 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LAMBERT: Layout-Aware language Modeling using BERT for information extraction
Feb 19, 2020
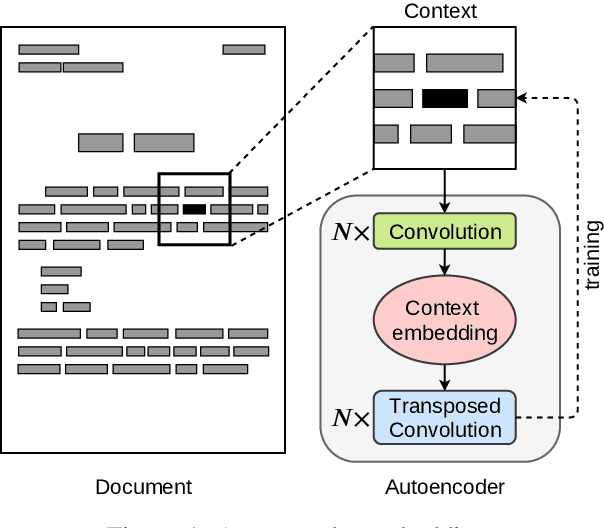
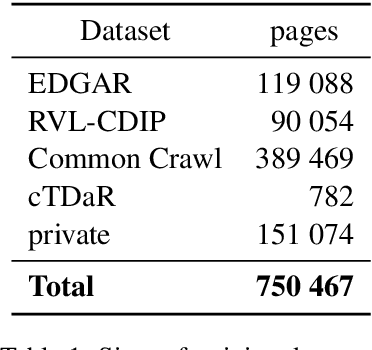
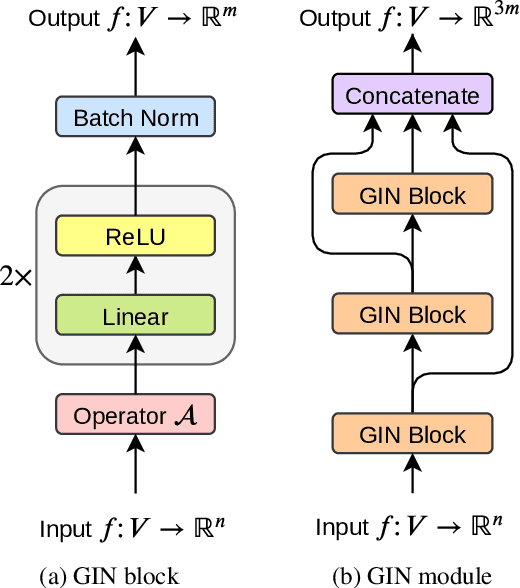
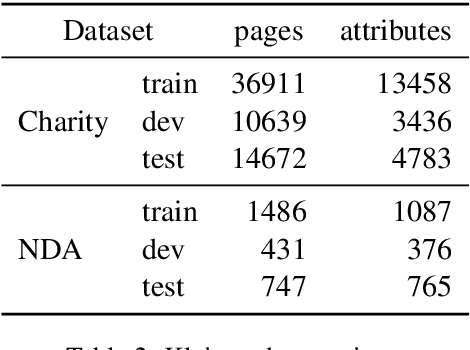
In this paper we introduce a novel approach to the problem of understanding documents where the local semantics is influenced by non-trivial layout. Namely, we modify the Transformer architecture in a way that allows it to use the graphical features defined by the layout, without the need to re-learn the language semantics from scratch, thanks to starting the training process from a model pretrained on classical language modeling tasks.
There and back again: Cycle consistency across sets for isolating factors of variation
Mar 04, 2021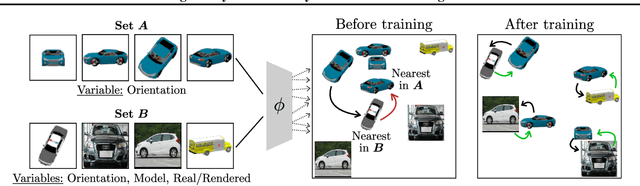



Representational learning hinges on the task of unraveling the set of underlying explanatory factors of variation in data. In this work, we operate in the setting where limited information is known about the data in the form of groupings, or set membership, where the underlying factors of variation is restricted to a subset. Our goal is to learn representations which isolate the factors of variation that are common across the groupings. Our key insight is the use of cycle consistency across sets(CCS) between the learned embeddings of images belonging to different sets. In contrast to other methods utilizing set supervision, CCS can be applied with significantly fewer constraints on the factors of variation, across a remarkably broad range of settings, and only utilizing set membership for some fraction of the training data. By curating datasets from Shapes3D, we quantify the effectiveness of CCS through mutual information between the learned representations and the known generative factors. In addition, we demonstrate the applicability of CCS to the tasks of digit style isolation and synthetic-to-real object pose transfer and compare to generative approaches utilizing the same supervision.
Dense Regression Activation Maps For Lesion Segmentation in CT scans of COVID-19 patients
May 25, 2021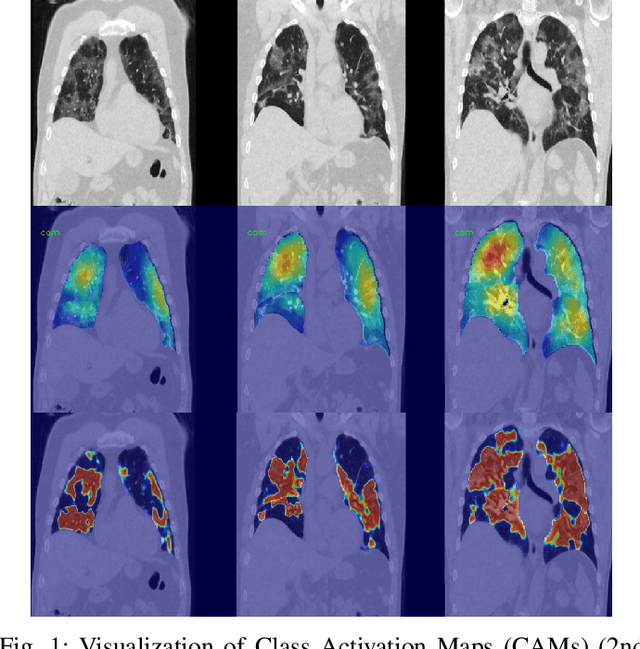
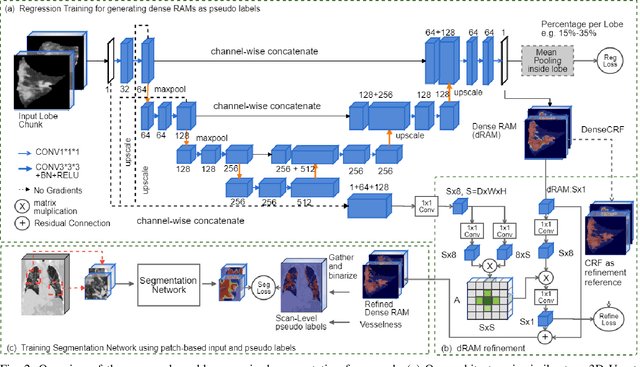

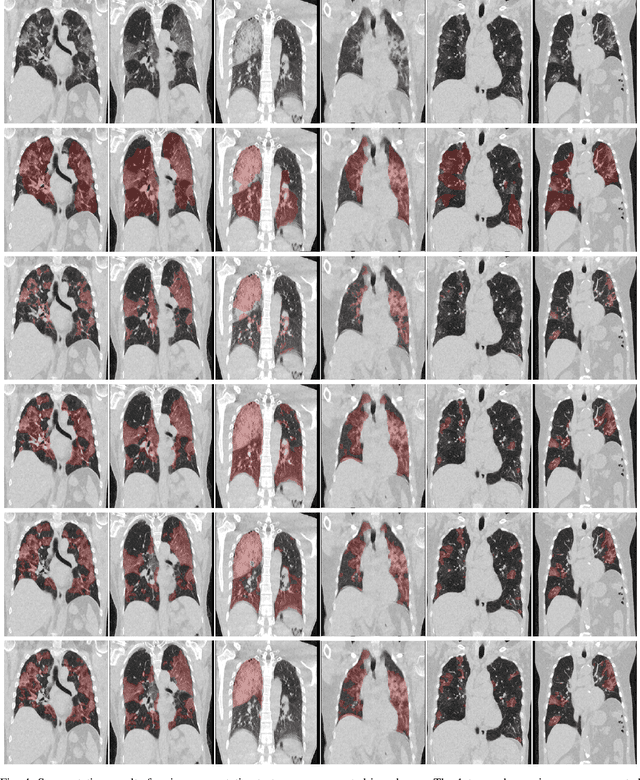
Automatic lesion segmentation on thoracic CT enables rapid quantitative analysis of lung involvement in COVID- 19 infections. Obtaining voxel-level annotations for training segmentation networks is prohibitively expensive. Therefore we propose a weakly-supervised segmentation method based on dense regression activation maps (dRAM). Most advanced weakly supervised segmentation approaches exploit class activation maps (CAMs) to localize objects generated from high-level semantic features at a coarse resolution. As a result, CAMs provide coarse outlines that do not align precisely with the object segmentations. Instead, we exploit dense features from a segmentation network to compute dense regression activation maps (dRAMs) for preserving local details. During training, dRAMs are pooled lobe-wise to regress the per-lobe lesion percentage. In such a way, the network achieves additional information regarding the lesion quantification in comparison with the classification approach. Furthermore, we refine dRAMs based on an attention module and dense conditional random field trained together with the main regression task. The refined dRAMs are served as the pseudo labels for training a final segmentation network. When evaluated on 69 CT scans, our method substantially improves the intersection over union from 0.335 in the CAM-based weakly supervised segmentation method to 0.495.
Understanding and Improvement of Adversarial Training for Network Embedding from an Optimization Perspective
May 17, 2021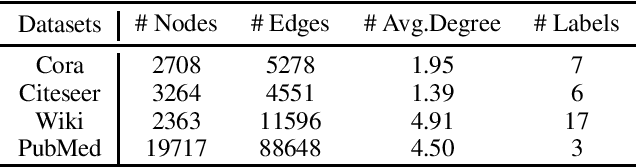



Network Embedding aims to learn a function mapping the nodes to Euclidean space contribute to multiple learning analysis tasks on networks. However, the noisy information behind the real-world networks and the overfitting problem both negatively impact the quality of embedding vectors. To tackle these problems, researchers utilize Adversarial Training for Network Embedding (AdvTNE) and achieve state-of-the-art performance. Unlike the mainstream methods introducing perturbations on the network structure or the data feature, AdvTNE directly perturbs the model parameters, which provides a new chance to understand the mechanism behind. In this paper, we explain AdvTNE theoretically from an optimization perspective. Considering the Power-law property of networks and the optimization objective, we analyze the reason for its excellent results. According to the above analysis, we propose a new activation to enhance the performance of AdvTNE. We conduct extensive experiments on four real networks to validate the effectiveness of our method in node classification and link prediction. The results demonstrate that our method is superior to the state-of-the-art baseline methods.
Stable Online Control of Linear Time-Varying Systems
Apr 30, 2021
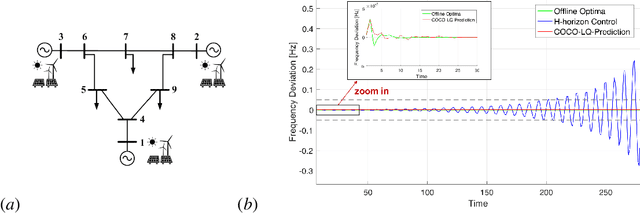

Linear time-varying (LTV) systems are widely used for modeling real-world dynamical systems due to their generality and simplicity. Providing stability guarantees for LTV systems is one of the central problems in control theory. However, existing approaches that guarantee stability typically lead to significantly sub-optimal cumulative control cost in online settings where only current or short-term system information is available. In this work, we propose an efficient online control algorithm, COvariance Constrained Online Linear Quadratic (COCO-LQ) control, that guarantees input-to-state stability for a large class of LTV systems while also minimizing the control cost. The proposed method incorporates a state covariance constraint into the semi-definite programming (SDP) formulation of the LQ optimal controller. We empirically demonstrate the performance of COCO-LQ in both synthetic experiments and a power system frequency control example.
Latent Variable Models for Visual Question Answering
Jan 16, 2021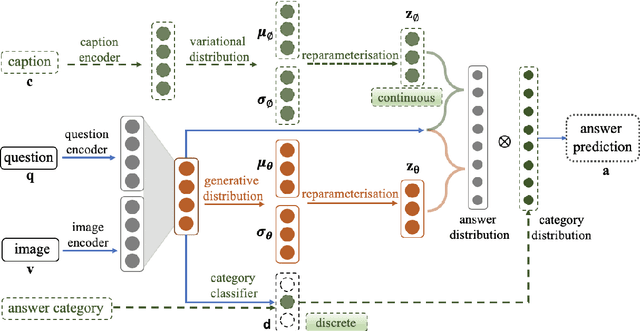
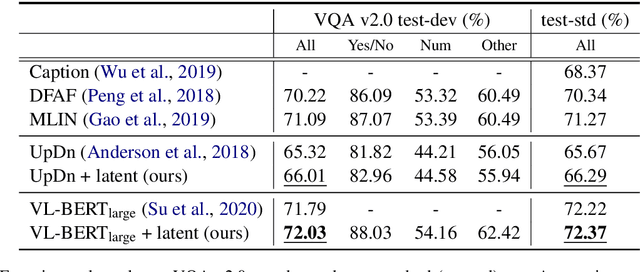

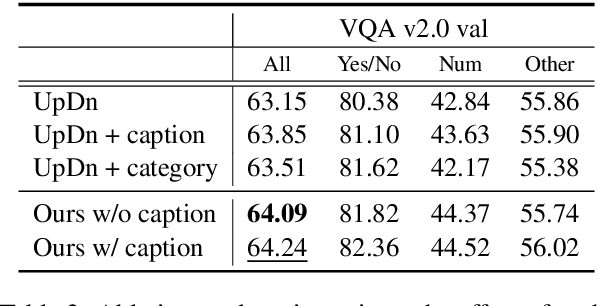
Conventional models for Visual Question Answering (VQA) explore deterministic approaches with various types of image features, question features, and attention mechanisms. However, there exist other modalities that can be explored in addition to image and question pairs to bring extra information to the models. In this work, we propose latent variable models for VQA where extra information (e.g. captions and answer categories) are incorporated as latent variables to improve inference, which in turn benefits question-answering performance. Experiments on the VQA v2.0 benchmarking dataset demonstrate the effectiveness of our proposed models in that they improve over strong baselines, especially those that do not rely on extensive language-vision pre-training.
AdaFuse: Adaptive Temporal Fusion Network for Efficient Action Recognition
Feb 10, 2021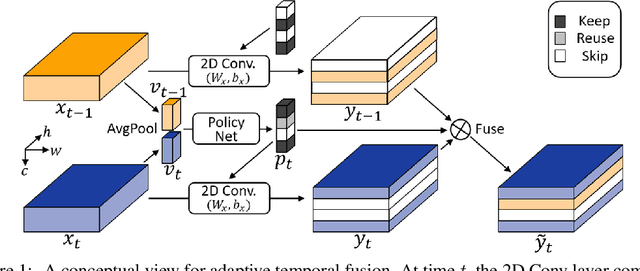

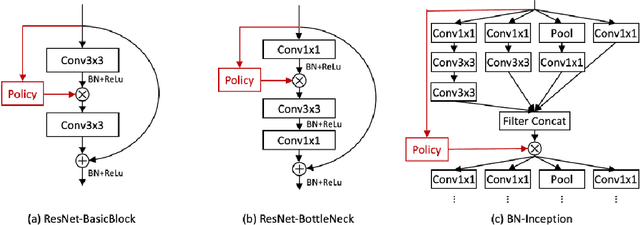
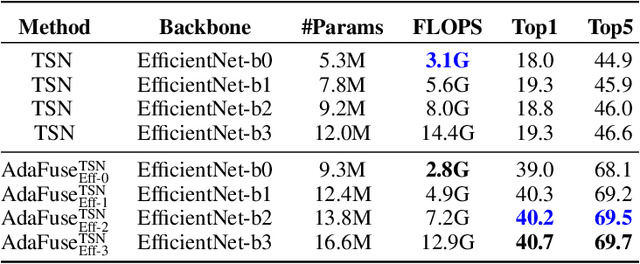
Temporal modelling is the key for efficient video action recognition. While understanding temporal information can improve recognition accuracy for dynamic actions, removing temporal redundancy and reusing past features can significantly save computation leading to efficient action recognition. In this paper, we introduce an adaptive temporal fusion network, called AdaFuse, that dynamically fuses channels from current and past feature maps for strong temporal modelling. Specifically, the necessary information from the historical convolution feature maps is fused with current pruned feature maps with the goal of improving both recognition accuracy and efficiency. In addition, we use a skipping operation to further reduce the computation cost of action recognition. Extensive experiments on Something V1 & V2, Jester and Mini-Kinetics show that our approach can achieve about 40% computation savings with comparable accuracy to state-of-the-art methods. The project page can be found at https://mengyuest.github.io/AdaFuse/
Incorporating Prior Information in Compressive Online Robust Principal Component Analysis
May 27, 2017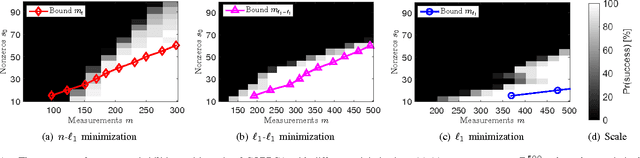
We consider an online version of the robust Principle Component Analysis (PCA), which arises naturally in time-varying source separations such as video foreground-background separation. This paper proposes a compressive online robust PCA with prior information for recursively separating a sequences of frames into sparse and low-rank components from a small set of measurements. In contrast to conventional batch-based PCA, which processes all the frames directly, the proposed method processes measurements taken from each frame. Moreover, this method can efficiently incorporate multiple prior information, namely previous reconstructed frames, to improve the separation and thereafter, update the prior information for the next frame. We utilize multiple prior information by solving $n\text{-}\ell_{1}$ minimization for incorporating the previous sparse components and using incremental singular value decomposition ($\mathrm{SVD}$) for exploiting the previous low-rank components. We also establish theoretical bounds on the number of measurements required to guarantee successful separation under assumptions of static or slowly-changing low-rank components. Using numerical experiments, we evaluate our bounds and the performance of the proposed algorithm. In addition, we apply the proposed algorithm to online video foreground and background separation from compressive measurements. Experimental results show that the proposed method outperforms the existing methods.
Learning Dynamics via Graph Neural Networks for Human Pose Estimation and Tracking
Jun 07, 2021
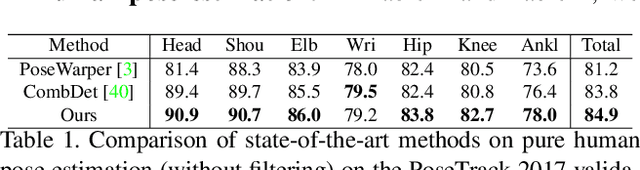
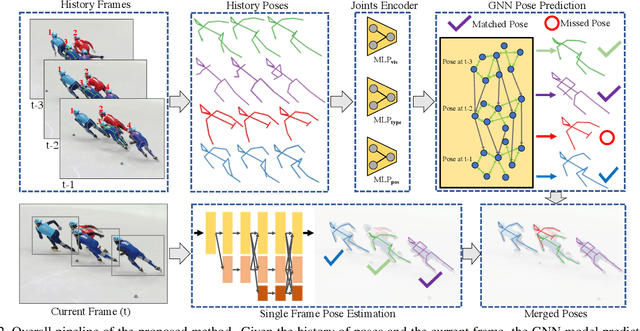
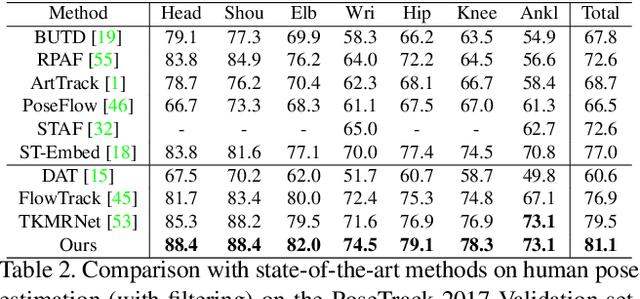
Multi-person pose estimation and tracking serve as crucial steps for video understanding. Most state-of-the-art approaches rely on first estimating poses in each frame and only then implementing data association and refinement. Despite the promising results achieved, such a strategy is inevitably prone to missed detections especially in heavily-cluttered scenes, since this tracking-by-detection paradigm is, by nature, largely dependent on visual evidences that are absent in the case of occlusion. In this paper, we propose a novel online approach to learning the pose dynamics, which are independent of pose detections in current fame, and hence may serve as a robust estimation even in challenging scenarios including occlusion. Specifically, we derive this prediction of dynamics through a graph neural network~(GNN) that explicitly accounts for both spatial-temporal and visual information. It takes as input the historical pose tracklets and directly predicts the corresponding poses in the following frame for each tracklet. The predicted poses will then be aggregated with the detected poses, if any, at the same frame so as to produce the final pose, potentially recovering the occluded joints missed by the estimator. Experiments on PoseTrack 2017 and PoseTrack 2018 datasets demonstrate that the proposed method achieves results superior to the state of the art on both human pose estimation and tracking tasks.
Densely Nested Top-Down Flows for Salient Object Detection
Feb 18, 2021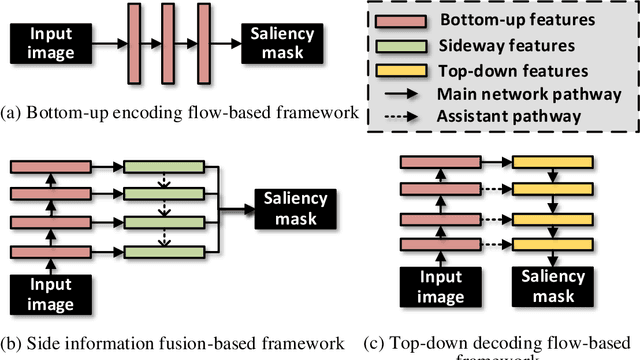
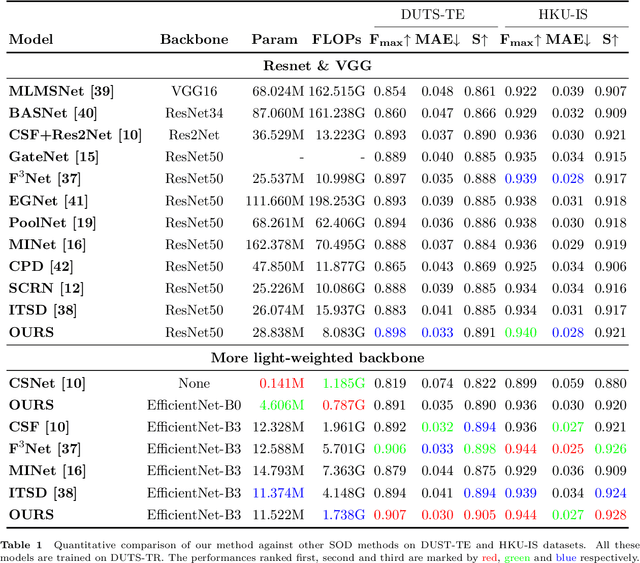
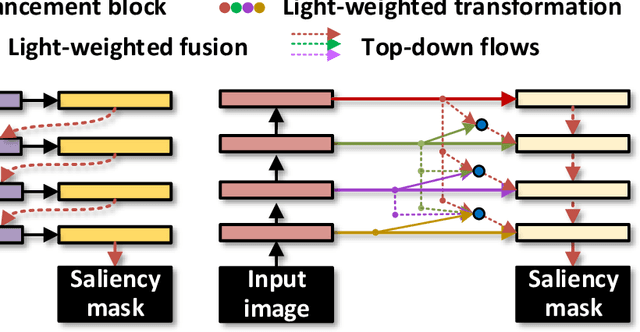
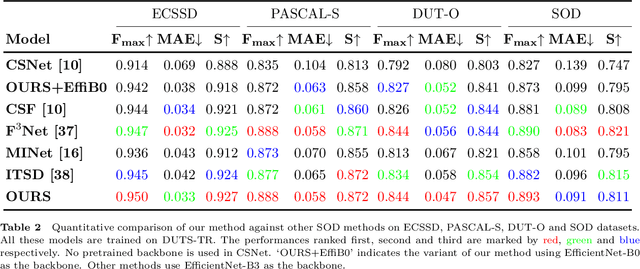
With the goal of identifying pixel-wise salient object regions from each input image, salient object detection (SOD) has been receiving great attention in recent years. One kind of mainstream SOD methods is formed by a bottom-up feature encoding procedure and a top-down information decoding procedure. While numerous approaches have explored the bottom-up feature extraction for this task, the design on top-down flows still remains under-studied. To this end, this paper revisits the role of top-down modeling in salient object detection and designs a novel densely nested top-down flows (DNTDF)-based framework. In every stage of DNTDF, features from higher levels are read in via the progressive compression shortcut paths (PCSP). The notable characteristics of our proposed method are as follows. 1) The propagation of high-level features which usually have relatively strong semantic information is enhanced in the decoding procedure; 2) With the help of PCSP, the gradient vanishing issues caused by non-linear operations in top-down information flows can be alleviated; 3) Thanks to the full exploration of high-level features, the decoding process of our method is relatively memory efficient compared against those of existing methods. Integrating DNTDF with EfficientNet, we construct a highly light-weighted SOD model, with very low computational complexity. To demonstrate the effectiveness of the proposed model, comprehensive experiments are conducted on six widely-used benchmark datasets. The comparisons to the most state-of-the-art methods as well as the carefully-designed baseline models verify our insights on the top-down flow modeling for SOD. The code of this paper is available at https://github.com/new-stone-object/DNTD.