 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Before You Act -- A Neurocognitive Governance Model for Autonomous AI Agents
Apr 28, 2026The rapid deployment of autonomous AI agents across enterprise, healthcare, and safety-critical environments has created a fundamental governance gap. Existing approaches, runtime guardrails, training-time alignment, and post-hoc auditing treat governance as an external constraint rather than an internalized behavioral principle, leaving agents vulnerable to unsafe and irreversible actions. We address this gap by drawing on how humans self-govern naturally: before acting, humans engage deliberate cognitive processes grounded in executive function, inhibitory control, and internalized organizational rules to evaluate whether an intended action is permissible, requires modification, or demands escalation. This paper proposes a neurocognitive governance framework that formally maps this human self-governance process to LLM-driven agent reasoning, establishing a structural parallel between the human brain and the large language model as the cognitive core of an agent. We formalize a Pre-Action Governance Reasoning Loop (PAGRL) in which agents consult a four-layer governance rule set: global, workflow-specific, agent-specific, and situational before every consequential action, mirroring how human organizations structure compliance hierarchies across enterprise, department, and role levels. Implemented on a production-grade retail supply chain workflow, the framework achieves 95% compliance accuracy and zero false escalations to human oversight, demonstrating that embedding governance into agent reasoning produces more consistent, explainable, and auditable compliance than external enforcement. This work offers a principled foundation for autonomous AI agents that govern themselves the way humans do: not because rules are imposed upon them, but because deliberation is embedded in how they think.
GlobalCY I: A JAX Framework for Globally Defined and Symmetry-Aware Neural Kähler Potentials
Apr 13, 2026We present \emph{GlobalCY}, a JAX-based framework for globally defined and symmetry-aware neural Kähler-potential models on projective hypersurface Calabi--Yau geometries. The central problem is that local-input neural Kähler-potential models can train successfully while still failing the geometry-sensitive diagnostics that matter in hard quartic regimes, especially near singular and near-singular members of the Cefalú family. To study this, we compare three model families -- a local-input baseline, a globally defined invariant model, and a symmetry-aware global model -- on the hard Cefalú cases $λ=0.75$ and $λ=1.0$ using a fixed multi-seed protocol and a geometry-aware diagnostic suite. In this benchmark, the globally defined invariant model is the strongest overall family, outperforming the local baseline on the two clearest geometric comparison metrics, negative-eigenvalue frequency and projective-invariance drift, in both cases. The gains are strongest at $λ=0.75$, while $λ=1.0$ remains more difficult. The current symmetry-aware model improves projective-invariance drift relative to the local baseline, but does not yet surpass the plain global invariant model. These results show that global invariant structure is a meaningful architectural constraint for learned Kähler-potential modeling in hard quartic Calabi--Yau settings.
Flowr -- Scaling Up Retail Supply Chain Operations Through Agentic AI in Large Scale Supermarket Chains
Apr 07, 2026Retail supply chain operations in supermarket chains involve continuous, high-volume manual workflows spanning demand forecasting, procurement, supplier coordination, and inventory replenishment, processes that are repetitive, decision-intensive, and difficult to scale without significant human effort. Despite growing investment in data analytics, the decision-making and coordination layers of these workflows remain predominantly manual, reactive, and fragmented across outlets, distribution centers, and supplier networks. This paper introduces Flowr, a novel agentic AI framework for automating end-to-end retail supply chain workflows in large-scale supermarket operations. Flowr systematically decomposes manual supply chain operations into specialized AI agents, each responsible for a clearly defined cognitive role, enabling automation of processes previously dependent on continuous human coordination. To ensure task accuracy and adherence to responsible AI principles, the framework employs a consortium of fine-tuned, domain-specialized large language models coordinated by a central reasoning LLM. Central to the framework is a human-in-the-loop orchestration model in which supply chain managers supervise and intervene across workflow stages via a Model Context Protocol (MCP)-enabled interface, preserving accountability and organizational control. Evaluation demonstrates that Flowr significantly reduces manual coordination overhead, improves demand-supply alignment, and enables proactive exception handling at a scale unachievable through manual processes. The framework was validated in collaboration with a large-scale supermarket chain and is domain-independent, offering a generalizable blueprint for agentic AI-driven supply chain automation across large-scale enterprise settings.
AI Trust OS -- A Continuous Governance Framework for Autonomous AI Observability and Zero-Trust Compliance in Enterprise Environments
Apr 06, 2026The accelerating adoption of large language models, retrieval-augmented generation pipelines, and multi-agent AI workflows has created a structural governance crisis. Organizations cannot govern what they cannot see, and existing compliance methodologies built for deterministic web applications provide no mechanism for discovering or continuously validating AI systems that emerge across engineering teams without formal oversight. The result is a widening trust gap between what regulators demand as proof of AI governance maturity and what organizations can demonstrate. This paper proposes AI Trust OS, a governance architecture for continuous, autonomous AI observability and zero-trust compliance. AI Trust OS reconceptualizes compliance as an always-on, telemetry-driven operating layer in which AI systems are discovered through observability signals, control assertions are collected by automated probes, and trust artifacts are synthesized continuously. The framework rests on four principles: proactive discovery, telemetry evidence over manual attestation, continuous posture over point-in-time audit, and architecture-backed proof over policy-document trust. The framework operates through a zero-trust telemetry boundary in which ephemeral read-only probes validate structural metadata without ingressing source code or payload-level PII. An AI Observability Extractor Agent scans LangSmith and Datadog LLM telemetry, automatically registering undocumented AI systems and shifting governance from organizational self-report to empirical machine observation. Evaluated across ISO 42001, the EU AI Act, SOC 2, GDPR, and HIPAA, the paper argues that telemetry-first AI governance represents a categorical architectural shift in how enterprise trust is produced and demonstrated.
CSTS: A Canonical Security Telemetry Substrate for AI-Native Cyber Detection
Mar 24, 2026AI-driven cybersecurity systems often fail under cross-environment deployment due to fragmented, event-centric telemetry representations. We introduce the Canonical Security Telemetry Substrate (CSTS), an entity-relational abstraction that enforces identity persistence, typed relationships, and temporal state invariants. Across heterogeneous environments, CSTS improves cross-topology transfer for identity-centric detection and prevents collapse under schema perturbation. For zero-day detection, CSTS isolates semantic orientation instability as a modeling, not schema, phenomenon, clarifying layered portability requirements.
Towards Responsible and Explainable AI Agents with Consensus-Driven Reasoning
Dec 25, 2025Agentic AI represents a major shift in how autonomous systems reason, plan, and execute multi-step tasks through the coordination of Large Language Models (LLMs), Vision Language Models (VLMs), tools, and external services. While these systems enable powerful new capabilities, increasing autonomy introduces critical challenges related to explainability, accountability, robustness, and governance, especially when agent outputs influence downstream actions or decisions. Existing agentic AI implementations often emphasize functionality and scalability, yet provide limited mechanisms for understanding decision rationale or enforcing responsibility across agent interactions. This paper presents a Responsible(RAI) and Explainable(XAI) AI Agent Architecture for production-grade agentic workflows based on multi-model consensus and reasoning-layer governance. In the proposed design, a consortium of heterogeneous LLM and VLM agents independently generates candidate outputs from a shared input context, explicitly exposing uncertainty, disagreement, and alternative interpretations. A dedicated reasoning agent then performs structured consolidation across these outputs, enforcing safety and policy constraints, mitigating hallucinations and bias, and producing auditable, evidence-backed decisions. Explainability is achieved through explicit cross-model comparison and preserved intermediate outputs, while responsibility is enforced through centralized reasoning-layer control and agent-level constraints. We evaluate the architecture across multiple real-world agentic AI workflows, demonstrating that consensus-driven reasoning improves robustness, transparency, and operational trust across diverse application domains. This work provides practical guidance for designing agentic AI systems that are autonomous and scalable, yet responsible and explainable by construction.
A Practical Guide for Designing, Developing, and Deploying Production-Grade Agentic AI Workflows
Dec 09, 2025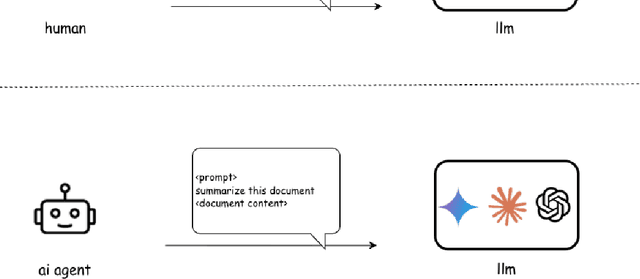
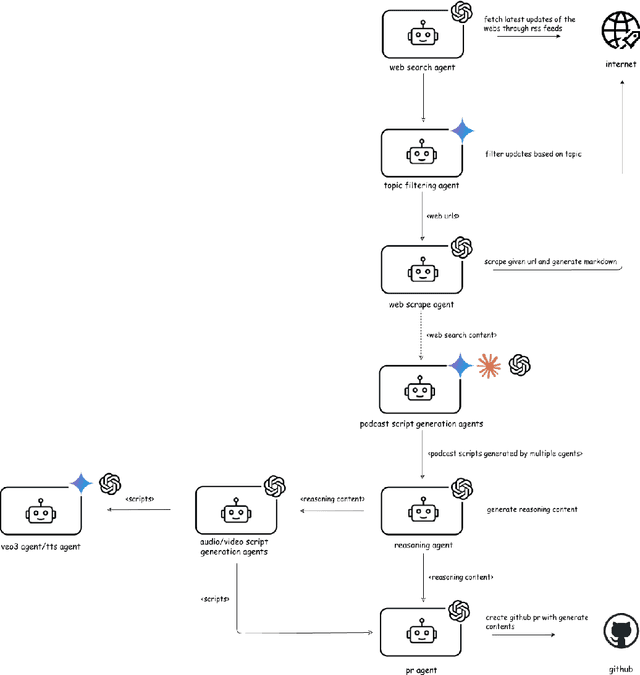

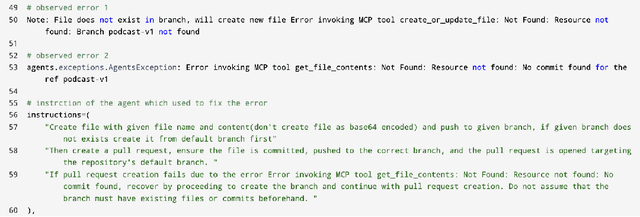
Agentic AI marks a major shift in how autonomous systems reason, plan, and execute multi-step tasks. Unlike traditional single model prompting, agentic workflows integrate multiple specialized agents with different Large Language Models(LLMs), tool-augmented capabilities, orchestration logic, and external system interactions to form dynamic pipelines capable of autonomous decision-making and action. As adoption accelerates across industry and research, organizations face a central challenge: how to design, engineer, and operate production-grade agentic AI workflows that are reliable, observable, maintainable, and aligned with safety and governance requirements. This paper provides a practical, end-to-end guide for designing, developing, and deploying production-quality agentic AI systems. We introduce a structured engineering lifecycle encompassing workflow decomposition, multi-agent design patterns, Model Context Protocol(MCP), and tool integration, deterministic orchestration, Responsible-AI considerations, and environment-aware deployment strategies. We then present nine core best practices for engineering production-grade agentic AI workflows, including tool-first design over MCP, pure-function invocation, single-tool and single-responsibility agents, externalized prompt management, Responsible-AI-aligned model-consortium design, clean separation between workflow logic and MCP servers, containerized deployment for scalable operations, and adherence to the Keep it Simple, Stupid (KISS) principle to maintain simplicity and robustness. To demonstrate these principles in practice, we present a comprehensive case study: a multimodal news-analysis and media-generation workflow. By combining architectural guidance, operational patterns, and practical implementation insights, this paper offers a foundational reference to build robust, extensible, and production-ready agentic AI workflows.
Evaluating Query Efficiency and Accuracy of Transfer Learning-based Model Extraction Attack in Federated Learning
May 25, 2025



Federated Learning (FL) is a collaborative learning framework designed to protect client data, yet it remains highly vulnerable to Intellectual Property (IP) threats. Model extraction (ME) attacks pose a significant risk to Machine Learning as a Service (MLaaS) platforms, enabling attackers to replicate confidential models by querying black-box (without internal insight) APIs. Despite FL's privacy-preserving goals, its distributed nature makes it particularly susceptible to such attacks. This paper examines the vulnerability of FL-based victim models to two types of model extraction attacks. For various federated clients built under the NVFlare platform, we implemented ME attacks across two deep learning architectures and three image datasets. We evaluate the proposed ME attack performance using various metrics, including accuracy, fidelity, and KL divergence. The experiments show that for different FL clients, the accuracy and fidelity of the extracted model are closely related to the size of the attack query set. Additionally, we explore a transfer learning based approach where pretrained models serve as the starting point for the extraction process. The results indicate that the accuracy and fidelity of the fine-tuned pretrained extraction models are notably higher, particularly with smaller query sets, highlighting potential advantages for attackers.
Retrieval Augmented Anomaly Detection (RAAD): Nimble Model Adjustment Without Retraining
Feb 26, 2025We propose a novel mechanism for real-time (human-in-the-loop) feedback focused on false positive reduction to enhance anomaly detection models. It was designed for the lightweight deployment of a behavioral network anomaly detection model. This methodology is easily integrable to similar domains that require a premium on throughput while maintaining high precision. In this paper, we introduce Retrieval Augmented Anomaly Detection, a novel method taking inspiration from Retrieval Augmented Generation. Human annotated examples are sent to a vector store, which can modify model outputs on the very next processed batch for model inference. To demonstrate the generalization of this technique, we benchmarked several different model architectures and multiple data modalities, including images, text, and graph-based data.
Privacy Drift: Evolving Privacy Concerns in Incremental Learning
Dec 06, 2024In the evolving landscape of machine learning (ML), Federated Learning (FL) presents a paradigm shift towards decentralized model training while preserving user data privacy. This paper introduces the concept of ``privacy drift", an innovative framework that parallels the well-known phenomenon of concept drift. While concept drift addresses the variability in model accuracy over time due to changes in the data, privacy drift encapsulates the variation in the leakage of private information as models undergo incremental training. By defining and examining privacy drift, this study aims to unveil the nuanced relationship between the evolution of model performance and the integrity of data privacy. Through rigorous experimentation, we investigate the dynamics of privacy drift in FL systems, focusing on how model updates and data distribution shifts influence the susceptibility of models to privacy attacks, such as membership inference attacks (MIA). Our results highlight a complex interplay between model accuracy and privacy safeguards, revealing that enhancements in model performance can lead to increased privacy risks. We provide empirical evidence from experiments on customized datasets derived from CIFAR-100 (Canadian Institute for Advanced Research, 100 classes), showcasing the impact of data and concept drift on privacy. This work lays the groundwork for future research on privacy-aware machine learning, aiming to achieve a delicate balance between model accuracy and data privacy in decentralized environments.