 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Learning to Reason Works Because It Is More Pessimistic Than You Think
May 27, 2026Large scale reinforcement learning has become a central tool for improving reasoning in large language models. At this scale, generation is often lagged or asynchronous, so updates are performed on data collected by older policies. This makes learning inherently off-policy. Most existing approaches nevertheless remain rooted in PPO-style trust-region objectives, treating training as approximately on-policy and using importance weights to correct distribution mismatch. These corrections can introduce high variance, destabilize optimization, and accelerate entropy collapse. Recent work suggests an alternative: rather than correcting the mismatch, one can embrace off-policy data and remove importance weights, often yielding stronger algorithms. In this paper, we provide an intuitive construction of off-policy objectives that include successful off-policy objectives and show that their effectiveness can be understood through implicit pessimism: they optimize toward target policies that are more conservative than their nominal objectives suggest. This perspective explains why some particular implementation choices improve stability: they implicitly control the effective target distribution. We then propose a principled modification that stabilize this induced distribution and improve off-policy learning.
Off-Policy Learning in Large Action Spaces: Optimization Matters More Than Estimation
Sep 03, 2025


Off-policy evaluation (OPE) and off-policy learning (OPL) are foundational for decision-making in offline contextual bandits. Recent advances in OPL primarily optimize OPE estimators with improved statistical properties, assuming that better estimators inherently yield superior policies. Although theoretically justified, we argue this estimator-centric approach neglects a critical practical obstacle: challenging optimization landscapes. In this paper, we provide theoretical insights and extensive empirical evidence showing that current OPL methods encounter severe optimization issues, particularly as action spaces become large. We demonstrate that simpler weighted log-likelihood objectives enjoy substantially better optimization properties and still recover competitive, often superior, learned policies. Our findings emphasize the necessity of explicitly addressing optimization considerations in the development of OPL algorithms for large action spaces.
Unified PAC-Bayesian Study of Pessimism for Offline Policy Learning with Regularized Importance Sampling
Jun 05, 2024



Off-policy learning (OPL) often involves minimizing a risk estimator based on importance weighting to correct bias from the logging policy used to collect data. However, this method can produce an estimator with a high variance. A common solution is to regularize the importance weights and learn the policy by minimizing an estimator with penalties derived from generalization bounds specific to the estimator. This approach, known as pessimism, has gained recent attention but lacks a unified framework for analysis. To address this gap, we introduce a comprehensive PAC-Bayesian framework to examine pessimism with regularized importance weighting. We derive a tractable PAC-Bayesian generalization bound that universally applies to common importance weight regularizations, enabling their comparison within a single framework. Our empirical results challenge common understanding, demonstrating the effectiveness of standard IW regularization techniques.
Logarithmic Smoothing for Pessimistic Off-Policy Evaluation, Selection and Learning
May 23, 2024



This work investigates the offline formulation of the contextual bandit problem, where the goal is to leverage past interactions collected under a behavior policy to evaluate, select, and learn new, potentially better-performing, policies. Motivated by critical applications, we move beyond point estimators. Instead, we adopt the principle of pessimism where we construct upper bounds that assess a policy's worst-case performance, enabling us to confidently select and learn improved policies. Precisely, we introduce novel, fully empirical concentration bounds for a broad class of importance weighting risk estimators. These bounds are general enough to cover most existing estimators and pave the way for the development of new ones. In particular, our pursuit of the tightest bound within this class motivates a novel estimator (LS), that logarithmically smooths large importance weights. The bound for LS is provably tighter than all its competitors, and naturally results in improved policy selection and learning strategies. Extensive policy evaluation, selection, and learning experiments highlight the versatility and favorable performance of LS.
Bayesian Off-Policy Evaluation and Learning for Large Action Spaces
Feb 22, 2024



In interactive systems, actions are often correlated, presenting an opportunity for more sample-efficient off-policy evaluation (OPE) and learning (OPL) in large action spaces. We introduce a unified Bayesian framework to capture these correlations through structured and informative priors. In this framework, we propose sDM, a generic Bayesian approach designed for OPE and OPL, grounded in both algorithmic and theoretical foundations. Notably, sDM leverages action correlations without compromising computational efficiency. Moreover, inspired by online Bayesian bandits, we introduce Bayesian metrics that assess the average performance of algorithms across multiple problem instances, deviating from the conventional worst-case assessments. We analyze sDM in OPE and OPL, highlighting the benefits of leveraging action correlations. Empirical evidence showcases the strong performance of sDM.
Diffusion Models Meet Contextual Bandits with Large Action Spaces
Feb 15, 2024



Efficient exploration is a key challenge in contextual bandits due to the large size of their action space, where uninformed exploration can result in computational and statistical inefficiencies. Fortunately, the rewards of actions are often correlated and this can be leveraged to explore them efficiently. In this work, we capture such correlations using pre-trained diffusion models; upon which we design diffusion Thompson sampling (dTS). Both theoretical and algorithmic foundations are developed for dTS, and empirical evaluation also shows its favorable performance.
Prior-Dependent Allocations for Bayesian Fixed-Budget Best-Arm Identification in Structured Bandits
Feb 08, 2024



We study the problem of Bayesian fixed-budget best-arm identification (BAI) in structured bandits. We propose an algorithm that uses fixed allocations based on the prior information and the structure of the environment. We provide theoretical bounds on its performance across diverse models, including the first prior-dependent upper bounds for linear and hierarchical BAI. Our key contribution is introducing new proof methods that result in tighter bounds for multi-armed BAI compared to existing methods. We extensively compare our approach to other fixed-budget BAI methods, demonstrating its consistent and robust performance in various settings. Our work improves our understanding of Bayesian fixed-budget BAI in structured bandits and highlights the effectiveness of our approach in practical scenarios.
Exponential Smoothing for Off-Policy Learning
May 25, 2023



Off-policy learning (OPL) aims at finding improved policies from logged bandit data, often by minimizing the inverse propensity scoring (IPS) estimator of the risk. In this work, we investigate a smooth regularization for IPS, for which we derive a two-sided PAC-Bayes generalization bound. The bound is tractable, scalable, interpretable and provides learning certificates. In particular, it is also valid for standard IPS without making the assumption that the importance weights are bounded. We demonstrate the relevance of our approach and its favorable performance through a set of learning tasks. Since our bound holds for standard IPS, we are able to provide insight into when regularizing IPS is useful. Namely, we identify cases where regularization might not be needed. This goes against the belief that, in practice, clipped IPS often enjoys favorable performance than standard IPS in OPL.
Offline Evaluation of Reward-Optimizing Recommender Systems: The Case of Simulation
Sep 18, 2022Both in academic and industry-based research, online evaluation methods are seen as the golden standard for interactive applications like recommendation systems. Naturally, the reason for this is that we can directly measure utility metrics that rely on interventions, being the recommendations that are being shown to users. Nevertheless, online evaluation methods are costly for a number of reasons, and a clear need remains for reliable offline evaluation procedures. In industry, offline metrics are often used as a first-line evaluation to generate promising candidate models to evaluate online. In academic work, limited access to online systems makes offline metrics the de facto approach to validating novel methods. Two classes of offline metrics exist: proxy-based methods, and counterfactual methods. The first class is often poorly correlated with the online metrics we care about, and the latter class only provides theoretical guarantees under assumptions that cannot be fulfilled in real-world environments. Here, we make the case that simulation-based comparisons provide ways forward beyond offline metrics, and argue that they are a preferable means of evaluation.
A Scalable Probabilistic Model for Reward Optimizing Slate Recommendation
Aug 10, 2022
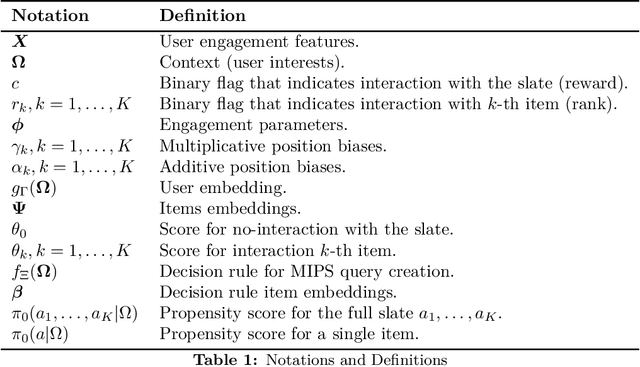
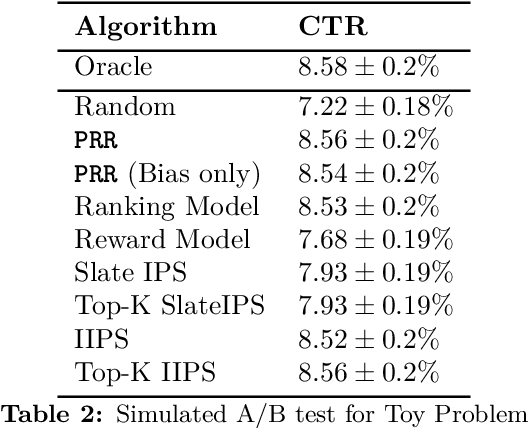
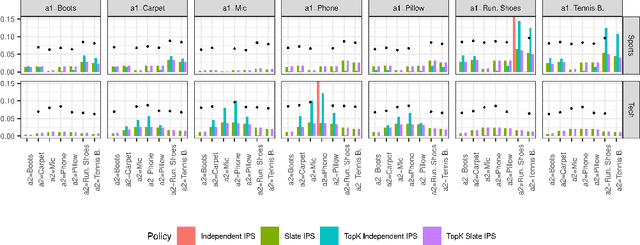
We introduce Probabilistic Rank and Reward model (PRR), a scalable probabilistic model for personalized slate recommendation. Our model allows state-of-the-art estimation of user interests in the following ubiquitous recommender system scenario: A user is shown a slate of K recommendations and the user chooses at most one of these K items. It is the goal of the recommender system to find the K items of most interest to a user in order to maximize the probability that the user interacts with the slate. Our contribution is to show that we can learn more effectively the probability of the recommendations being successful by combining the reward - whether the slate was clicked or not - and the rank - the item on the slate that was selected. Our method learns more efficiently than bandit methods that use only the reward, and user preference methods that use only the rank. It also provides similar or better estimation performance to independent inverse-propensity-score methods and is far more scalable. Our method is state of the art in terms of both speed and accuracy on massive datasets with up to 1 million items. Finally, our method allows fast delivery of recommendations powered by maximum inner product search (MIPS), making it suitable in extremely low latency domains such as computational advertising.