 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt's the humans, not the data: Geopolitical bias in LLMs originates in post-training, amplified by the language of the prompt
May 22, 2026It has generally been assumed that geopolitical bias in language models originates from the training data used during the pre-training phase. We tested seven open-weight LLM pairs consisting of the base model (pre-training only) and the chat model (pre-training and post-training) from seven labs on a paired-scenario forced-choice probe over 28 country pairs in English, French, and Chinese, and found that geopolitical bias originates in post-training rather than in pre-training. Across seven AI labs, six showed shifts in the direction associated with the country or region of the model developer after post-training. This shift is strongest in Alibaba's Qwen 2.5: while the base is neutral on China-favourability (-0.15 log-odds, p=0.15), the post-trained chat variant is at +2.91 (p<10^-4), an 18x shift in odds. We also observe shifts in biases toward other countries across all models. Additionally, the magnitude of this shift depends on the language used to prompt the model: the French-made Mistral becomes pro-France only under French prompting (FR-EN shift +1.91, p<10^-4). These findings suggest that geopolitical preferences in language models are not simply inherited from large-scale internet data but are actively shaped during post-training, highlighting the need for greater transparency, auditing, and oversight of alignment processes that influence how models represent nations, cultures, and political perspectives.
Feature Visualization Recovers Known Cortical Selectivity from TRIBE v2
May 13, 2026Brain encoder models predict cortical fMRI responses from the internal activations of pretrained vision and language networks, and are typically evaluated by held-out prediction accuracy. This is a useful signal for training but a poor one for interpretation: it tells us an encoder fits the data without telling us whether it has internalized the functional organization of the brain. We propose feature visualization -- gradient ascent on the encoder's predicted activation for a target region of interest (ROI) -- as a complementary interpretability technique, and apply it to TRIBE v2 composed with V-JEPA 2 (ViT-G, 40 layers), holding both frozen and synthesizing still images for seven regions spanning the ventral and dorsal visual hierarchies. Under identical hyperparameters, the probe recovers a visible progression of increasing spatial scale and feature complexity across V1 to V4, matching the ventral-stream hierarchy. It also produces three distinctive downstream regimes: radial "frozen-motion" streaks for the middle temporal area (MT) despite static-only optimization, face-like features for the fusiform face area (FFA), and consistent rectilinear line patterns for the parahippocampal place area (PPA). Optimized FFA stimuli drive the predicted region ~4x as much as a natural face photograph, consistent with feature visualization producing adversarial super-stimuli rather than canonical exemplars. The probe is simple, differentiable, and applicable to any brain encoder with a differentiable backbone, allowing for qualitative evaluation of brain encoders.
When2Speak: A Dataset for Temporal Participation and Turn-Taking in Multi-Party Conversations for Large Language Models
May 07, 2026Large Language Models (LLMs) excel at generating contextually appropriate responses but remain poorly calibrated for multi-party conversations, where deciding when to speak is as critical as what to say. In such settings, naively responding at every turn leads to excessive interruptions and degraded conversational coherence. We introduce When2Speak, a grounded synthetic dataset and four-stage generation pipeline for learning intervention timing in group interactions. The dataset comprises over 215,000 examples derived from 16,000 conversations involving 2-6 speakers, spanning diverse conversational styles, tones, and participant dynamics, and explicitly modeling SPEAK vs. SILENT decisions at each turn. Our pipeline combines real-world grounding, structured augmentation, controlled transcript synthesis, and fine-tuning-ready supervision, and is fully open-sourced to support reproducibility and adaptation to domain-specific conversational norms. Across multiple model families, supervised fine-tuning (SFT) on When2Speak significantly outperforms zero-shot baselines (e.g., the average Macro F1 increase across 4B+ parameter models was 60%, with the largest increase being 120%). However, SFT-trained models remain systematically over-conservative, missing nearly half of warranted interventions as seen through the Missed Intervention Rate (MIR), which was on average 0.50 and is noticed even at larger model sizes. To address this limitation, we apply reinforcement learning with asymmetric reward shaping, which reduces MIR to 0.186-0.218 and increases recall from 0.479 to 0.78-0.81. Our findings establish that temporal participation is a distinct and trainable dimension of conversational intelligence, and that grounded synthetic data provides an effective and scalable pathway for enabling LLMs to participate more naturally and appropriately in multi-party interactions.
GLEaN: A Text-to-image Bias Detection Approach for Public Comprehension
Apr 10, 2026Text-to-image (T2I) models, and their encoded biases, increasingly shape the visual media the public encounters. While researchers have produced a rich body of work on bias measurement, auditing, and mitigation in T2I systems, those methods largely target technical stakeholders, leaving a gap in public legibility. We introduce GLEaN (Generative Likeness Evaluation at N-Scale), a portrait-based explainability pipeline designed to make T2I model biases visually understandable to a broad audience. GLEaN comprises three stages: automated large-scale image generation from identity prompts, facial landmark-based filtering and spatial alignment, and median-pixel composition that distills a model's central tendency into a single representative portrait. The resulting composites require no statistical background to interpret; a viewer can see, at a glance, who a model 'imagines' when prompted with 'a doctor' versus a 'felon.' We demonstrate GLEaN on Stable Diffusion XL across 40 social and occupational identity prompts, producing composites that reproduce documented biases and surface new associations between skin tone and predicted emotion. We find in a between-subjects user study (N = 291) that GLEaN portraits communicate biases as effectively as conventional data tables, but require significantly less viewing time. Because the method relies solely on generated outputs, it can also be replicated on any black-box and closed-weight systems without access to model internals. GLEaN offers a scalable, model-agnostic approach to bias explainability, purpose-built for public comprehension, and is publicly available at https://github.com/cultureiolab/GLEaN.
On Thin Ice: Towards Explainable Conservation Monitoring via Attribution and Perturbations
Oct 24, 2025Computer vision can accelerate ecological research and conservation monitoring, yet adoption in ecology lags in part because of a lack of trust in black-box neural-network-based models. We seek to address this challenge by applying post-hoc explanations to provide evidence for predictions and document limitations that are important to field deployment. Using aerial imagery from Glacier Bay National Park, we train a Faster R-CNN to detect pinnipeds (harbor seals) and generate explanations via gradient-based class activation mapping (HiResCAM, LayerCAM), local interpretable model-agnostic explanations (LIME), and perturbation-based explanations. We assess explanations along three axes relevant to field use: (i) localization fidelity: whether high-attribution regions coincide with the animal rather than background context; (ii) faithfulness: whether deletion/insertion tests produce changes in detector confidence; and (iii) diagnostic utility: whether explanations reveal systematic failure modes. Explanations concentrate on seal torsos and contours rather than surrounding ice/rock, and removal of the seals reduces detection confidence, providing model-evidence for true positives. The analysis also uncovers recurrent error sources, including confusion between seals and black ice and rocks. We translate these findings into actionable next steps for model development, including more targeted data curation and augmentation. By pairing object detection with post-hoc explainability, we can move beyond "black-box" predictions toward auditable, decision-supporting tools for conservation monitoring.
The Term 'Agent' Has Been Diluted Beyond Utility and Requires Redefinition
Aug 07, 2025

The term 'agent' in artificial intelligence has long carried multiple interpretations across different subfields. Recent developments in AI capabilities, particularly in large language model systems, have amplified this ambiguity, creating significant challenges in research communication, system evaluation and reproducibility, and policy development. This paper argues that the term 'agent' requires redefinition. Drawing from historical analysis and contemporary usage patterns, we propose a framework that defines clear minimum requirements for a system to be considered an agent while characterizing systems along a multidimensional spectrum of environmental interaction, learning and adaptation, autonomy, goal complexity, and temporal coherence. This approach provides precise vocabulary for system description while preserving the term's historically multifaceted nature. After examining potential counterarguments and implementation challenges, we provide specific recommendations for moving forward as a field, including suggestions for terminology standardization and framework adoption. The proposed approach offers practical tools for improving research clarity and reproducibility while supporting more effective policy development.
Semantic Approach to Quantifying the Consistency of Diffusion Model Image Generation
Apr 12, 2024

In this study, we identify the need for an interpretable, quantitative score of the repeatability, or consistency, of image generation in diffusion models. We propose a semantic approach, using a pairwise mean CLIP (Contrastive Language-Image Pretraining) score as our semantic consistency score. We applied this metric to compare two state-of-the-art open-source image generation diffusion models, Stable Diffusion XL and PixArt-{\alpha}, and we found statistically significant differences between the semantic consistency scores for the models. Agreement between the Semantic Consistency Score selected model and aggregated human annotations was 94%. We also explored the consistency of SDXL and a LoRA-fine-tuned version of SDXL and found that the fine-tuned model had significantly higher semantic consistency in generated images. The Semantic Consistency Score proposed here offers a measure of image generation alignment, facilitating the evaluation of model architectures for specific tasks and aiding in informed decision-making regarding model selection.
Releasing the CRaQAn : An open-source dataset and dataset creation methodology using instruction-following models
Nov 27, 2023



Instruction-following language models demand robust methodologies for information retrieval to augment instructions for question-answering applications. A primary challenge is the resolution of coreferences in the context of chunking strategies for long documents. The critical barrier to experimentation of handling coreferences is a lack of open source datasets, specifically in question-answering tasks that require coreference resolution. In this work we present our Coreference Resolution in Question-Answering (CRaQAn) dataset, an open-source dataset that caters to the nuanced information retrieval requirements of coreference resolution in question-answering tasks by providing over 250 question-answer pairs containing coreferences. To develop this dataset, we developed a novel approach for creating high-quality datasets using an instruction-following model (GPT-4) and a Recursive Criticism and Improvement Loop.
InfiniteForm: A synthetic, minimal bias dataset for fitness applications
Oct 04, 2021
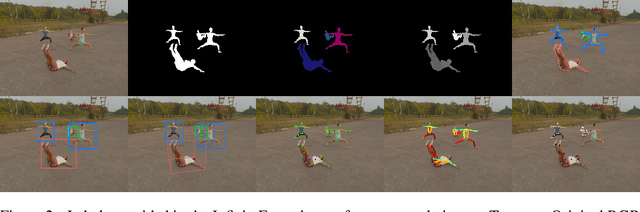
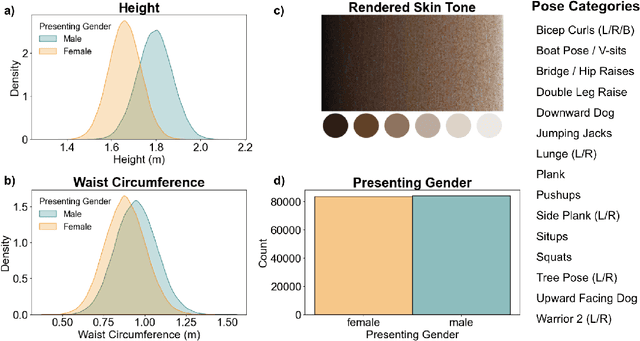
The growing popularity of remote fitness has increased the demand for highly accurate computer vision models that track human poses. However, the best methods still fail in many real-world fitness scenarios, suggesting that there is a domain gap between current datasets and real-world fitness data. To enable the field to address fitness-specific vision problems, we created InfiniteForm, an open-source synthetic dataset of 60k images with diverse fitness poses (15 categories), both single- and multi-person scenes, and realistic variation in lighting, camera angles, and occlusions. As a synthetic dataset, InfiniteForm offers minimal bias in body shape and skin tone, and provides pixel-perfect labels for standard annotations like 2D keypoints, as well as those that are difficult or impossible for humans to produce like depth and occlusion. In addition, we introduce a novel generative procedure for creating diverse synthetic poses from predefined exercise categories. This generative process can be extended to any application where pose diversity is needed to train robust computer vision models.
Low-Rank Nonlinear Decoding of $μ$-ECoG from the Primary Auditory Cortex
May 06, 2020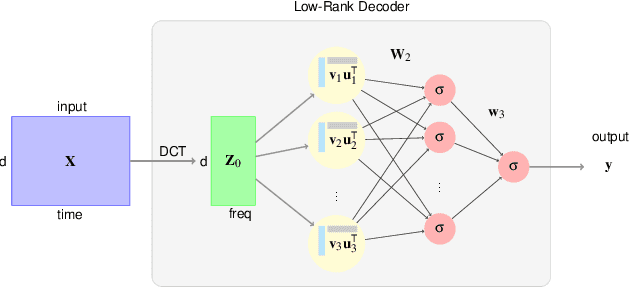
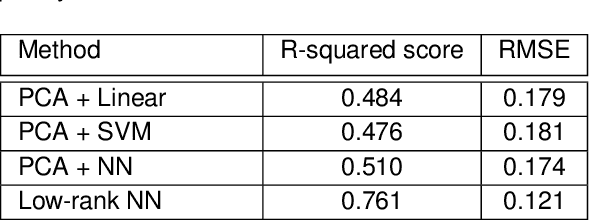
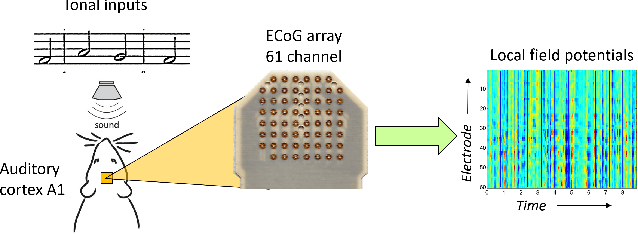
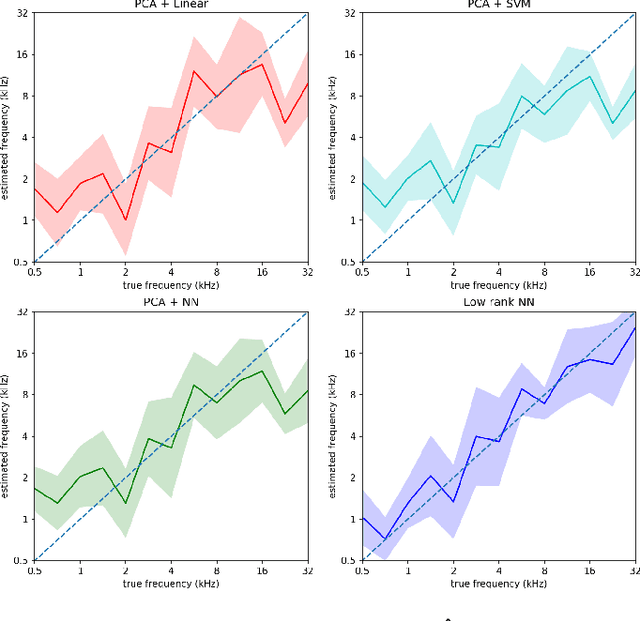
This paper considers the problem of neural decoding from parallel neural measurements systems such as micro-electrocorticography ($\mu$-ECoG). In systems with large numbers of array elements at very high sampling rates, the dimension of the raw measurement data may be large. Learning neural decoders for this high-dimensional data can be challenging, particularly when the number of training samples is limited. To address this challenge, this work presents a novel neural network decoder with a low-rank structure in the first hidden layer. The low-rank constraints dramatically reduce the number of parameters in the decoder while still enabling a rich class of nonlinear decoder maps. The low-rank decoder is illustrated on $\mu$-ECoG data from the primary auditory cortex (A1) of awake rats. This decoding problem is particularly challenging due to the complexity of neural responses in the auditory cortex and the presence of confounding signals in awake animals. It is shown that the proposed low-rank decoder significantly outperforms models using standard dimensionality reduction techniques such as principal component analysis (PCA).