 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Geometry of Activity Cliffs: Representation Dependence and Multi-Scale Characterization of Activity Landscapes
May 29, 2026Activity cliffs, structurally similar compounds with large potency differences, are widely treated as intrinsic features of chemical datasets. We argue that apart from target biology, much of our cliff understanding is a consequence of the geometry induced by the chosen molecular representation, not a property of a molecule pair itself. We designed a six-step pipeline to systematically test this hypothesis. The pipeline consists of: assessing pairwise distance geometry, cliff enrichment, activity gradient distribution, persistent homology of the cliff subspace, predictive benchmarking for a chosen pair of an embedding and a metric, and eventually, analysis of the matched molecular pairs and stereoisomers. We applied the pipeline to fifteen configurations of embeddings and metrics to build a benchmark across three distinctive datasets known of activity cliffs challenges. No representation excels on all criteria: Morgan Tanimoto provides the strongest cliff enrichment and cross-scaffold generalization; MolFormer cosine provides the only meaningful stereochemical sensitivity; MACCS and RDKit Dice fingerprints are most sensitive to matched-molecular-pair transformations; ChemBERTa fails uniformly due to embedding collapse. These findings are not a ranking. They reflect the fact that different representations encode different aspects of molecular recognition, and that choosing one implicitly defines what an activity cliff actually is.
An explainable hypothesis-driven approach to Drug-Induced Liver Injury with HADES
May 06, 2026Drug-induced liver injury (DILI) remains a leading cause of late-stage clinical trial attrition. However, existing computational predictors primarily rely on binary classification, a framing that limits generalization and yields no mechanistic insight to guide translational decisions. We argue that DILI prediction is better posed as an explainable hypothesis-generation problem. To support this shift, we introduce the DILER Benchmark, a dataset that extends beyond binary labels by augmenting a curated set of molecules with mechanistic hepatotoxicity hypotheses derived from biomedical literature. We further present HADES, an agentic system designed to generate transparent and auditable reasoning traces. By combining molecular-level predictions, metabolite decomposition, structural understanding, and toxicity pathway evidence, HADES mechanistically assesses DILI risk. Evaluated on the DILER Benchmark, HADES outperforms existing models in binary classification, achieving a ROC-AUC of 0.68 on the Test Set and 0.59 on the challenging Post-2021 Set, compared with 0.63 and 0.50 for DILI-Predictor, respectively. More importantly, we establish a baseline for mechanistic hypothesis generation, where HADES achieves a Hypothesis Alignment Fuzzy Jaccard Index of 0.16. This result underscores the inherent complexity of the task while highlighting the need for advanced explainable approaches in predictive toxicology.
Bolek: A Multimodal Language Model for Molecular Reasoning
May 04, 2026Molecular property models increasingly support high-stakes drug-discovery decisions, but their outputs are often difficult to audit: classical predictors return scores without rationale, while language models can produce fluent explanations weakly grounded in the input molecule. We introduce Bolek, a compact multimodal language model that grounds natural-language reasoning in molecular structure by injecting a Morgan fingerprint embedding into an instruction-tuned text decoder. Bolek is fine-tuned on molecular alignment tasks, including molecule description, RDKit descriptor prediction, and substructure detection, and on downstream reasoning over 15 TDC binary classification tasks using synthetic chains-of-thought anchored in concrete molecular features. Across these tasks, Bolek outperforms its Qwen3-4B-Instruct base on all endpoints in yes/no mode and on 13 of 15 in chain-of-thought mode, raising mean ROC/PR AUC from 0.55 to 0.76. It also outperforms TxGemma-9B-Chat on 13 of 15 binary classification tasks despite being less than half its size. Bolek's explanations are more grounded than those of the baseline LLMs: it cites numerical descriptors 10-100x more often per chain-of-thought, and the cited values agree strongly with RDKit for key descriptors such as TPSA, MolLogP, and MolWt (Spearman rho = 0.87-0.91). Generalisation extends beyond the training panel: on 15 unseen TDC classification endpoints, Bolek matches TxGemma on five, and it produces non-trivial rank correlations on three held-out regression endpoints despite never seeing downstream regression during training. These results suggest that targeted modality injection and reasoning supervision tied to verifiable molecular features can yield compact, auditable molecular reasoning models.
Kleister: Key Information Extraction Datasets Involving Long Documents with Complex Layouts
May 12, 2021
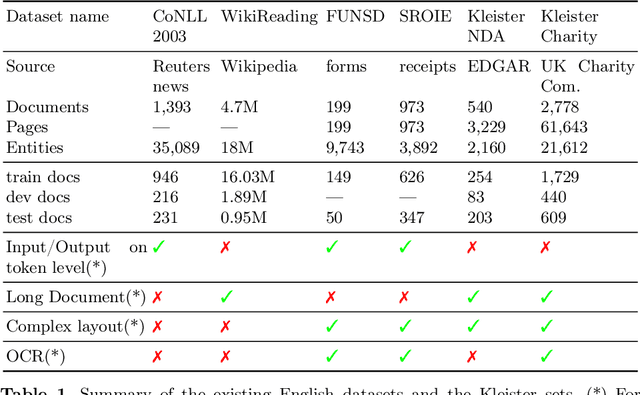
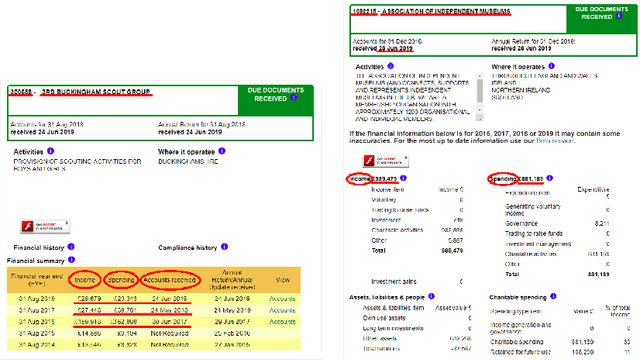
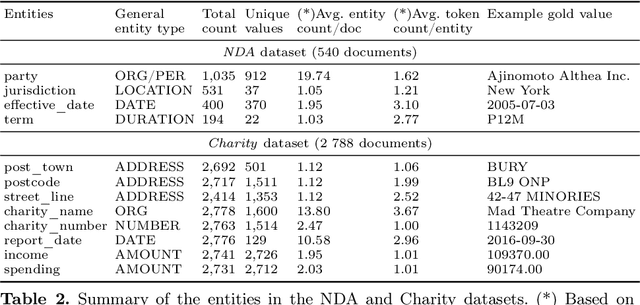
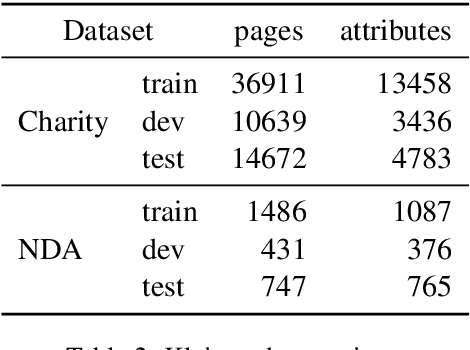
The relevance of the Key Information Extraction (KIE) task is increasingly important in natural language processing problems. But there are still only a few well-defined problems that serve as benchmarks for solutions in this area. To bridge this gap, we introduce two new datasets (Kleister NDA and Kleister Charity). They involve a mix of scanned and born-digital long formal English-language documents. In these datasets, an NLP system is expected to find or infer various types of entities by employing both textual and structural layout features. The Kleister Charity dataset consists of 2,788 annual financial reports of charity organizations, with 61,643 unique pages and 21,612 entities to extract. The Kleister NDA dataset has 540 Non-disclosure Agreements, with 3,229 unique pages and 2,160 entities to extract. We provide several state-of-the-art baseline systems from the KIE domain (Flair, BERT, RoBERTa, LayoutLM, LAMBERT), which show that our datasets pose a strong challenge to existing models. The best model achieved an 81.77% and an 83.57% F1-score on respectively the Kleister NDA and the Kleister Charity datasets. We share the datasets to encourage progress on more in-depth and complex information extraction tasks.
Kleister: A novel task for Information Extraction involving Long Documents with Complex Layout
Mar 06, 2020
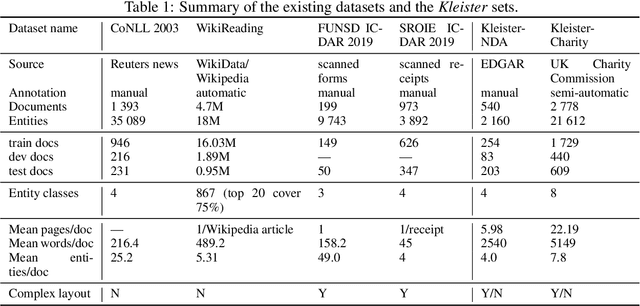

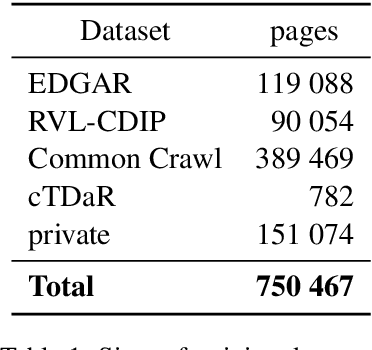
State-of-the-art solutions for Natural Language Processing (NLP) are able to capture a broad range of contexts, like the sentence-level context or document-level context for short documents. But these solutions are still struggling when it comes to longer, real-world documents with the information encoded in the spatial structure of the document, such as page elements like tables, forms, headers, openings or footers; complex page layout or presence of multiple pages. To encourage progress on deeper and more complex Information Extraction (IE) we introduce a new task (named Kleister) with two new datasets. Utilizing both textual and structural layout features, an NLP system must find the most important information, about various types of entities, in long formal documents. We propose Pipeline method as a text-only baseline with different Named Entity Recognition architectures (Flair, BERT, RoBERTa). Moreover, we checked the most popular PDF processing tools for text extraction (pdf2djvu, Tesseract and Textract) in order to analyze behavior of IE system in presence of errors introduced by these tools.
LAMBERT: Layout-Aware language Modeling using BERT for information extraction
Mar 06, 2020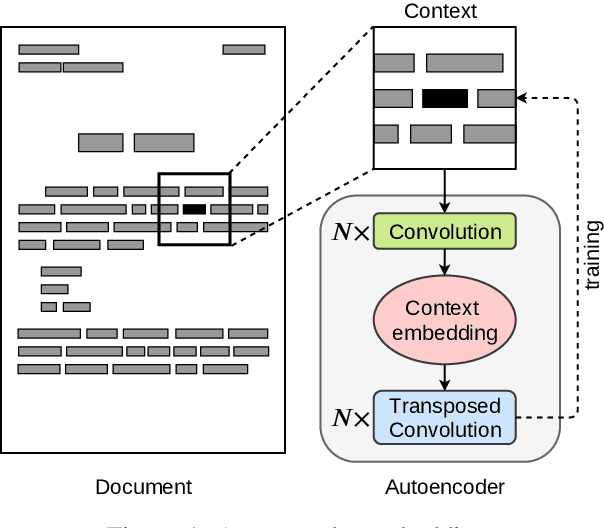
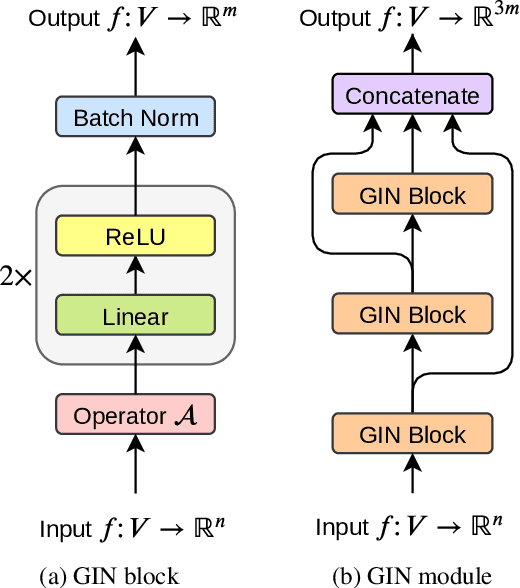
In this paper we introduce a novel approach to the problem of understanding documents where the local semantics is influenced by non-trivial layout. Namely, we modify the Transformer architecture in a way that allows it to use the graphical features defined by the layout, without the need to re-learn the language semantics from scratch, thanks to starting the training process from a model pretrained on classical language modeling tasks.