 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Modulation Network for Audio-Visual Event Localization
Aug 26, 2021
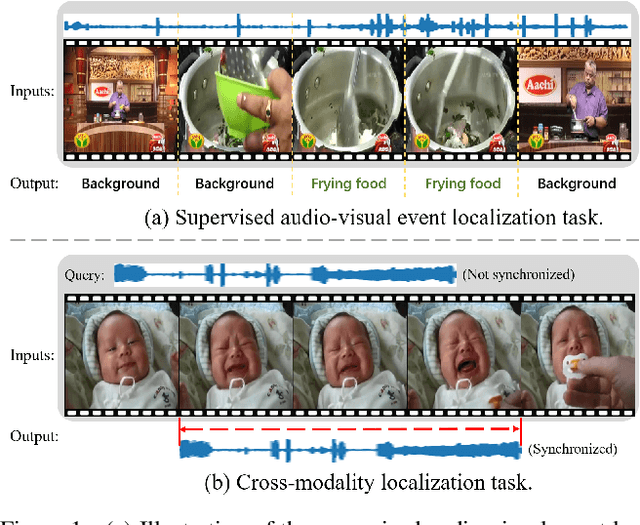

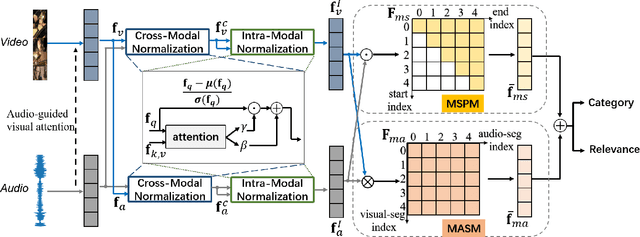
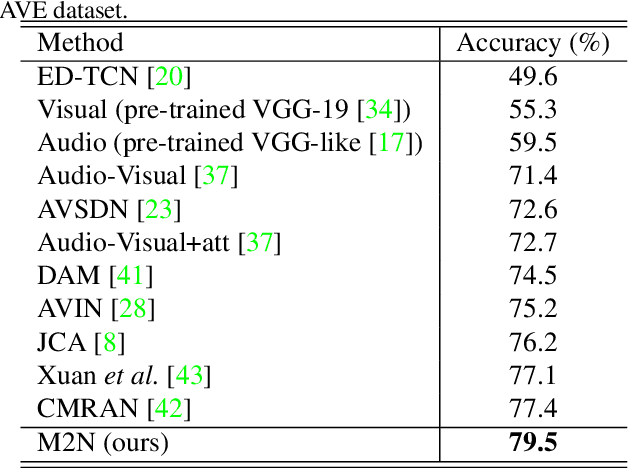
We study the problem of localizing audio-visual events that are both audible and visible in a video. Existing works focus on encoding and aligning audio and visual features at the segment level while neglecting informative correlation between segments of the two modalities and between multi-scale event proposals. We propose a novel MultiModulation Network (M2N) to learn the above correlation and leverage it as semantic guidance to modulate the related auditory, visual, and fused features. In particular, during feature encoding, we propose cross-modal normalization and intra-modal normalization. The former modulates the features of two modalities by establishing and exploiting the cross-modal relationship. The latter modulates the features of a single modality with the event-relevant semantic guidance of the same modality. In the fusion stage,we propose a multi-scale proposal modulating module and a multi-alignment segment modulating module to introduce multi-scale event proposals and enable dense matching between cross-modal segments. With the auditory, visual, and fused features modulated by the correlation information regarding audio-visual events, M2N performs accurate event localization. Extensive experiments conducted on the AVE dataset demonstrate that our proposed method outperforms the state of the art in both supervised event localization and cross-modality localization.
Fairness-Aware Unsupervised Feature Selection
Jun 04, 2021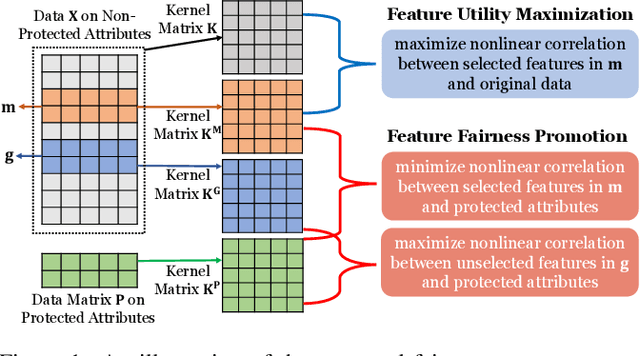

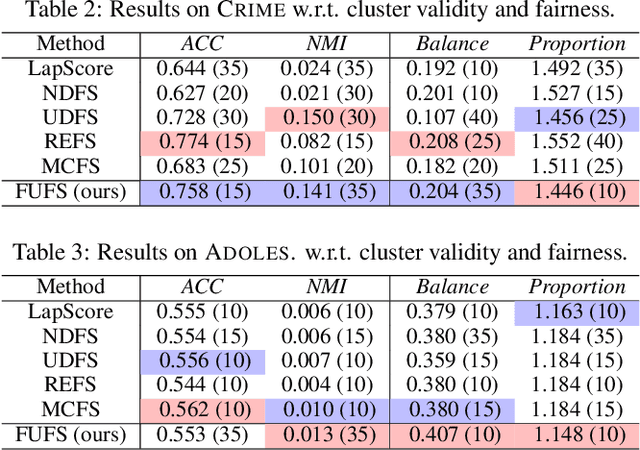
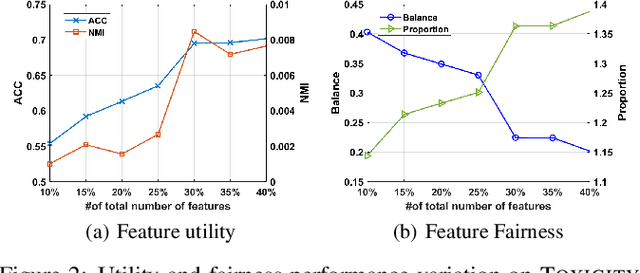
Feature selection is a prevalent data preprocessing paradigm for various learning tasks. Due to the expensive cost of acquiring supervision information, unsupervised feature selection sparks great interests recently. However, existing unsupervised feature selection algorithms do not have fairness considerations and suffer from a high risk of amplifying discrimination by selecting features that are over associated with protected attributes such as gender, race, and ethnicity. In this paper, we make an initial investigation of the fairness-aware unsupervised feature selection problem and develop a principled framework, which leverages kernel alignment to find a subset of high-quality features that can best preserve the information in the original feature space while being minimally correlated with protected attributes. Specifically, different from the mainstream in-processing debiasing methods, our proposed framework can be regarded as a model-agnostic debiasing strategy that eliminates biases and discrimination before downstream learning algorithms are involved. Experimental results on multiple real-world datasets demonstrate that our framework achieves a good trade-off between utility maximization and fairness promotion.
Learning to Diversify for Single Domain Generalization
Aug 26, 2021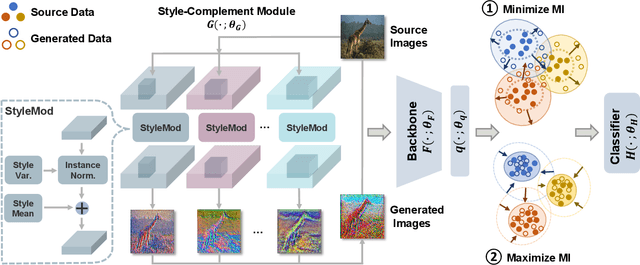
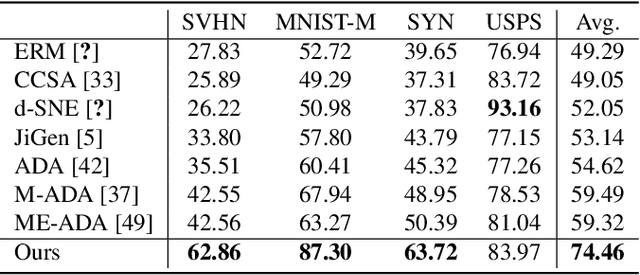
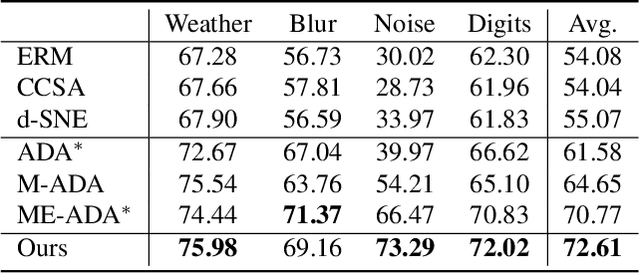
Domain generalization (DG) aims to generalize a model trained on multiple source (i.e., training) domains to a distributionally different target (i.e., test) domain. In contrast to the conventional DG that strictly requires the availability of multiple source domains, this paper considers a more realistic yet challenging scenario, namely Single Domain Generalization (Single-DG), where only one source domain is available for training. In this scenario, the limited diversity may jeopardize the model generalization on unseen target domains. To tackle this problem, we propose a style-complement module to enhance the generalization power of the model by synthesizing images from diverse distributions that are complementary to the source ones. More specifically, we adopt a tractable upper bound of mutual information (MI) between the generated and source samples and perform a two-step optimization iteratively: (1) by minimizing the MI upper bound approximation for each sample pair, the generated images are forced to be diversified from the source samples; (2) subsequently, we maximize the MI between the samples from the same semantic category, which assists the network to learn discriminative features from diverse-styled images. Extensive experiments on three benchmark datasets demonstrate the superiority of our approach, which surpasses the state-of-the-art single-DG methods by up to 25.14%.
CVLight: Deep Reinforcement Learning for Adaptive Traffic Signal Control with Connected Vehicles
Apr 21, 2021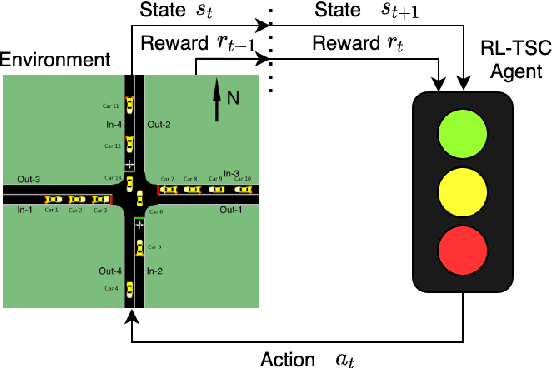
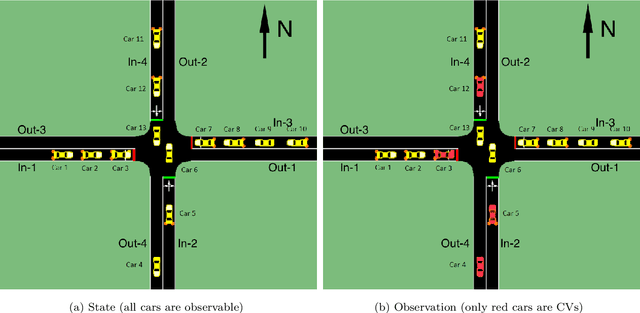

This paper develops a reinforcement learning (RL) scheme for adaptive traffic signal control (ATSC), called "CVLight", that leverages data collected only from connected vehicles (CV). Seven types of RL models are proposed within this scheme that contain various state and reward representations, including incorporation of CV delay and green light duration into state and the usage of CV delay as reward. To further incorporate information of both CV and non-CV into CVLight, an algorithm based on actor-critic, A2C-Full, is proposed where both CV and non-CV information is used to train the critic network, while only CV information is used to update the policy network and execute optimal signal timing. These models are compared at an isolated intersection under various CV market penetration rates. A full model with the best performance (i.e., minimum average travel delay per vehicle) is then selected and applied to compare with state-of-the-art benchmarks under different levels of traffic demands, turning proportions, and dynamic traffic demands, respectively. Two case studies are performed on an isolated intersection and a corridor with three consecutive intersections located in Manhattan, New York, to further demonstrate the effectiveness of the proposed algorithm under real-world scenarios. Compared to other baseline models that use all vehicle information, the trained CVLight agent can efficiently control multiple intersections solely based on CV data and can achieve a similar or even greater performance when the CV penetration rate is no less than 20%.
Unsupervised Domain Adaptation in LiDAR Semantic Segmentation with Self-Supervision and Gated Adapters
Jul 20, 2021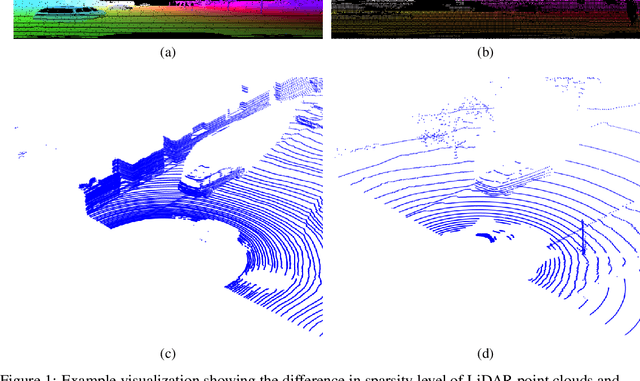
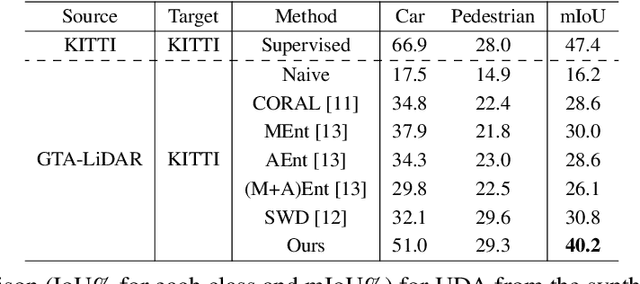
In this paper, we focus on a less explored, but more realistic and complex problem of domain adaptation in LiDAR semantic segmentation. There is a significant drop in performance of an existing segmentation model when training (source domain) and testing (target domain) data originate from different LiDAR sensors. To overcome this shortcoming, we propose an unsupervised domain adaptation framework that leverages unlabeled target domain data for self-supervision, coupled with an unpaired mask transfer strategy to mitigate the impact of domain shifts. Furthermore, we introduce gated adapter modules with a small number of parameters into the network to account for target domain-specific information. Experiments adapting from both real-to-real and synthetic-to-real LiDAR semantic segmentation benchmarks demonstrate the significant improvement over prior arts.
Improving Breast Cancer Detection using Symmetry Information with Deep Learning
Aug 17, 2018
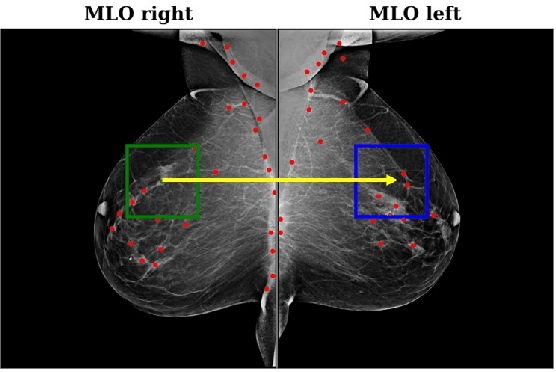
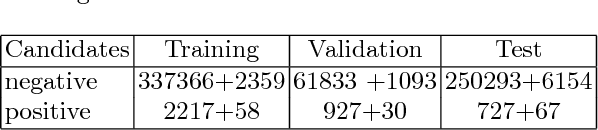
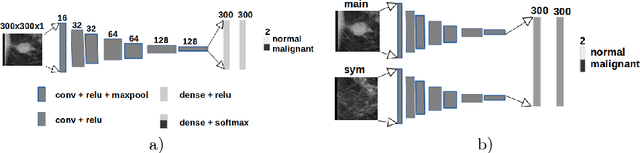
Convolutional Neural Networks (CNN) have had a huge success in many areas of computer vision and medical image analysis. However, there is still an immense potential for performance improvement in mammogram breast cancer detection Computer-Aided Detection (CAD) systems by integrating all the information that the radiologist utilizes, such as symmetry and temporal data. In this work, we proposed a patch based multi-input CNN that learns symmetrical difference to detect breast masses. The network was trained on a large-scale dataset of 28294 mammogram images. The performance was compared to a baseline architecture without symmetry context using Area Under the ROC Curve (AUC) and Competition Performance Metric (CPM). At candidate level, AUC value of 0.933 with 95% confidence interval of [0.920, 0.954] was obtained when symmetry information is incorporated in comparison with baseline architecture which yielded AUC value of 0.929 with [0.919, 0.947] confidence interval. By incorporating symmetrical information, although there was no a significant candidate level performance again (p = 0.111), we have found a compelling result at exam level with CPM value of 0.733 (p = 0.001). We believe that including temporal data, and adding benign class to the dataset could improve the detection performance.
PeaceGAN: A GAN-based Multi-Task Learning Method for SAR Target Image Generation with a Pose Estimator and an Auxiliary Classifier
Mar 29, 2021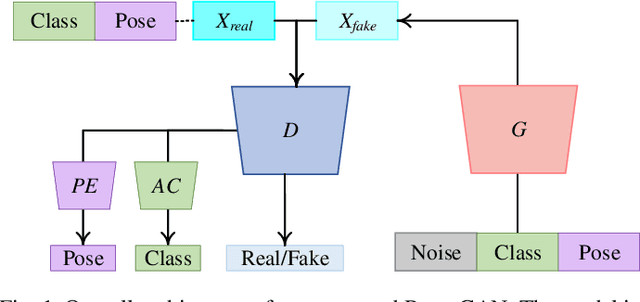
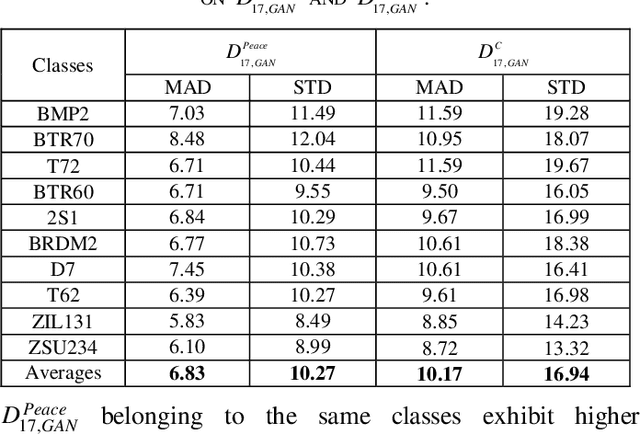
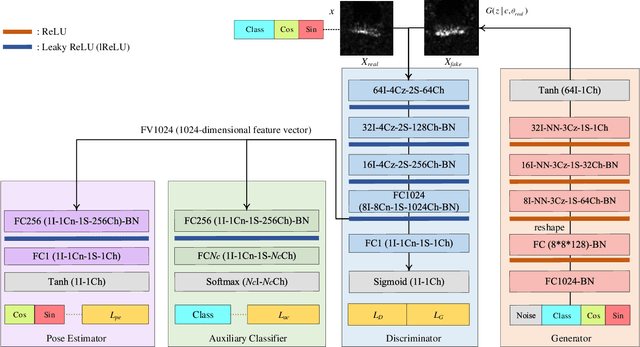
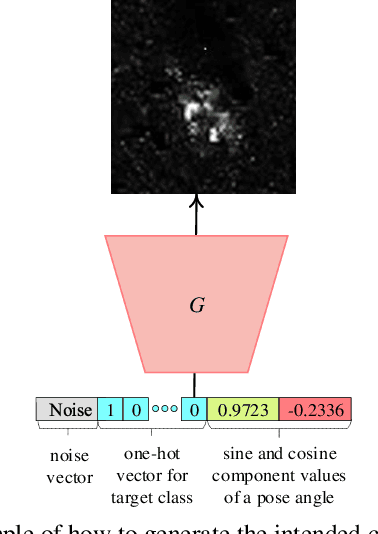
Although Generative Adversarial Networks (GANs) are successfully applied to diverse fields, training GANs on synthetic aperture radar (SAR) data is a challenging task mostly due to speckle noise. On the one hands, in a learning perspective of human's perception, it is natural to learn a task by using various information from multiple sources. However, in the previous GAN works on SAR target image generation, the information on target classes has only been used. Due to the backscattering characteristics of SAR image signals, the shapes and structures of SAR target images are strongly dependent on their pose angles. Nevertheless, the pose angle information has not been incorporated into such generative models for SAR target images. In this paper, we firstly propose a novel GAN-based multi-task learning (MTL) method for SAR target image generation, called PeaceGAN that uses both pose angle and target class information, which makes it possible to produce SAR target images of desired target classes at intended pose angles. For this, the PeaceGAN has two additional structures, a pose estimator and an auxiliary classifier, at the side of its discriminator to combine the pose and class information more efficiently. In addition, the PeaceGAN is jointly learned in an end-to-end manner as MTL with both pose angle and target class information, thus enhancing the diversity and quality of generated SAR target images The extensive experiments show that taking an advantage of both pose angle and target class learning by the proposed pose estimator and auxiliary classifier can help the PeaceGAN's generator effectively learn the distributions of SAR target images in the MTL framework, so that it can better generate the SAR target images more flexibly and faithfully at intended pose angles for desired target classes compared to the recent state-of-the-art methods.
Combining Reward and Rank Signals for Slate Recommendation
Jul 29, 2021


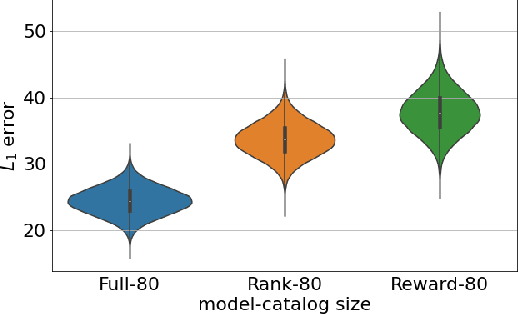
We consider the problem of slate recommendation, where the recommender system presents a user with a collection or slate composed of K recommended items at once. If the user finds the recommended items appealing then the user may click and the recommender system receives some feedback. Two pieces of information are available to the recommender system: was the slate clicked? (the reward), and if the slate was clicked, which item was clicked? (rank). In this paper, we formulate several Bayesian models that incorporate the reward signal (Reward model), the rank signal (Rank model), or both (Full model), for non-personalized slate recommendation. In our experiments, we analyze performance gains of the Full model and show that it achieves significantly lower error as the number of products in the catalog grows or as the slate size increases.
Topic, Sentiment and Impact Analysis: COVID19 Information Seeking on Social Media
Aug 28, 2020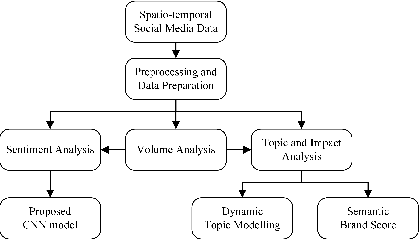
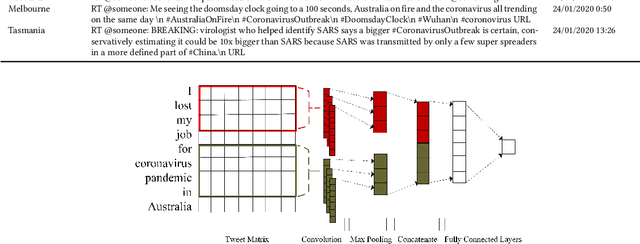
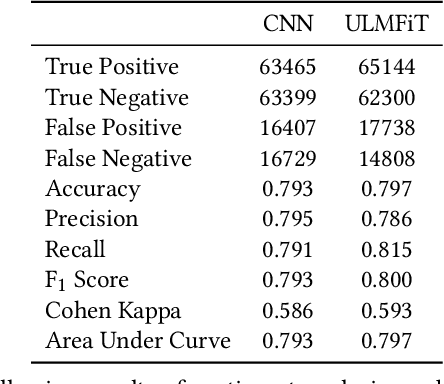

When people notice something unusual, they discuss it on social media. They leave traces of their emotions via text expressions. A systematic collection, analysis, and interpretation of social media data across time and space can give insights on local outbreaks, mental health, and social issues. Such timely insights can help in developing strategies and resources with an appropriate and efficient response. This study analysed a large Spatio-temporal tweet dataset of the Australian sphere related to COVID19. The methodology included a volume analysis, dynamic topic modelling, sentiment detection, and semantic brand score to obtain an insight on the COVID19 pandemic outbreak and public discussion in different states and cities of Australia over time. The obtained insights are compared with independently observed phenomena such as government reported instances.
Premise-based Multimodal Reasoning: A Human-like Cognitive Process
May 15, 2021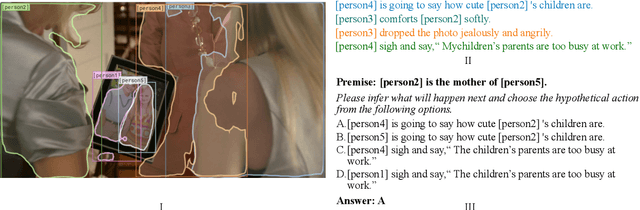
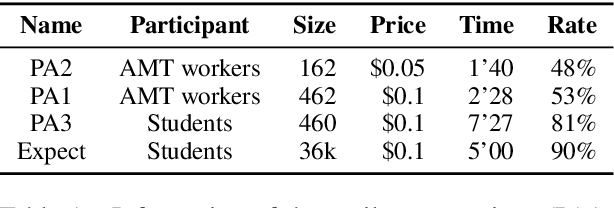
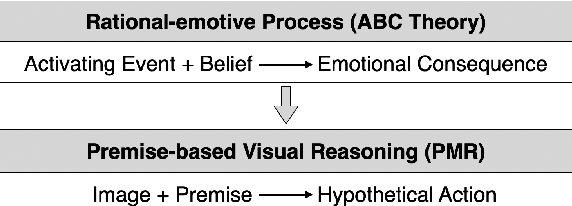

Reasoning is one of the major challenges of Human-like AI and has recently attracted intensive attention from natural language processing (NLP) researchers. However, cross-modal reasoning needs further research. For cross-modal reasoning, we observe that most methods fall into shallow feature matching without in-depth human-like reasoning.The reason lies in that existing cross-modal tasks directly ask questions for a image. However, human reasoning in real scenes is often made under specific background information, a process that is studied by the ABC theory in social psychology. We propose a shared task named "Premise-based Multimodal Reasoning" (PMR), which requires participating models to reason after establishing a profound understanding of background information. We believe that the proposed PMR would contribute to and help shed a light on human-like in-depth reasoning.