 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Language-Driven Sequence-Level Modal-Invariant Representations for Video-Based Visible-Infrared Person Re-Identification
Jan 17, 2026The core of video-based visible-infrared person re-identification (VVI-ReID) lies in learning sequence-level modal-invariant representations across different modalities. Recent research tends to use modality-shared language prompts generated by CLIP to guide the learning of modal-invariant representations. Despite achieving optimal performance, such methods still face limitations in efficient spatial-temporal modeling, sufficient cross-modal interaction, and explicit modality-level loss guidance. To address these issues, we propose the language-driven sequence-level modal-invariant representation learning (LSMRL) method, which includes spatial-temporal feature learning (STFL) module, semantic diffusion (SD) module and cross-modal interaction (CMI) module. To enable parameter- and computation-efficient spatial-temporal modeling, the STFL module is built upon CLIP with minimal modifications. To achieve sufficient cross-modal interaction and enhance the learning of modal-invariant features, the SD module is proposed to diffuse modality-shared language prompts into visible and infrared features to establish preliminary modal consistency. The CMI module is further developed to leverage bidirectional cross-modal self-attention to eliminate residual modality gaps and refine modal-invariant representations. To explicitly enhance the learning of modal-invariant representations, two modality-level losses are introduced to improve the features' discriminative ability and their generalization to unseen categories. Extensive experiments on large-scale VVI-ReID datasets demonstrate the superiority of LSMRL over AOTA methods.
CLIP4VI-ReID: Learning Modality-shared Representations via CLIP Semantic Bridge for Visible-Infrared Person Re-identification
Nov 13, 2025This paper proposes a novel CLIP-driven modality-shared representation learning network named CLIP4VI-ReID for VI-ReID task, which consists of Text Semantic Generation (TSG), Infrared Feature Embedding (IFE), and High-level Semantic Alignment (HSA). Specifically, considering the huge gap in the physical characteristics between natural images and infrared images, the TSG is designed to generate text semantics only for visible images, thereby enabling preliminary visible-text modality alignment. Then, the IFE is proposed to rectify the feature embeddings of infrared images using the generated text semantics. This process injects id-related semantics into the shared image encoder, enhancing its adaptability to the infrared modality. Besides, with text serving as a bridge, it enables indirect visible-infrared modality alignment. Finally, the HSA is established to refine the high-level semantic alignment. This process ensures that the fine-tuned text semantics only contain id-related information, thereby achieving more accurate cross-modal alignment and enhancing the discriminability of the learned modal-shared representations. Extensive experimental results demonstrate that the proposed CLIP4VI-ReID achieves superior performance than other state-of-the-art methods on some widely used VI-ReID datasets.
Deeply Interleaved Two-Stream Encoder for Referring Video Segmentation
Mar 30, 2022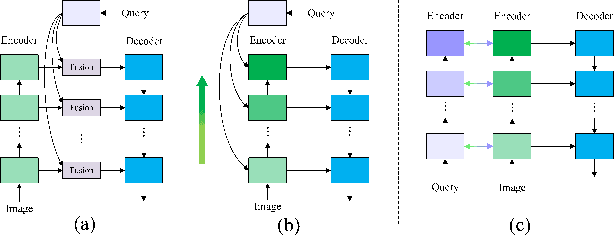
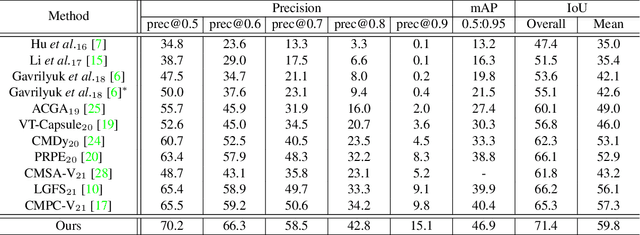
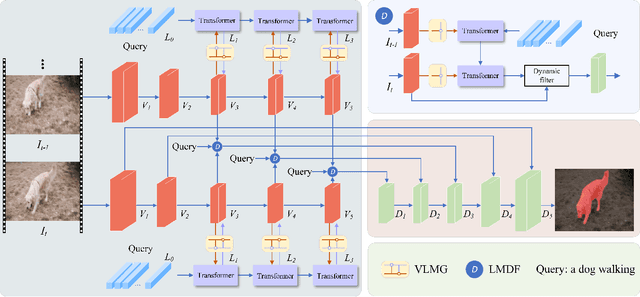
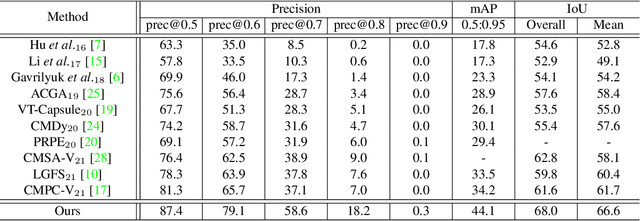
Referring video segmentation aims to segment the corresponding video object described by the language expression. To address this task, we first design a two-stream encoder to extract CNN-based visual features and transformer-based linguistic features hierarchically, and a vision-language mutual guidance (VLMG) module is inserted into the encoder multiple times to promote the hierarchical and progressive fusion of multi-modal features. Compared with the existing multi-modal fusion methods, this two-stream encoder takes into account the multi-granularity linguistic context, and realizes the deep interleaving between modalities with the help of VLGM. In order to promote the temporal alignment between frames, we further propose a language-guided multi-scale dynamic filtering (LMDF) module to strengthen the temporal coherence, which uses the language-guided spatial-temporal features to generate a set of position-specific dynamic filters to more flexibly and effectively update the feature of current frame. Extensive experiments on four datasets verify the effectiveness of the proposed model.
Encoder Fusion Network with Co-Attention Embedding for Referring Image Segmentation
May 05, 2021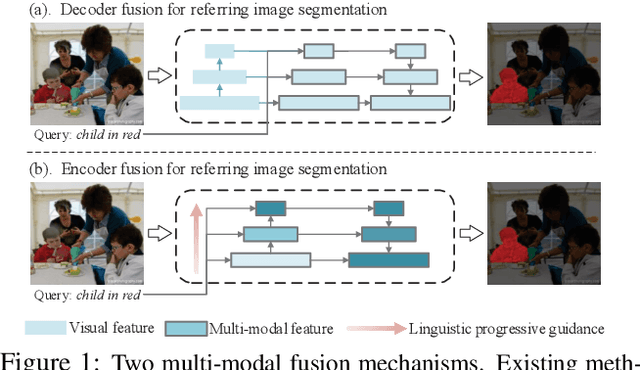
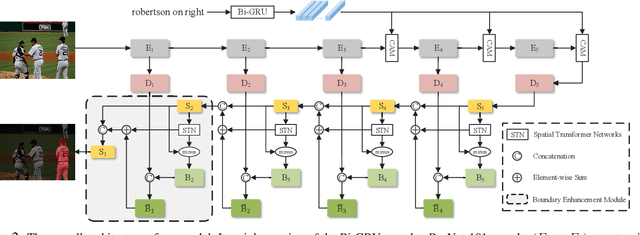
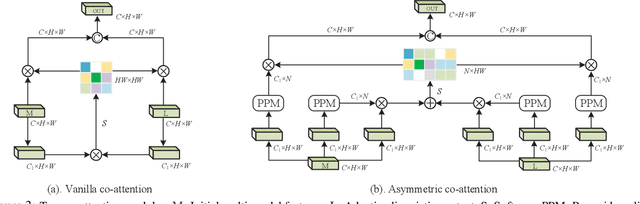
Recently, referring image segmentation has aroused widespread interest. Previous methods perform the multi-modal fusion between language and vision at the decoding side of the network. And, linguistic feature interacts with visual feature of each scale separately, which ignores the continuous guidance of language to multi-scale visual features. In this work, we propose an encoder fusion network (EFN), which transforms the visual encoder into a multi-modal feature learning network, and uses language to refine the multi-modal features progressively. Moreover, a co-attention mechanism is embedded in the EFN to realize the parallel update of multi-modal features, which can promote the consistent of the cross-modal information representation in the semantic space. Finally, we propose a boundary enhancement module (BEM) to make the network pay more attention to the fine structure. The experiment results on four benchmark datasets demonstrate that the proposed approach achieves the state-of-the-art performance under different evaluation metrics without any post-processing.