 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Water Leak Detection with Convolutional Neural Networks and One-Class Support Vector Machine
Nov 10, 2025



Water is a critical resource that must be managed efficiently. However, a substantial amount of water is lost each year due to leaks in Water Distribution Networks (WDNs). This underscores the need for reliable and effective leak detection and localization systems. In recent years, various solutions have been proposed, with data-driven approaches gaining increasing attention due to their superior performance. In this paper, we propose a new method for leak detection. The method is based on water pressure measurements acquired at a series of nodes of a WDN. Our technique is a fully data-driven solution that makes only use of the knowledge of the WDN topology, and a series of pressure data acquisitions obtained in absence of leaks. The proposed solution is based on an feature extractor and a one-class Support Vector Machines (SVM) trained on no-leak data, so that leaks are detected as anomalies. The results achieved on a simulate dataset using the Modena WDN demonstrate that the proposed solution outperforms recent methods for leak detection.
Mitigating data replication in text-to-audio generative diffusion models through anti-memorization guidance
Sep 18, 2025A persistent challenge in generative audio models is data replication, where the model unintentionally generates parts of its training data during inference. In this work, we address this issue in text-to-audio diffusion models by exploring the use of anti-memorization strategies. We adopt Anti-Memorization Guidance (AMG), a technique that modifies the sampling process of pre-trained diffusion models to discourage memorization. Our study explores three types of guidance within AMG, each designed to reduce replication while preserving generation quality. We use Stable Audio Open as our backbone, leveraging its fully open-source architecture and training dataset. Our comprehensive experimental analysis suggests that AMG significantly mitigates memorization in diffusion-based text-to-audio generation without compromising audio fidelity or semantic alignment.
Source Verification for Speech Deepfakes
May 20, 2025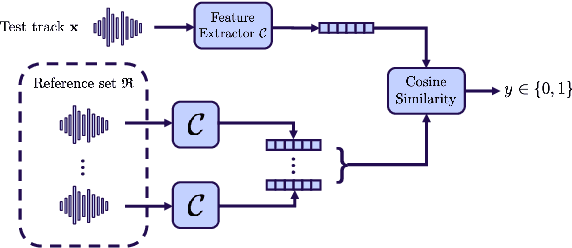
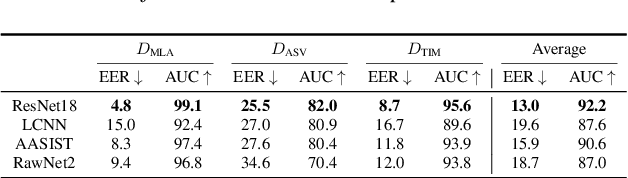
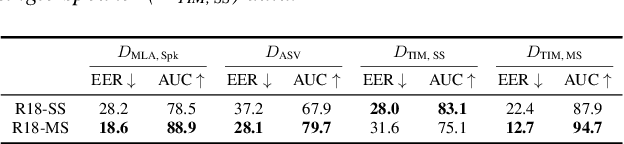
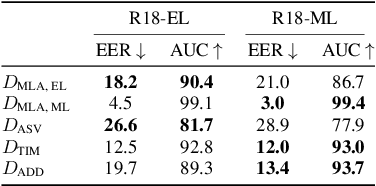
With the proliferation of speech deepfake generators, it becomes crucial not only to assess the authenticity of synthetic audio but also to trace its origin. While source attribution models attempt to address this challenge, they often struggle in open-set conditions against unseen generators. In this paper, we introduce the source verification task, which, inspired by speaker verification, determines whether a test track was produced using the same model as a set of reference signals. Our approach leverages embeddings from a classifier trained for source attribution, computing distance scores between tracks to assess whether they originate from the same source. We evaluate multiple models across diverse scenarios, analyzing the impact of speaker diversity, language mismatch, and post-processing operations. This work provides the first exploration of source verification, highlighting its potential and vulnerabilities, and offers insights for real-world forensic applications.
WILD: a new in-the-Wild Image Linkage Dataset for synthetic image attribution
Apr 29, 2025Synthetic image source attribution is an open challenge, with an increasing number of image generators being released yearly. The complexity and the sheer number of available generative techniques, as well as the scarcity of high-quality open source datasets of diverse nature for this task, make training and benchmarking synthetic image source attribution models very challenging. WILD is a new in-the-Wild Image Linkage Dataset designed to provide a powerful training and benchmarking tool for synthetic image attribution models. The dataset is built out of a closed set of 10 popular commercial generators, which constitutes the training base of attribution models, and an open set of 10 additional generators, simulating a real-world in-the-wild scenario. Each generator is represented by 1,000 images, for a total of 10,000 images in the closed set and 10,000 images in the open set. Half of the images are post-processed with a wide range of operators. WILD allows benchmarking attribution models in a wide range of tasks, including closed and open set identification and verification, and robust attribution with respect to post-processing and adversarial attacks. Models trained on WILD are expected to benefit from the challenging scenario represented by the dataset itself. Moreover, an assessment of seven baseline methodologies on closed and open set attribution is presented, including robustness tests with respect to post-processing.
Leveraging Land Cover Priors for Isoprene Emission Super-Resolution
Mar 24, 2025Remote sensing plays a crucial role in monitoring Earth's ecosystems, yet satellite-derived data often suffer from limited spatial resolution, restricting their applicability in atmospheric modeling and climate research. In this work, we propose a deep learning-based Super-Resolution (SR) framework that leverages land cover information to enhance the spatial accuracy of Biogenic Volatile Organic Compounds (BVOCs) emissions, with a particular focus on isoprene. Our approach integrates land cover priors as emission drivers, capturing spatial patterns more effectively than traditional methods. We evaluate the model's performance across various climate conditions and analyze statistical correlations between isoprene emissions and key environmental information such as cropland and tree cover data. Additionally, we assess the generalization capabilities of our SR model by applying it to unseen climate zones and geographical regions. Experimental results demonstrate that incorporating land cover data significantly improves emission SR accuracy, particularly in heterogeneous landscapes. This study contributes to atmospheric chemistry and climate modeling by providing a cost-effective, data-driven approach to refining BVOC emission maps. The proposed method enhances the usability of satellite-based emissions data, supporting applications in air quality forecasting, climate impact assessments, and environmental studies.
Is JPEG AI going to change image forensics?
Dec 04, 2024



In this paper, we investigate the counter-forensic effects of the forthcoming JPEG AI standard based on neural image compression, focusing on two critical areas: deepfake image detection and image splicing localization. Neural image compression leverages advanced neural network algorithms to achieve higher compression rates while maintaining image quality. However, it introduces artifacts that closely resemble those generated by image synthesis techniques and image splicing pipelines, complicating the work of researchers when discriminating pristine from manipulated content. We comprehensively analyze JPEG AI's counter-forensic effects through extensive experiments on several state-of-the-art detectors and datasets. Our results demonstrate that an increase in false alarms impairs the performance of leading forensic detectors when analyzing genuine content processed through JPEG AI. By exposing the vulnerabilities of the available forensic tools we aim to raise the urgent need for multimedia forensics researchers to include JPEG AI images in their experimental setups and develop robust forensic techniques to distinguish between neural compression artifacts and actual manipulations.
Comparative Analysis of ASR Methods for Speech Deepfake Detection
Nov 26, 2024



Recent techniques for speech deepfake detection often rely on pre-trained self-supervised models. These systems, initially developed for Automatic Speech Recognition (ASR), have proved their ability to offer a meaningful representation of speech signals, which can benefit various tasks, including deepfake detection. In this context, pre-trained models serve as feature extractors and are used to extract embeddings from input speech, which are then fed to a binary speech deepfake detector. The remarkable accuracy achieved through this approach underscores a potential relationship between ASR and speech deepfake detection. However, this connection is not yet entirely clear, and we do not know whether improved performance in ASR corresponds to higher speech deepfake detection capabilities. In this paper, we address this question through a systematic analysis. We consider two different pre-trained self-supervised ASR models, Whisper and Wav2Vec 2.0, and adapt them for the speech deepfake detection task. These models have been released in multiple versions, with increasing number of parameters and enhanced ASR performance. We investigate whether performance improvements in ASR correlate with improvements in speech deepfake detection. Our results provide insights into the relationship between these two tasks and offer valuable guidance for the development of more effective speech deepfake detectors.
POLIPHONE: A Dataset for Smartphone Model Identification from Audio Recordings
Oct 08, 2024When dealing with multimedia data, source attribution is a key challenge from a forensic perspective. This task aims to determine how a given content was captured, providing valuable insights for various applications, including legal proceedings and integrity investigations. The source attribution problem has been addressed in different domains, from identifying the camera model used to capture specific photographs to detecting the synthetic speech generator or microphone model used to create or record given audio tracks. Recent advancements in this area rely heavily on machine learning and data-driven techniques, which often outperform traditional signal processing-based methods. However, a drawback of these systems is their need for large volumes of training data, which must reflect the latest technological trends to produce accurate and reliable predictions. This presents a significant challenge, as the rapid pace of technological progress makes it difficult to maintain datasets that are up-to-date with real-world conditions. For instance, in the task of smartphone model identification from audio recordings, the available datasets are often outdated or acquired inconsistently, making it difficult to develop solutions that are valid beyond a research environment. In this paper we present POLIPHONE, a dataset for smartphone model identification from audio recordings. It includes data from 20 recent smartphones recorded in a controlled environment to ensure reproducibility and scalability for future research. The released tracks contain audio data from various domains (i.e., speech, music, environmental sounds), making the corpus versatile and applicable to a wide range of use cases. We also present numerous experiments to benchmark the proposed dataset using a state-of-the-art classifier for smartphone model identification from audio recordings.
Explainable Artifacts for Synthetic Western Blot Source Attribution
Sep 27, 2024



Recent advancements in artificial intelligence have enabled generative models to produce synthetic scientific images that are indistinguishable from pristine ones, posing a challenge even for expert scientists habituated to working with such content. When exploited by organizations known as paper mills, which systematically generate fraudulent articles, these technologies can significantly contribute to the spread of misinformation about ungrounded science, potentially undermining trust in scientific research. While previous studies have explored black-box solutions, such as Convolutional Neural Networks, for identifying synthetic content, only some have addressed the challenge of generalizing across different models and providing insight into the artifacts in synthetic images that inform the detection process. This study aims to identify explainable artifacts generated by state-of-the-art generative models (e.g., Generative Adversarial Networks and Diffusion Models) and leverage them for open-set identification and source attribution (i.e., pointing to the model that created the image).
Freeze and Learn: Continual Learning with Selective Freezing for Speech Deepfake Detection
Sep 26, 2024



In speech deepfake detection, one of the critical aspects is developing detectors able to generalize on unseen data and distinguish fake signals across different datasets. Common approaches to this challenge involve incorporating diverse data into the training process or fine-tuning models on unseen datasets. However, these solutions can be computationally demanding and may lead to the loss of knowledge acquired from previously learned data. Continual learning techniques offer a potential solution to this problem, allowing the models to learn from unseen data without losing what they have already learned. Still, the optimal way to apply these algorithms for speech deepfake detection remains unclear, and we do not know which is the best way to apply these algorithms to the developed models. In this paper we address this aspect and investigate whether, when retraining a speech deepfake detector, it is more effective to apply continual learning across the entire model or to update only some of its layers while freezing others. Our findings, validated across multiple models, indicate that the most effective approach among the analyzed ones is to update only the weights of the initial layers, which are responsible for processing the input features of the detector.