 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A unified Neural Network Approach to E-CommerceRelevance Learning
Apr 26, 2021
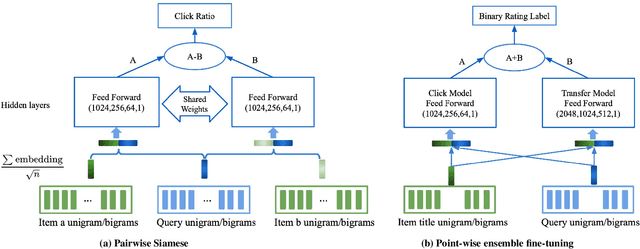



Result relevance scoring is critical to e-commerce search user experience. Traditional information retrieval methods focus on keyword matching and hand-crafted or counting-based numeric features, with limited understanding of item semantic relevance. We describe a highly-scalable feed-forward neural model to provide relevance score for (query, item) pairs, using only user query and item title as features, and both user click feedback as well as limited human ratings as labels. Several general enhancements were applied to further optimize eval/test metrics, including Siamese pairwise architecture, random batch negative co-training, and point-wise fine-tuning. We found significant improvement over GBDT baseline as well as several off-the-shelf deep-learning baselines on an independently constructed ratings dataset. The GBDT model relies on 10 times more features. We also present metrics for select subset combinations of techniques mentioned above.
* 6 pages
Exploring Visual Engagement Signals for Representation Learning
Apr 15, 2021
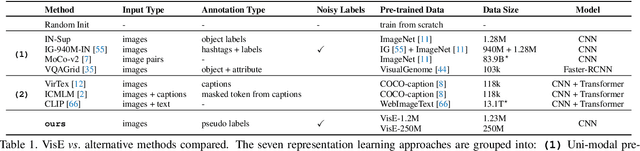
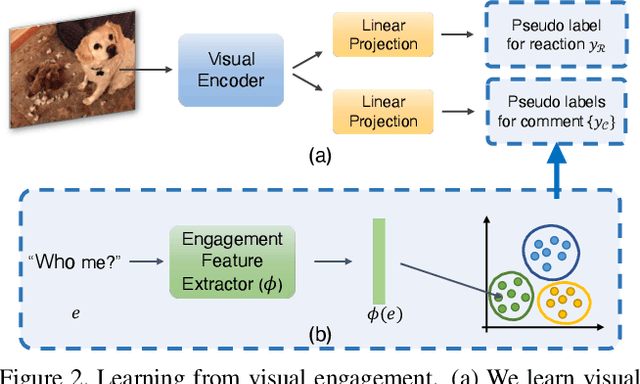
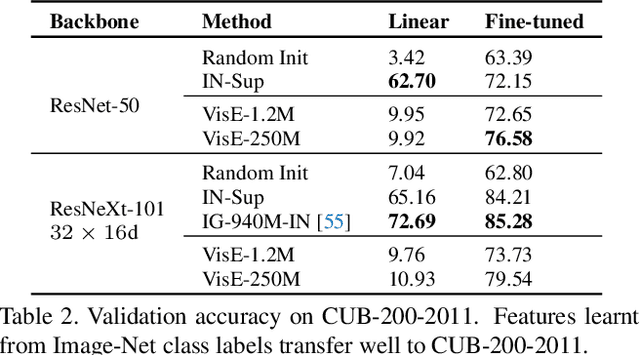
Visual engagement in social media platforms comprises interactions with photo posts including comments, shares, and likes. In this paper, we leverage such visual engagement clues as supervisory signals for representation learning. However, learning from engagement signals is non-trivial as it is not clear how to bridge the gap between low-level visual information and high-level social interactions. We present VisE, a weakly supervised learning approach, which maps social images to pseudo labels derived by clustered engagement signals. We then study how models trained in this way benefit subjective downstream computer vision tasks such as emotion recognition or political bias detection. Through extensive studies, we empirically demonstrate the effectiveness of VisE across a diverse set of classification tasks beyond the scope of conventional recognition.
Tech Report: A Homogeneity-Based Multiscale Hyperspectral Image Representation for Sparse Spectral Unmixing
Feb 11, 2021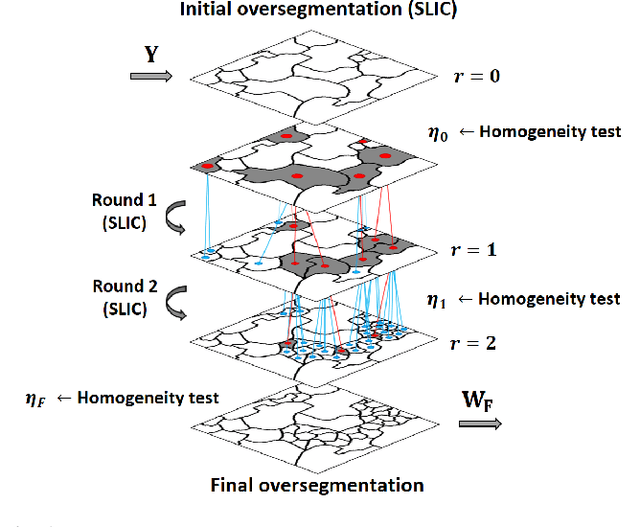
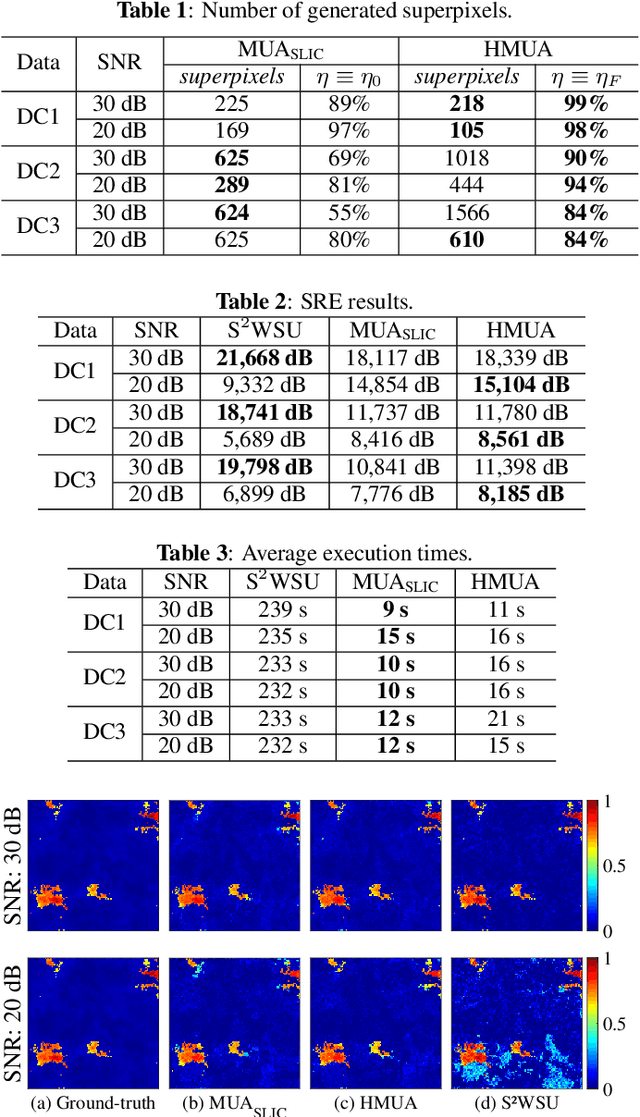

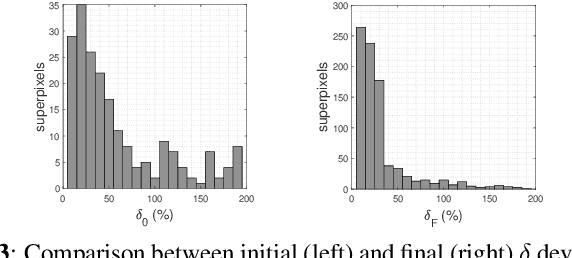
Several approaches have been proposed to solve the spectral unmixing problem in hyperspectral image analysis. Among them the use of sparse regression techniques aims to characterize the abundances in pixels based on a large library of spectral signatures known a priori. Recently, the integration of image spatial-contextual information significantly enhanced the performance of sparse unmixing. In this work, we propose a computationally efficient multiscale representation method for hyperspectral data adapted to the unmixing problem. The proposed method is based on a hierarchical extension of the SLIC oversegmentation algorithm constructed using a robust homogeneity testing. The image is subdivided into a set of spectrally homogeneous regions formed by pixels with similar characteristics (superpixels). This representation is then used to provide prior spatial regularity information for the abundances of materials present in the scene, improving the conditioning of the unmixing problem. Simulation results illustrate that the method is capable of estimating abundances with high quality and low computational cost, especially in noisy scenarios.
Forensic Analysis of Video Files Using Metadata
May 13, 2021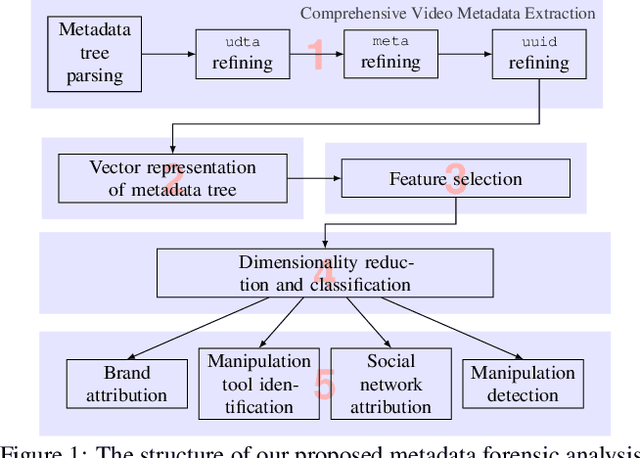

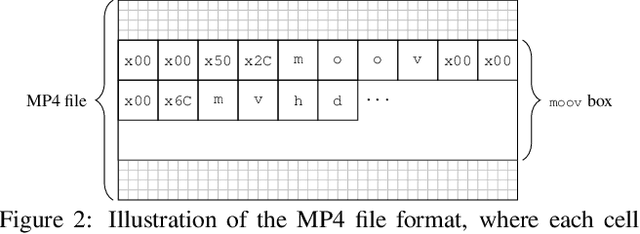
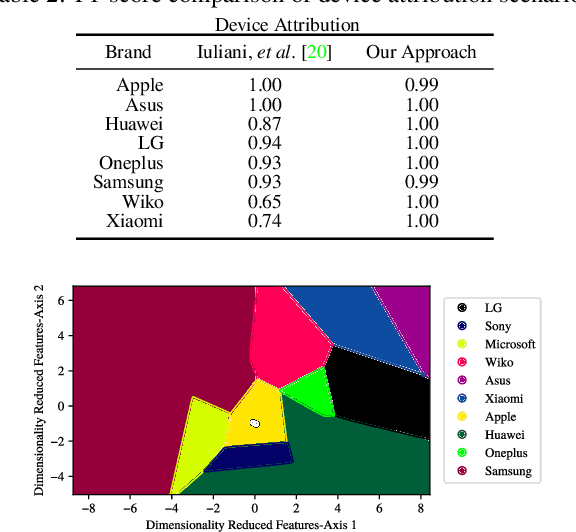
The unprecedented ease and ability to manipulate video content has led to a rapid spread of manipulated media. The availability of video editing tools greatly increased in recent years, allowing one to easily generate photo-realistic alterations. Such manipulations can leave traces in the metadata embedded in video files. This metadata information can be used to determine video manipulations, brand of video recording device, the type of video editing tool, and other important evidence. In this paper, we focus on the metadata contained in the popular MP4 video wrapper/container. We describe our method for metadata extractor that uses the MP4's tree structure. Our approach for analyzing the video metadata produces a more compact representation. We will describe how we construct features from the metadata and then use dimensionality reduction and nearest neighbor classification for forensic analysis of a video file. Our approach allows one to visually inspect the distribution of metadata features and make decisions. The experimental results confirm that the performance of our approach surpasses other methods.
Match-Ignition: Plugging PageRank into Transformer for Long-form Text Matching
Jan 16, 2021
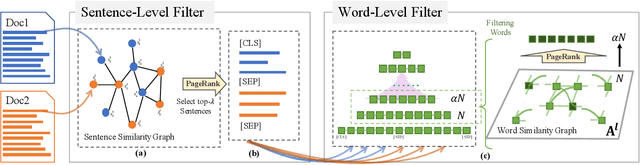
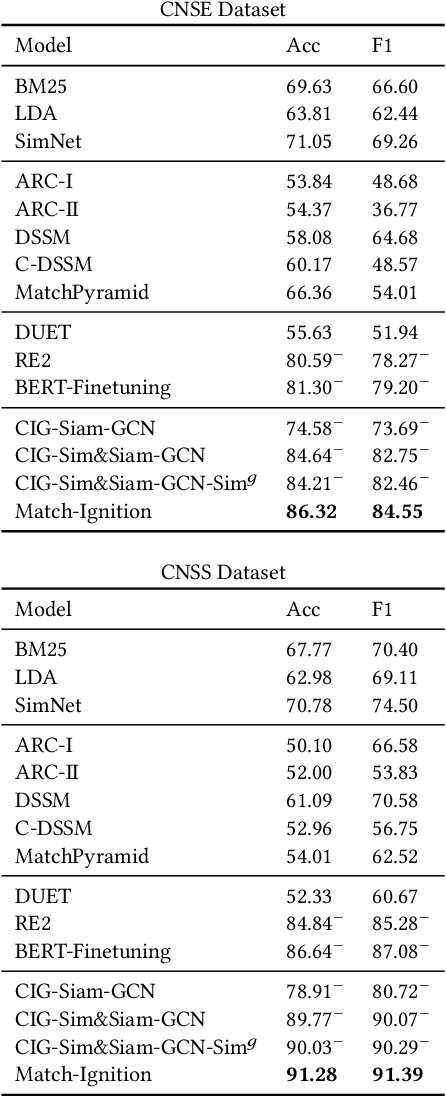
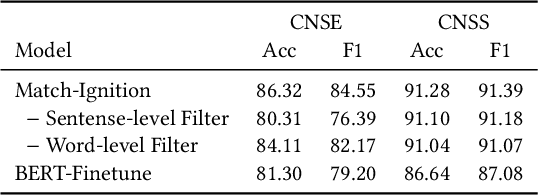
Semantic text matching models have been widely used in community question answering, information retrieval, and dialogue. However, these models cannot well address the long-form text matching problem. That is because there are usually many noises in the setting of long-form text matching, and it is difficult for existing semantic text matching to capture the key matching signals from this noisy information. Besides, these models are computationally expensive because they simply use all textual data indiscriminately in the matching process. To tackle the effectiveness and efficiency problem, we propose a novel hierarchical noise filtering model in this paper, namely Match-Ignition. The basic idea is to plug the well-known PageRank algorithm into the Transformer, to identify and filter both sentence and word level noisy information in the matching process. Noisy sentences are usually easy to detect because the sentence is the basic unit of a long-form text, so we directly use PageRank to filter such information, based on a sentence similarity graph. While words need to rely on their contexts to express concrete meanings, so we propose to jointly learn the filtering process and the matching process, to reflect the contextual dependencies between words. Specifically, a word graph is first built based on the attention scores in each self-attention block of Transformer, and keywords are then selected by applying PageRank on this graph. In this way, noisy words will be filtered out layer by layer in the matching process. Experimental results show that Match-Ignition outperforms both traditional text matching models for short text and recent long-form text matching models. We also conduct detailed analysis to show that Match-Ignition can efficiently capture important sentences or words, which are helpful for long-form text matching.
Online Lifelong Generalized Zero-Shot Learning
Mar 22, 2021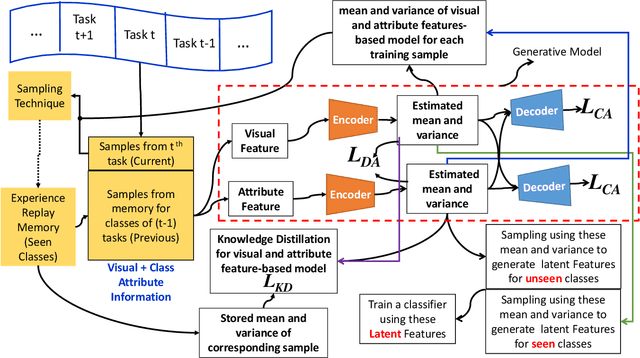
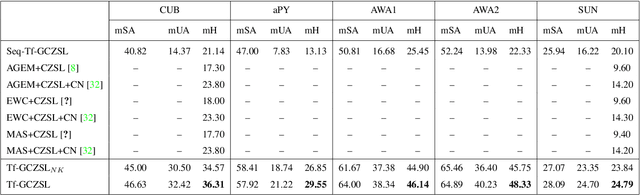
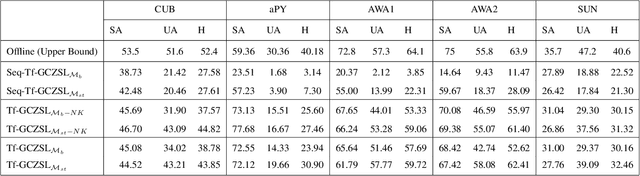
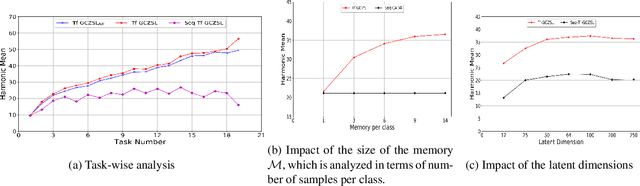
Methods proposed in the literature for zero-shot learning (ZSL) are typically suitable for offline learning and cannot continually learn from sequential streaming data. The sequential data comes in the form of tasks during training. Recently, a few attempts have been made to handle this issue and develop continual ZSL (CZSL) methods. However, these CZSL methods require clear task-boundary information between the tasks during training, which is not practically possible. This paper proposes a task-free (i.e., task-agnostic) CZSL method, which does not require any task information during continual learning. The proposed task-free CZSL method employs a variational autoencoder (VAE) for performing ZSL. To develop the CZSL method, we combine the concept of experience replay with knowledge distillation and regularization. Here, knowledge distillation is performed using the training sample's dark knowledge, which essentially helps overcome the catastrophic forgetting issue. Further, it is enabled for task-free learning using short-term memory. Finally, a classifier is trained on the synthetic features generated at the latent space of the VAE. Moreover, the experiments are conducted in a challenging and practical ZSL setup, i.e., generalized ZSL (GZSL). These experiments are conducted for two kinds of single-head continual learning settings: (i) mild setting-: task-boundary is known only during training but not during testing; (ii) strict setting-: task-boundary is not known at training, as well as testing. Experimental results on five benchmark datasets exhibit the validity of the approach for CZSL.
Privacy-Preserving Dynamic Personalized Pricing with Demand Learning
Sep 27, 2020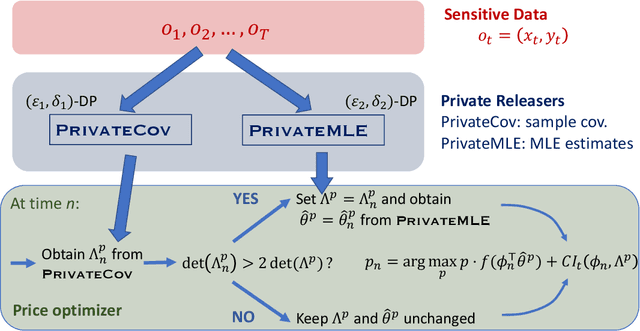
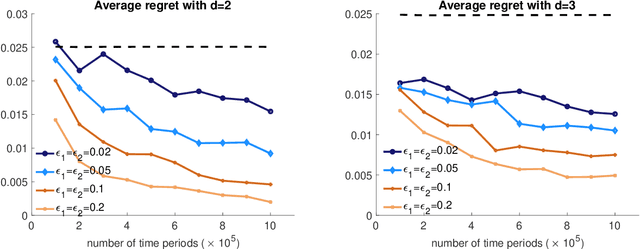
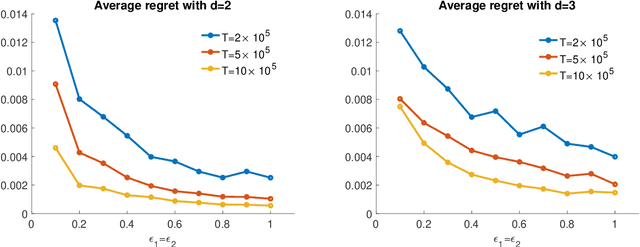
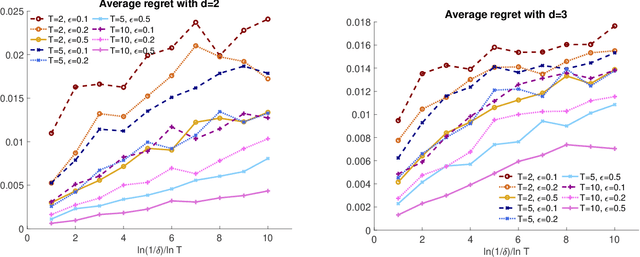
The prevalence of e-commerce has made detailed customers' personal information readily accessible to retailers, and this information has been widely used in pricing decisions. When involving personalized information, how to protect the privacy of such information becomes a critical issue in practice. In this paper, we consider a dynamic pricing problem over $T$ time periods with an \emph{unknown} demand function of posted price and personalized information. At each time $t$, the retailer observes an arriving customer's personal information and offers a price. The customer then makes the purchase decision, which will be utilized by the retailer to learn the underlying demand function. There is potentially a serious privacy concern during this process: a third party agent might infer the personalized information and purchase decisions from price changes from the pricing system. Using the fundamental framework of differential privacy from computer science, we develop a privacy-preserving dynamic pricing policy, which tries to maximize the retailer revenue while avoiding information leakage of individual customer's information and purchasing decisions. To this end, we first introduce a notion of \emph{anticipating} $(\varepsilon, \delta)$-differential privacy that is tailored to dynamic pricing problem. Our policy achieves both the privacy guarantee and the performance guarantee in terms of regret. Roughly speaking, for $d$-dimensional personalized information, our algorithm achieves the expected regret at the order of $\tilde{O}(\varepsilon^{-1} \sqrt{d^3 T})$, when the customers' information is adversarially chosen. For stochastic personalized information, the regret bound can be further improved to $\tilde{O}(\sqrt{d^2T} + \varepsilon^{-2} d^2)$
Modeling Method for the Coupling Relations of Microgrid Cyber-Physical Systems Driven by Hybrid Spatiotemporal Events
Feb 01, 2021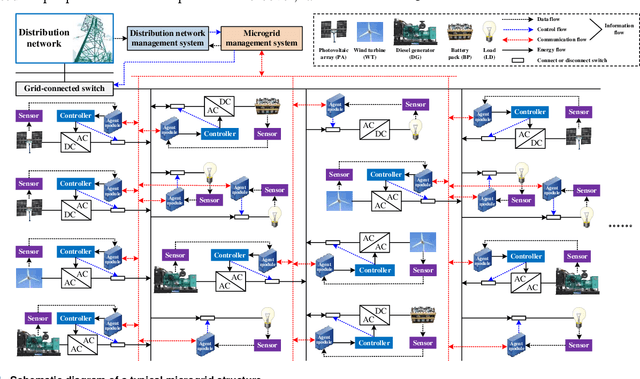
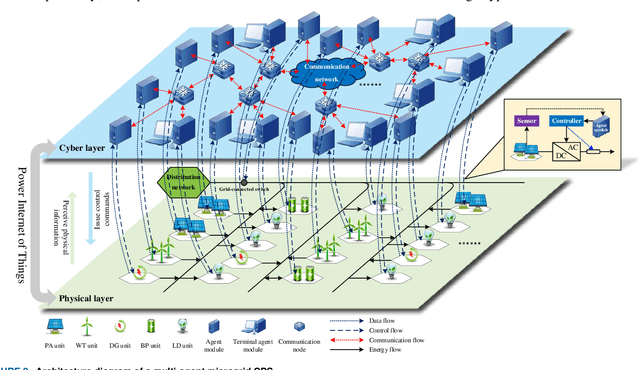

The essence of the microgrid cyber-physical system (CPS) lies in the cyclical conversion of information flow and energy flow. Most of the existing coupling models are modeled with static networks and interface structures, in which the closed-loop data flow characteristic is not fully considered. It is difficult for these models to accurately describe spatiotemporal deduction processes, such as microgrid CPS attack identification, risk propagation, safety assessment, defense control, and cascading failure. To address this problem, a modeling method for the coupling relations of microgrid CPS driven by hybrid spatiotemporal events is proposed in the present work. First, according to the topological correlation and coupling logic of the microgrid CPS, the cyclical conversion mechanism of information flow and energy flow is analyzed, and a microgrid CPS architecture with multi-agents as the core is constructed. Next, the spatiotemporal evolution characteristic of the CPS is described by hybrid automata, and the task coordination mechanism of the multi-agent CPS terminal is designed. On this basis, a discrete-continuous correlation and terminal structure characteristic representation method of the CPS based on heterogeneous multi-groups are then proposed. Finally, four spatiotemporal events, namely state perception, network communication, intelligent decision-making, and action control, are defined. Considering the constraints of the temporal conversion of information flow and energy flow, a microgrid CPS coupling model is established, the effectiveness of which is verified by simulating false data injection attack (FDIA) scenarios.
Outage Constrained Robust Secure Beamforming in Cognitive Satellite-Aerial Networks
May 13, 2021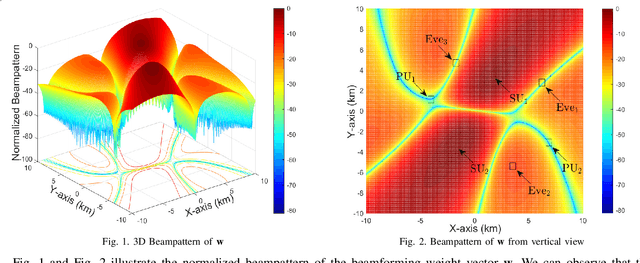
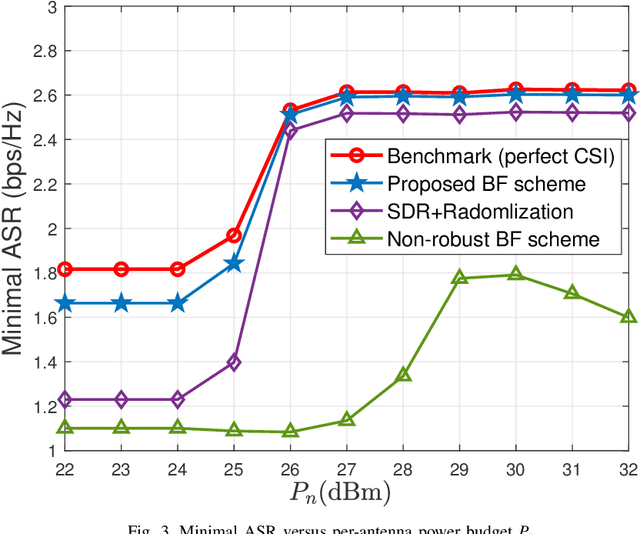
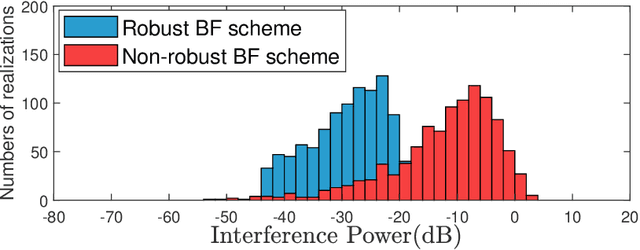
This paper proposes a robust beamforming scheme to enhance the physical layer security (PLS) of multicast transmission in a cognitive satellite and aerial network (CSAN) operating in the millimeter wave frequency band. Based on imperfect channel state information (CSI) of both eavesdroppers (Eves) and primary users (PUs), we maximize the minimum achievable secrecy rate (ASR) of the secondary users (SUs) in the aerial network under the constraints of the interference to the PUs in the satellite network, the quality of service (QoS) requirements of the SUs and per-antenna power budget of the aerial platform. To tackle this mathematically intractable problem, we first introduce an auxiliary variable and outage constraints to simplify the complex objective function. We then convert the non-convex outage constraints into deterministic forms and adopt penalty function approach to obtain a semi-definite problem such that it can be solved in an iterative fashion. Finally, simulation results show that with the transmit power increase, the minimal ASR of SUs obtained from the proposed BF scheme well approximate the optimal value.
Encoder Fusion Network with Co-Attention Embedding for Referring Image Segmentation
May 05, 2021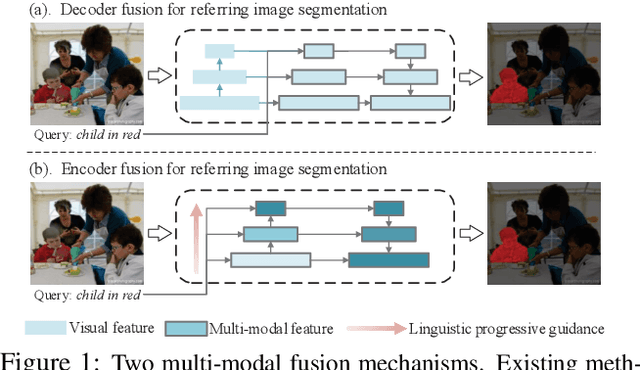
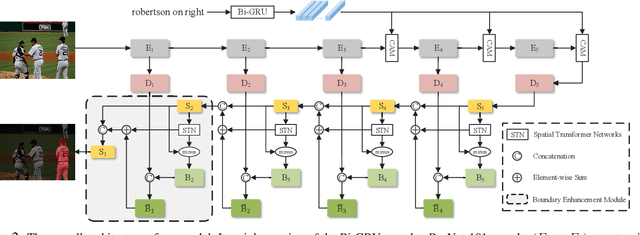
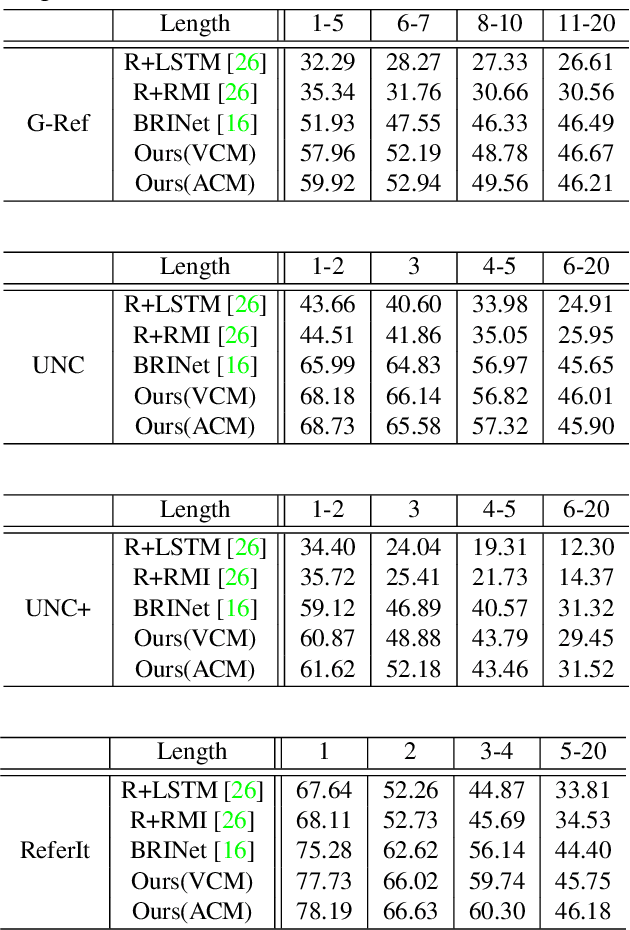
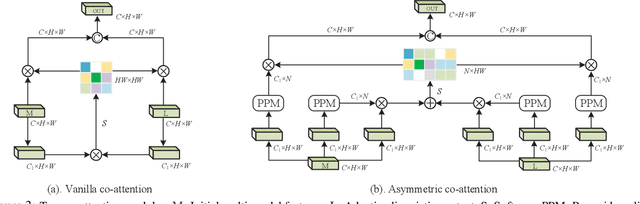
Recently, referring image segmentation has aroused widespread interest. Previous methods perform the multi-modal fusion between language and vision at the decoding side of the network. And, linguistic feature interacts with visual feature of each scale separately, which ignores the continuous guidance of language to multi-scale visual features. In this work, we propose an encoder fusion network (EFN), which transforms the visual encoder into a multi-modal feature learning network, and uses language to refine the multi-modal features progressively. Moreover, a co-attention mechanism is embedded in the EFN to realize the parallel update of multi-modal features, which can promote the consistent of the cross-modal information representation in the semantic space. Finally, we propose a boundary enhancement module (BEM) to make the network pay more attention to the fine structure. The experiment results on four benchmark datasets demonstrate that the proposed approach achieves the state-of-the-art performance under different evaluation metrics without any post-processing.