality of Word Lengths
Dec 06, 2023
Zipf (1935) posited that wordforms are optimized to minimize utterances' communicative costs. Under the assumption that cost is given by an utterance's length, he supported this claim by showing that words' lengths are inversely correlated with their frequencies. Communicative cost, however, can be operationalized in different ways. Piantadosi et al. (2011) claim that cost should be measured as the distance between an utterance's information rate and channel capacity, which we dub the channel capacity hypothesis (CCH) here. Following this logic, they then proposed that a word's length should be proportional to the expected value of its surprisal (negative log-probability in context). In this work, we show that Piantadosi et al.'s derivation does not minimize CCH's cost, but rather a lower bound, which we term CCH-lower. We propose a novel derivation, suggesting an improved way to minimize CCH's cost. Under this method, we find that a language's word lengths should instead be proportional to the surprisal's expectation plus its variance-to-mean ratio. Experimentally, we compare these three communicative cost functions: Zipf's, CCH-lower , and CCH. Across 13 languages and several experimental settings, we find that length is better predicted by frequency than either of the other hypotheses. In fact, when surprisal's expectation, or expectation plus variance-to-mean ratio, is estimated using better language models, it leads to worse word length predictions. We take these results as evidence that Zipf's longstanding hypothesis holds.
TransNeXt: Robust Foveal Visual Perception for Vision Transformers
Nov 28, 2023Due to the depth degradation effect in residual connections, many efficient Vision Transformers models that rely on stacking layers for information exchange often fail to form sufficient information mixing, leading to unnatural visual perception. To address this issue, in this paper, we propose Aggregated Attention, a biomimetic design-based token mixer that simulates biological foveal vision and continuous eye movement while enabling each token on the feature map to have a global perception. Furthermore, we incorporate learnable tokens that interact with conventional queries and keys, which further diversifies the generation of affinity matrices beyond merely relying on the similarity between queries and keys. Our approach does not rely on stacking for information exchange, thus effectively avoiding depth degradation and achieving natural visual perception. Additionally, we propose Convolutional GLU, a channel mixer that bridges the gap between GLU and SE mechanism, which empowers each token to have channel attention based on its nearest neighbor image features, enhancing local modeling capability and model robustness. We combine aggregated attention and convolutional GLU to create a new visual backbone called TransNeXt. Extensive experiments demonstrate that our TransNeXt achieves state-of-the-art performance across multiple model sizes. At a resolution of $224^2$, TransNeXt-Tiny attains an ImageNet accuracy of 84.0%, surpassing ConvNeXt-B with 69% fewer parameters. Our TransNeXt-Base achieves an ImageNet accuracy of 86.2% and an ImageNet-A accuracy of 61.6% at a resolution of $384^2$, a COCO object detection mAP of 57.1, and an ADE20K semantic segmentation mIoU of 54.7.
Releasing the CRaQAn (Coreference Resolution in Question-Answering): An open-source dataset and dataset creation methodology using instruction-following models
Nov 27, 2023Instruction-following language models demand robust methodologies for information retrieval to augment instructions for question-answering applications. A primary challenge is the resolution of coreferences in the context of chunking strategies for long documents. The critical barrier to experimentation of handling coreferences is a lack of open source datasets, specifically in question-answering tasks that require coreference resolution. In this work we present our Coreference Resolution in Question-Answering (CRaQAn) dataset, an open-source dataset that caters to the nuanced information retrieval requirements of coreference resolution in question-answering tasks by providing over 250 question-answer pairs containing coreferences. To develop this dataset, we developed a novel approach for creating high-quality datasets using an instruction-following model (GPT-4) and a Recursive Criticism and Improvement Loop.
Generalized Label-Efficient 3D Scene Parsing via Hierarchical Feature Aligned Pre-Training and Region-Aware Fine-tuning
Dec 01, 2023Deep neural network models have achieved remarkable progress in 3D scene understanding while trained in the closed-set setting and with full labels. However, the major bottleneck for current 3D recognition approaches is that they do not have the capacity to recognize any unseen novel classes beyond the training categories in diverse kinds of real-world applications. In the meantime, current state-of-the-art 3D scene understanding approaches primarily require high-quality labels to train neural networks, which merely perform well in a fully supervised manner. This work presents a generalized and simple framework for dealing with 3D scene understanding when the labeled scenes are quite limited. To extract knowledge for novel categories from the pre-trained vision-language models, we propose a hierarchical feature-aligned pre-training and knowledge distillation strategy to extract and distill meaningful information from large-scale vision-language models, which helps benefit the open-vocabulary scene understanding tasks. To leverage the boundary information, we propose a novel energy-based loss with boundary awareness benefiting from the region-level boundary predictions. To encourage latent instance discrimination and to guarantee efficiency, we propose the unsupervised region-level semantic contrastive learning scheme for point clouds, using confident predictions of the neural network to discriminate the intermediate feature embeddings at multiple stages. Extensive experiments with both indoor and outdoor scenes demonstrated the effectiveness of our approach in both data-efficient learning and open-world few-shot learning. All codes, models, and data are made publicly available at: https://drive.google.com/drive/folders/1M58V-PtR8DBEwD296zJkNg_m2qq-MTAP?usp=sharing.
ESM-NBR: fast and accurate nucleic acid-binding residue prediction via protein language model feature representation and multi-task learning
Dec 01, 2023Protein-nucleic acid interactions play a very important role in a variety of biological activities. Accurate identification of nucleic acid-binding residues is a critical step in understanding the interaction mechanisms. Although many computationally based methods have been developed to predict nucleic acid-binding residues, challenges remain. In this study, a fast and accurate sequence-based method, called ESM-NBR, is proposed. In ESM-NBR, we first use the large protein language model ESM2 to extract discriminative biological properties feature representation from protein primary sequences; then, a multi-task deep learning model composed of stacked bidirectional long short-term memory (BiLSTM) and multi-layer perceptron (MLP) networks is employed to explore common and private information of DNA- and RNA-binding residues with ESM2 feature as input. Experimental results on benchmark data sets demonstrate that the prediction performance of ESM2 feature representation comprehensively outperforms evolutionary information-based hidden Markov model (HMM) features. Meanwhile, the ESM-NBR obtains the MCC values for DNA-binding residues prediction of 0.427 and 0.391 on two independent test sets, which are 18.61 and 10.45% higher than those of the second-best methods, respectively. Moreover, by completely discarding the time-cost multiple sequence alignment process, the prediction speed of ESM-NBR far exceeds that of existing methods (5.52s for a protein sequence of length 500, which is about 16 times faster than the second-fastest method). A user-friendly standalone package and the data of ESM-NBR are freely available for academic use at: https://github.com/wwzll123/ESM-NBR.
A knowledge-based data-driven (KBDD) framework for all-day identification of cloud types using satellite remote sensing
Dec 01, 2023Cloud types, as a type of meteorological data, are of particular significance for evaluating changes in rainfall, heatwaves, water resources, floods and droughts, food security and vegetation cover, as well as land use. In order to effectively utilize high-resolution geostationary observations, a knowledge-based data-driven (KBDD) framework for all-day identification of cloud types based on spectral information from Himawari-8/9 satellite sensors is designed. And a novel, simple and efficient network, named CldNet, is proposed. Compared with widely used semantic segmentation networks, including SegNet, PSPNet, DeepLabV3+, UNet, and ResUnet, our proposed model CldNet with an accuracy of 80.89+-2.18% is state-of-the-art in identifying cloud types and has increased by 32%, 46%, 22%, 2%, and 39%, respectively. With the assistance of auxiliary information (e.g., satellite zenith/azimuth angle, solar zenith/azimuth angle), the accuracy of CldNet-W using visible and near-infrared bands and CldNet-O not using visible and near-infrared bands on the test dataset is 82.23+-2.14% and 73.21+-2.02%, respectively. Meanwhile, the total parameters of CldNet are only 0.46M, making it easy for edge deployment. More importantly, the trained CldNet without any fine-tuning can predict cloud types with higher spatial resolution using satellite spectral data with spatial resolution 0.02{\deg}*0.02{\deg}, which indicates that CldNet possesses a strong generalization ability. In aggregate, the KBDD framework using CldNet is a highly effective cloud-type identification system capable of providing a high-fidelity, all-day, spatiotemporal cloud-type database for many climate assessment fields.
FedBayes: A Zero-Trust Federated Learning Aggregation to Defend Against Adversarial Attacks
Dec 04, 2023Federated learning has created a decentralized method to train a machine learning model without needing direct access to client data. The main goal of a federated learning architecture is to protect the privacy of each client while still contributing to the training of the global model. However, the main advantage of privacy in federated learning is also the easiest aspect to exploit. Without being able to see the clients' data, it is difficult to determine the quality of the data. By utilizing data poisoning methods, such as backdoor or label-flipping attacks, or by sending manipulated information about their data back to the server, malicious clients are able to corrupt the global model and degrade performance across all clients within a federation. Our novel aggregation method, FedBayes, mitigates the effect of a malicious client by calculating the probabilities of a client's model weights given to the prior model's weights using Bayesian statistics. Our results show that this approach negates the effects of malicious clients and protects the overall federation.
PixelLM: Pixel Reasoning with Large Multimodal Model
Dec 04, 2023While large multimodal models (LMMs) have achieved remarkable progress, generating pixel-level masks for image reasoning tasks involving multiple open-world targets remains a challenge. To bridge this gap, we introduce PixelLM, an effective and efficient LMM for pixel-level reasoning and understanding. Central to PixelLM is a novel, lightweight pixel decoder and a comprehensive segmentation codebook. The decoder efficiently produces masks from the hidden embeddings of the codebook tokens, which encode detailed target-relevant information. With this design, PixelLM harmonizes with the structure of popular LMMs and avoids the need for additional costly segmentation models. Furthermore, we propose a target refinement loss to enhance the model's ability to differentiate between multiple targets, leading to substantially improved mask quality. To advance research in this area, we construct MUSE, a high-quality multi-target reasoning segmentation benchmark. PixelLM excels across various pixel-level image reasoning and understanding tasks, outperforming well-established methods in multiple benchmarks, including MUSE, single- and multi-referring segmentation. Comprehensive ablations confirm the efficacy of each proposed component. All code, models, and datasets will be publicly available.
3D Face Reconstruction with the Geometric Guidance of Facial Part Segmentation
Dec 04, 2023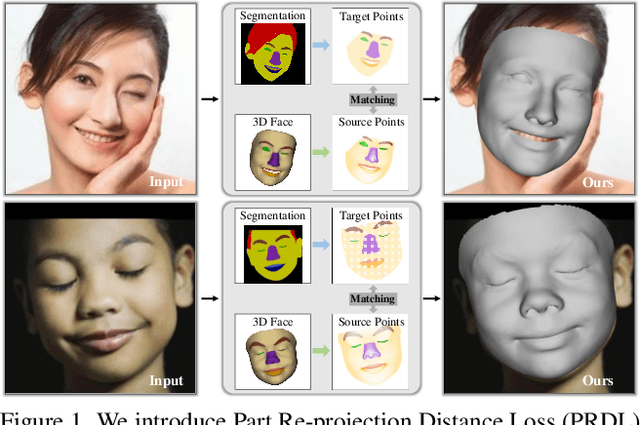
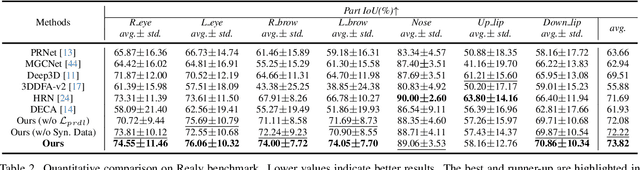
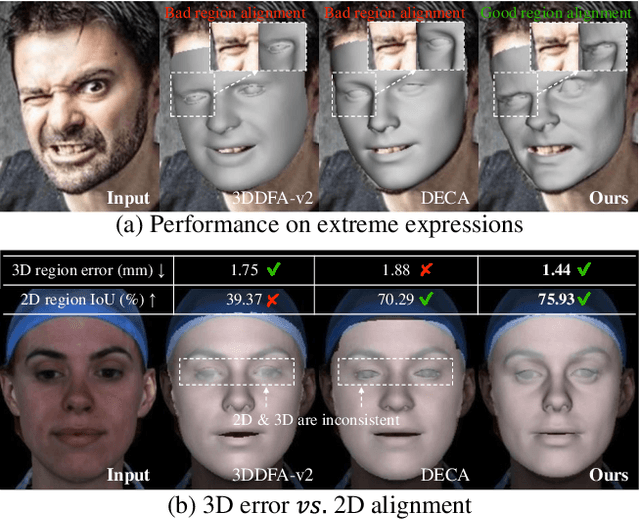
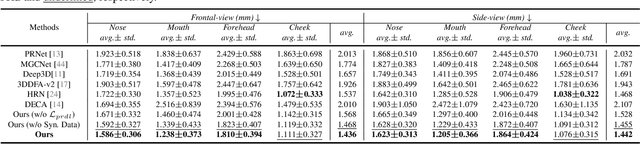
3D Morphable Models (3DMMs) provide promising 3D face reconstructions in various applications. However, existing methods struggle to reconstruct faces with extreme expressions due to deficiencies in supervisory signals, such as sparse or inaccurate landmarks. Segmentation information contains effective geometric contexts for face reconstruction. Certain attempts intuitively depend on differentiable renderers to compare the rendered silhouettes of reconstruction with segmentation, which is prone to issues like local optima and gradient instability. In this paper, we fully utilize the facial part segmentation geometry by introducing Part Re-projection Distance Loss (PRDL). Specifically, PRDL transforms facial part segmentation into 2D points and re-projects the reconstruction onto the image plane. Subsequently, by introducing grid anchors and computing different statistical distances from these anchors to the point sets, PRDL establishes geometry descriptors to optimize the distribution of the point sets for face reconstruction. PRDL exhibits a clear gradient compared to the renderer-based methods and presents state-of-the-art reconstruction performance in extensive quantitative and qualitative experiments. The project will be publicly available.
DiffusionPCR: Diffusion Models for Robust Multi-Step Point Cloud Registration
Dec 05, 2023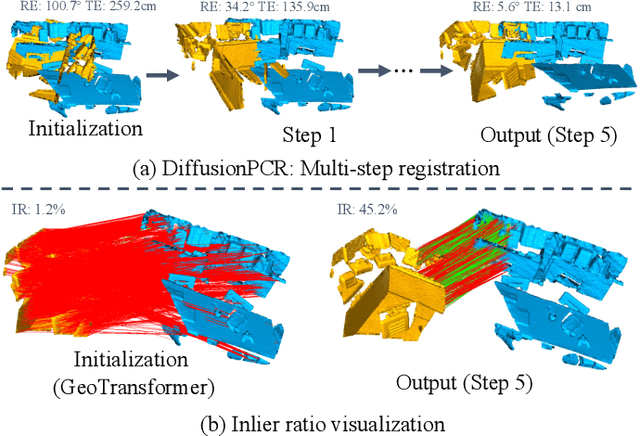
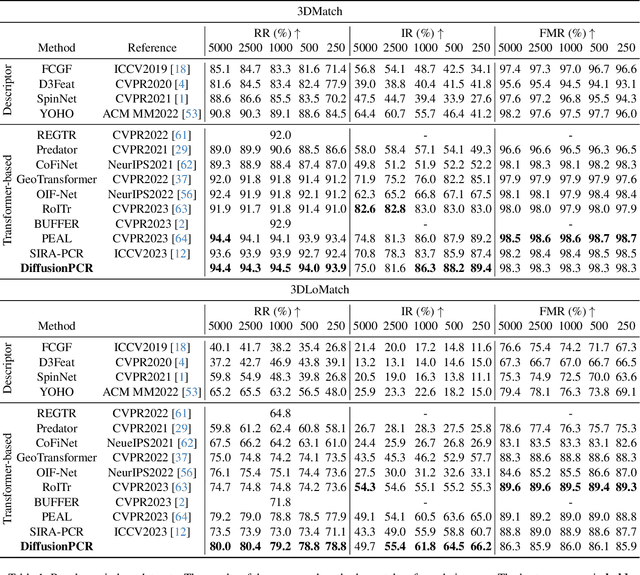
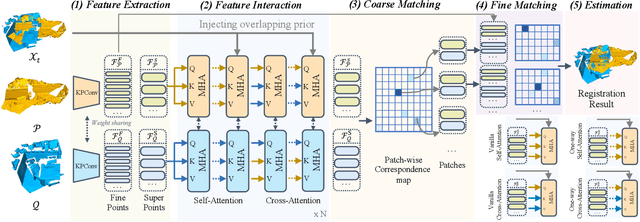
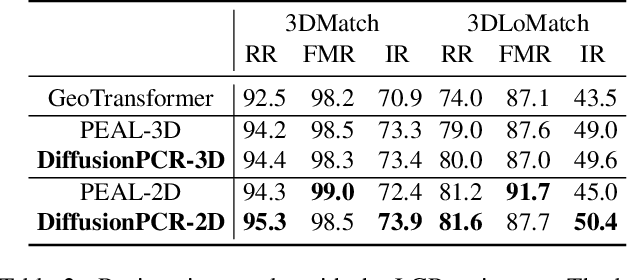
Point Cloud Registration (PCR) estimates the relative rigid transformation between two point clouds. We propose formulating PCR as a denoising diffusion probabilistic process, mapping noisy transformations to the ground truth. However, using diffusion models for PCR has nontrivial challenges, such as adapting a generative model to a discriminative task and leveraging the estimated nonlinear transformation from the previous step. Instead of training a diffusion model to directly map pure noise to ground truth, we map the predictions of an off-the-shelf PCR model to ground truth. The predictions of off-the-shelf models are often imperfect, especially in challenging cases where the two points clouds have low overlap, and thus could be seen as noisy versions of the real rigid transformation. In addition, we transform the rotation matrix into a spherical linear space for interpolation between samples in the forward process, and convert rigid transformations into auxiliary information to implicitly exploit last-step estimations in the reverse process. As a result, conditioned on time step, the denoising model adapts to the increasing accuracy across steps and refines registrations. Our extensive experiments showcase the effectiveness of our DiffusionPCR, yielding state-of-the-art registration recall rates (95.3%/81.6%) on 3DMatch and 3DLoMatch. The code will be made public upon publication.