 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Cross-Lingual Classification Approaches Enabling Topic Discovery for Multilingual Social Media Data
Feb 19, 2026Analysing multilingual social media discourse remains a major challenge in natural language processing, particularly when large-scale public debates span across diverse languages. This study investigates how different approaches for cross-lingual text classification can support reliable analysis of global conversations. Using hydrogen energy as a case study, we analyse a decade-long dataset of over nine million tweets in English, Japanese, Hindi, and Korean (2013--2022) for topic discovery. The online keyword-driven data collection results in a significant amount of irrelevant content. We explore four approaches to filter relevant content: (1) translating English annotated data into target languages for building language-specific models for each target language, (2) translating unlabelled data appearing from all languages into English for creating a single model based on English annotations, (3) applying English fine-tuned multilingual transformers directly to each target language data, and (4) a hybrid strategy that combines translated annotations with multilingual training. Each approach is evaluated for its ability to filter hydrogen-related tweets from noisy keyword-based collections. Subsequently, topic modeling is performed to extract dominant themes within the relevant subsets. The results highlight key trade-offs between translation and multilingual approaches, offering actionable insights into optimising cross-lingual pipelines for large-scale social media analysis.
Fast Model Selection and Stable Optimization for Softmax-Gated Multinomial-Logistic Mixture of Experts Models
Feb 08, 2026Mixture-of-Experts (MoE) architectures combine specialized predictors through a learned gate and are effective across regression and classification, but for classification with softmax multinomial-logistic gating, rigorous guarantees for stable maximum-likelihood training and principled model selection remain limited. We address both issues in the full-data (batch) regime. First, we derive a batch minorization-maximization (MM) algorithm for softmax-gated multinomial-logistic MoE using an explicit quadratic minorizer, yielding coordinate-wise closed-form updates that guarantee monotone ascent of the objective and global convergence to a stationary point (in the standard MM sense), avoiding approximate M-steps common in EM-type implementations. Second, we prove finite-sample rates for conditional density estimation and parameter recovery, and we adapt dendrograms of mixing measures to the classification setting to obtain a sweep-free selector of the number of experts that achieves near-parametric optimal rates after merging redundant fitted atoms. Experiments on biological protein--protein interaction prediction validate the full pipeline, delivering improved accuracy and better-calibrated probabilities than strong statistical and machine-learning baselines.
AgentEval: Generative Agents as Reliable Proxies for Human Evaluation of AI-Generated Content
Dec 09, 2025Modern businesses are increasingly challenged by the time and expense required to generate and assess high-quality content. Human writers face time constraints, and extrinsic evaluations can be costly. While Large Language Models (LLMs) offer potential in content creation, concerns about the quality of AI-generated content persist. Traditional evaluation methods, like human surveys, further add operational costs, highlighting the need for efficient, automated solutions. This research introduces Generative Agents as a means to tackle these challenges. These agents can rapidly and cost-effectively evaluate AI-generated content, simulating human judgment by rating aspects such as coherence, interestingness, clarity, fairness, and relevance. By incorporating these agents, businesses can streamline content generation and ensure consistent, high-quality output while minimizing reliance on costly human evaluations. The study provides critical insights into enhancing LLMs for producing business-aligned, high-quality content, offering significant advancements in automated content generation and evaluation.
ALGAN: Time Series Anomaly Detection with Adjusted-LSTM GAN
Aug 13, 2023Anomaly detection in time series data, to identify points that deviate from normal behaviour, is a common problem in various domains such as manufacturing, medical imaging, and cybersecurity. Recently, Generative Adversarial Networks (GANs) are shown to be effective in detecting anomalies in time series data. The neural network architecture of GANs (i.e. Generator and Discriminator) can significantly improve anomaly detection accuracy. In this paper, we propose a new GAN model, named Adjusted-LSTM GAN (ALGAN), which adjusts the output of an LSTM network for improved anomaly detection in both univariate and multivariate time series data in an unsupervised setting. We evaluate the performance of ALGAN on 46 real-world univariate time series datasets and a large multivariate dataset that spans multiple domains. Our experiments demonstrate that ALGAN outperforms traditional, neural network-based, and other GAN-based methods for anomaly detection in time series data.
Informed Machine Learning, Centrality, CNN, Relevant Document Detection, Repatriation of Indigenous Human Remains
Mar 25, 2023Among the pressing issues facing Australian and other First Nations peoples is the repatriation of the bodily remains of their ancestors, which are currently held in Western scientific institutions. The success of securing the return of these remains to their communities for reburial depends largely on locating information within scientific and other literature published between 1790 and 1970 documenting their theft, donation, sale, or exchange between institutions. This article reports on collaborative research by data scientists and social science researchers in the Research, Reconcile, Renew Network (RRR) to develop and apply text mining techniques to identify this vital information. We describe our work to date on developing a machine learning-based solution to automate the process of finding and semantically analysing relevant texts. Classification models, particularly deep learning-based models, are known to have low accuracy when trained with small amounts of labelled (i.e. relevant/non-relevant) documents. To improve the accuracy of our detection model, we explore the use of an Informed Neural Network (INN) model that describes documentary content using expert-informed contextual knowledge. Only a few labelled documents are used to provide specificity to the model, using conceptually related keywords identified by RRR experts in provenance research. The results confirm the value of using an INN network model for identifying relevant documents related to the investigation of the global commercial trade in Indigenous human remains. Empirical analysis suggests that this INN model can be generalized for use by other researchers in the social sciences and humanities who want to extract relevant information from large textual corpora.
* Accepted Version of the Journal Article
Unsupervised Visual Time-Series Representation Learning and Clustering
Nov 19, 2021

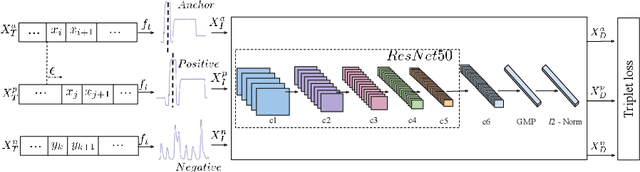

Time-series data is generated ubiquitously from Internet-of-Things (IoT) infrastructure, connected and wearable devices, remote sensing, autonomous driving research and, audio-video communications, in enormous volumes. This paper investigates the potential of unsupervised representation learning for these time-series. In this paper, we use a novel data transformation along with novel unsupervised learning regime to transfer the learning from other domains to time-series where the former have extensive models heavily trained on very large labelled datasets. We conduct extensive experiments to demonstrate the potential of the proposed approach through time-series clustering.
Nonnegative Matrix Factorization to understand Spatio-Temporal Traffic Pattern Variations during COVID-19: A Case Study
Nov 05, 2021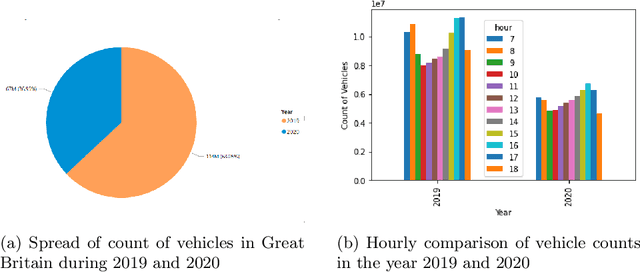
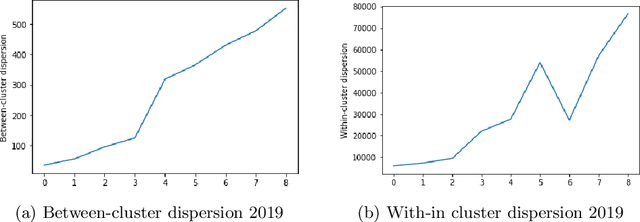
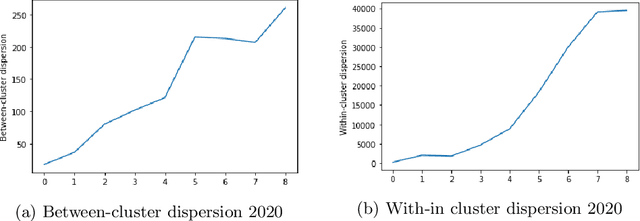
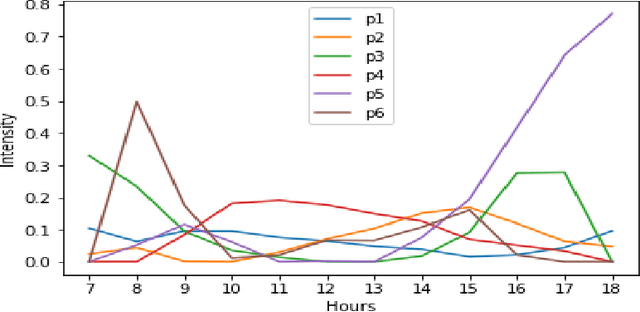
Due to the rapid developments in Intelligent Transportation System (ITS) and increasing trend in the number of vehicles on road, abundant of road traffic data is generated and available. Understanding spatio-temporal traffic patterns from this data is crucial and has been effectively helping in traffic plannings, road constructions, etc. However, understanding traffic patterns during COVID-19 pandemic is quite challenging and important as there is a huge difference in-terms of people's and vehicle's travel behavioural patterns. In this paper, a case study is conducted to understand the variations in spatio-temporal traffic patterns during COVID-19. We apply nonnegative matrix factorization (NMF) to elicit patterns. The NMF model outputs are analysed based on the spatio-temporal pattern behaviours observed during the year 2019 and 2020, which is before pandemic and during pandemic situations respectively, in Great Britain. The outputs of the analysed spatio-temporal traffic pattern variation behaviours will be useful in the fields of traffic management in Intelligent Transportation System and management in various stages of pandemic or unavoidable scenarios in-relation to road traffic.
A Semi-automatic Data Extraction System for Heterogeneous Data Sources: A Case Study from Cotton Industry
Nov 05, 2021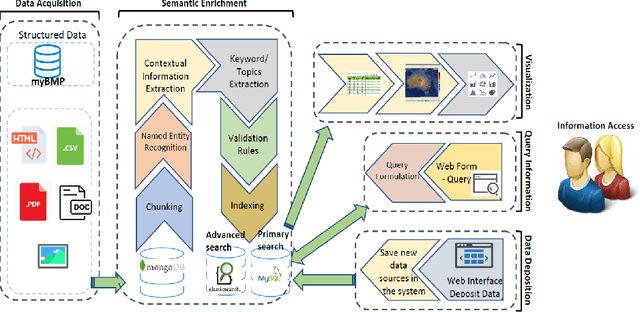
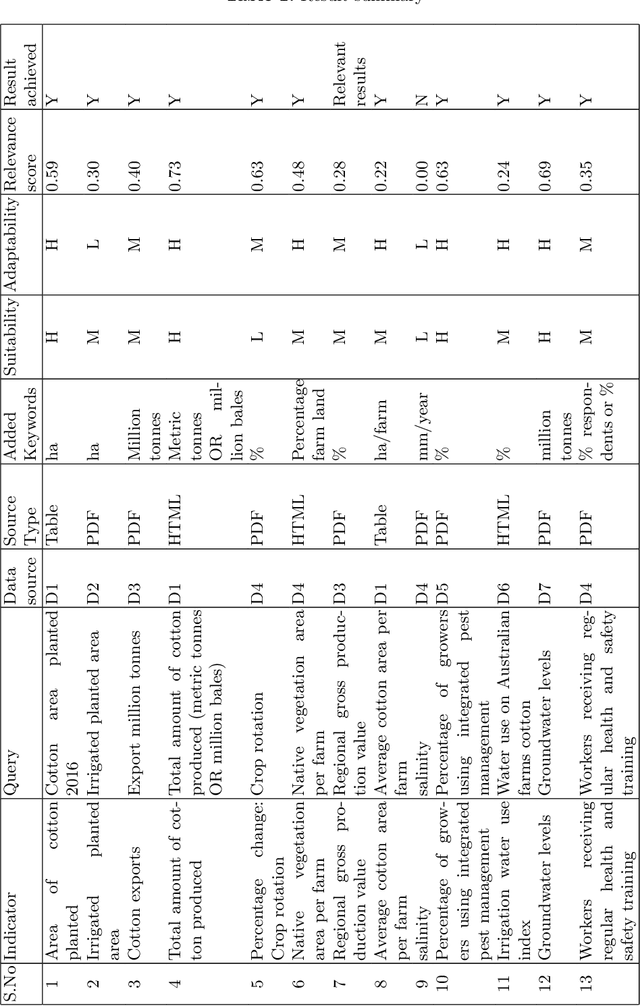

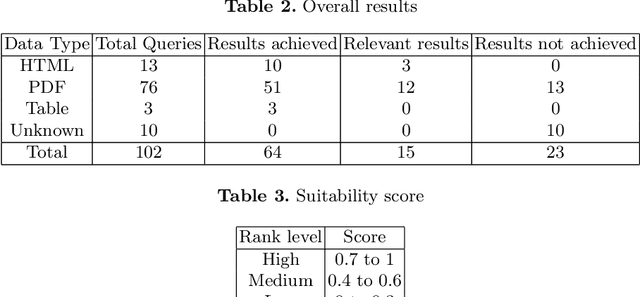
With the recent developments in digitisation, there are increasing number of documents available online. There are several information extraction tools that are available to extract information from digitised documents. However, identifying precise answers to a given query is often a challenging task especially if the data source where the relevant information resides is unknown. This situation becomes more complex when the data source is available in multiple formats such as PDF, table and html. In this paper, we propose a novel data extraction system to discover relevant and focused information from diverse unstructured data sources based on text mining approaches. We perform a qualitative analysis to evaluate the proposed system and its suitability and adaptability using cotton industry.
Investigation of Topic Modelling Methods for Understanding the Reports of the Mining Projects in Queensland
Nov 05, 2021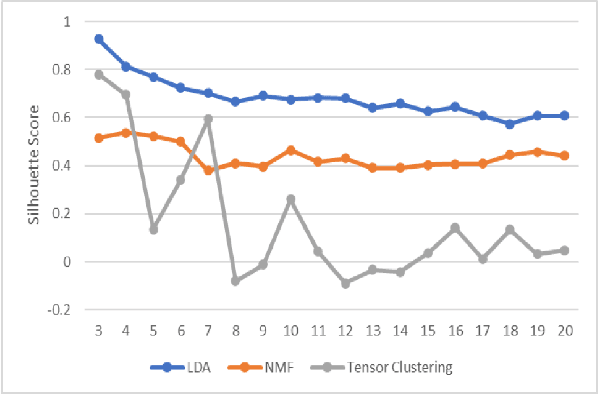
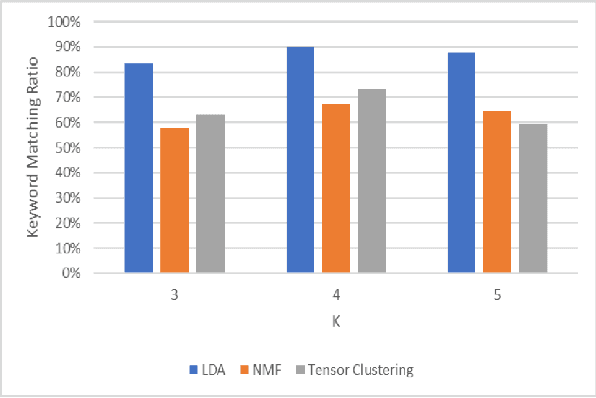
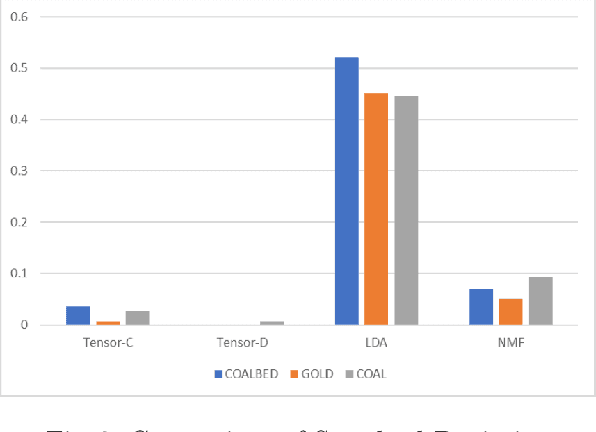
In the mining industry, many reports are generated in the project management process. These past documents are a great resource of knowledge for future success. However, it would be a tedious and challenging task to retrieve the necessary information if the documents are unorganized and unstructured. Document clustering is a powerful approach to cope with the problem, and many methods have been introduced in past studies. Nonetheless, there is no silver bullet that can perform the best for any types of documents. Thus, exploratory studies are required to apply the clustering methods for new datasets. In this study, we will investigate multiple topic modelling (TM) methods. The objectives are finding the appropriate approach for the mining project reports using the dataset of the Geological Survey of Queensland, Department of Resources, Queensland Government, and understanding the contents to get the idea of how to organise them. Three TM methods, Latent Dirichlet Allocation (LDA), Nonnegative Matrix Factorization (NMF), and Nonnegative Tensor Factorization (NTF) are compared statistically and qualitatively. After the evaluation, we conclude that the LDA performs the best for the dataset; however, the possibility remains that the other methods could be adopted with some improvements.
Deep Learning for Bias Detection: From Inception to Deployment
Oct 12, 2021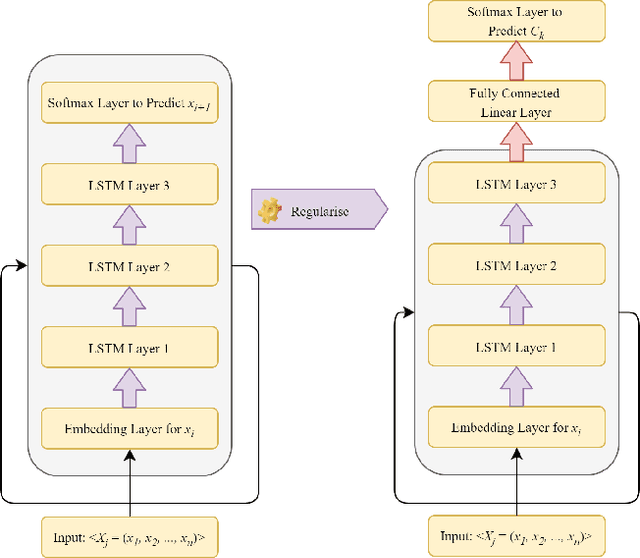

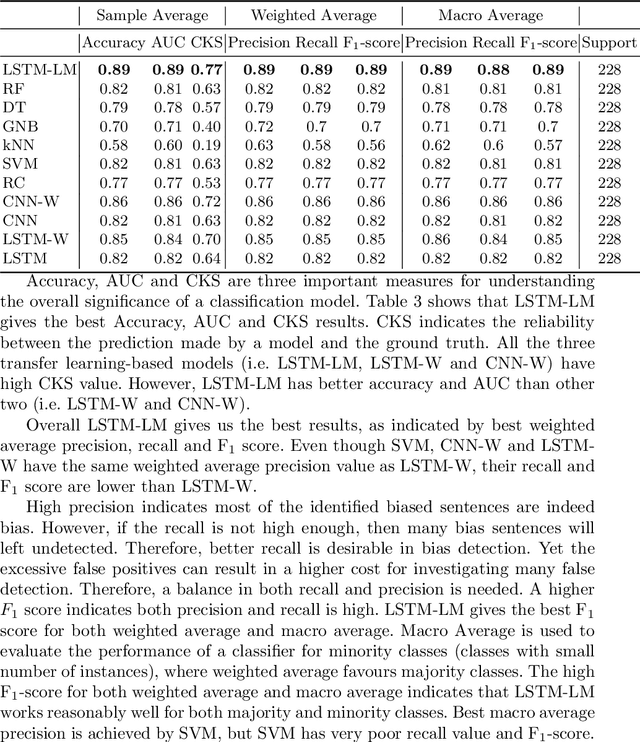
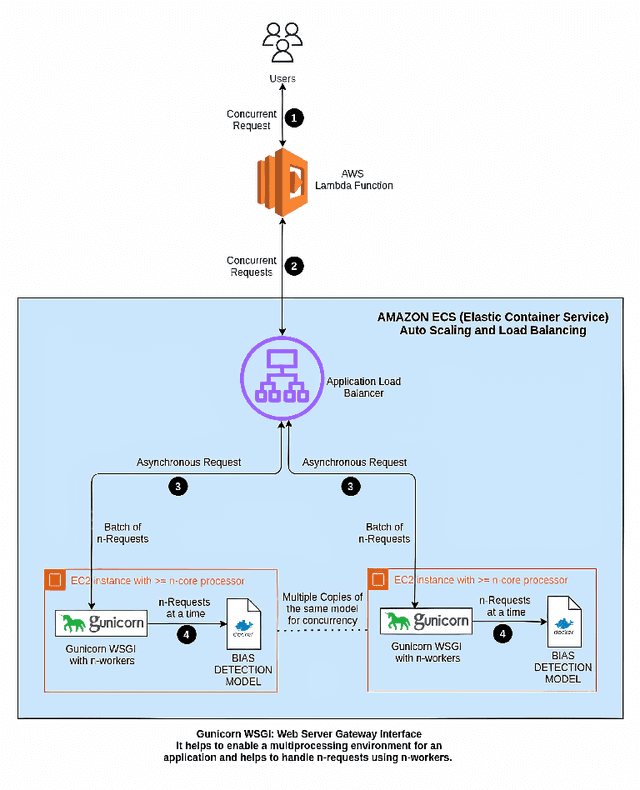
To create a more inclusive workplace, enterprises are actively investing in identifying and eliminating unconscious bias (e.g., gender, race, age, disability, elitism and religion) across their various functions. We propose a deep learning model with a transfer learning based language model to learn from manually tagged documents for automatically identifying bias in enterprise content. We first pretrain a deep learning-based language-model using Wikipedia, then fine tune the model with a large unlabelled data set related with various types of enterprise content. Finally, a linear layer followed by softmax layer is added at the end of the language model and the model is trained on a labelled bias dataset consisting of enterprise content. The trained model is thoroughly evaluated on independent datasets to ensure a general application. We present the proposed method and its deployment detail in a real-world application.