 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioResearcher: Scenario-Guided Multi-Agent for Translational Medicine
May 07, 2026Translational medicine turns underspecified development goals into evidence synthesis that must combine literature, trials, patents, and quantitative multi-omics analysis while preserving identifiers, uncertainty, and retrievable provenance. General-purpose foundation models and off-the-shelf tool-augmented or multi-agent systems are not built for this: they tend to produce single-shot answers or run open-endedly, and fall short on the auditable, scenario-specific workflows that heterogeneous biomedical sources demand. This paper introduces Ingenix BioResearcher, a scenario-guided multi-agent system that maps queries to versioned research playbooks, delegates to specialized subagents over 30+ tools and machine-learning endpoints, mixes structured database access with sandboxed code for genome-scale analyses, and applies claim-level multi-model reconciliation before editorial assembly. We evaluate BioResearcher across unit-level capabilities, open-ended biomedical reasoning, and end-to-end clinical discovery. It leads evaluated baselines on 109 single-step tests (83.49% pass rate; 0.892 average score), achieves strong biomedical benchmark performance (89.33% on BixBench-Verified-50 and the top 0.758 mean score on BaisBench Scientific Discovery), and leads on a 30-query clinical end-to-end benchmark with the highest positive hit rate (74.7% $\pm$ 3.3%) and negative clear rate (96.8% $\pm$ 0.2%). These results show broad, competitive performance across unit-level, open-ended, and end-to-end clinical evaluations.
Document Understanding Dataset and Evaluation (DUDE)
May 15, 2023



We call on the Document AI (DocAI) community to reevaluate current methodologies and embrace the challenge of creating more practically-oriented benchmarks. Document Understanding Dataset and Evaluation (DUDE) seeks to remediate the halted research progress in understanding visually-rich documents (VRDs). We present a new dataset with novelties related to types of questions, answers, and document layouts based on multi-industry, multi-domain, and multi-page VRDs of various origins, and dates. Moreover, we are pushing the boundaries of current methods by creating multi-task and multi-domain evaluation setups that more accurately simulate real-world situations where powerful generalization and adaptation under low-resource settings are desired. DUDE aims to set a new standard as a more practical, long-standing benchmark for the community, and we hope that it will lead to future extensions and contributions that address real-world challenges. Finally, our work illustrates the importance of finding more efficient ways to model language, images, and layout in DocAI.
Going Full-TILT Boogie on Document Understanding with Text-Image-Layout Transformer
Mar 02, 2021We address the challenging problem of Natural Language Comprehension beyond plain-text documents by introducing the TILT neural network architecture which simultaneously learns layout information, visual features, and textual semantics. Contrary to previous approaches, we rely on a decoder capable of unifying a variety of problems involving natural language. The layout is represented as an attention bias and complemented with contextualized visual information, while the core of our model is a pretrained encoder-decoder Transformer. Our novel approach achieves state-of-the-art results in extracting information from documents and answering questions which demand layout understanding (DocVQA, CORD, WikiOps, SROIE). At the same time, we simplify the process by employing an end-to-end model.
LAMBERT: Layout-Aware language Modeling using BERT for information extraction
Mar 06, 2020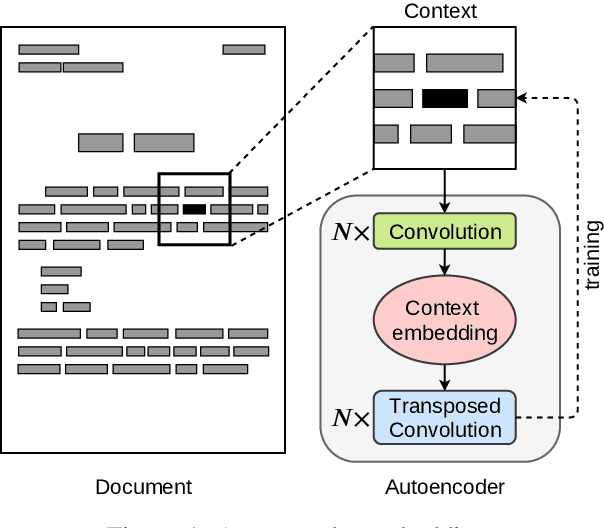
In this paper we introduce a novel approach to the problem of understanding documents where the local semantics is influenced by non-trivial layout. Namely, we modify the Transformer architecture in a way that allows it to use the graphical features defined by the layout, without the need to re-learn the language semantics from scratch, thanks to starting the training process from a model pretrained on classical language modeling tasks.