 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefGC-SR$^2$: Reference-guided Generated Content Super-Resolution and Refinement
Jun 13, 2026Reference-guided generation (e.g., object compositing, customization) has progressed rapidly, yet current pipelines share a fundamental limitation: the object-centric high-resolution reference image (HRRI) provided by users is downsampled to a fixed low-resolution (LR) before being fed into the model, so the fine-grained details are discarded before the output is even produced. In addition, the generation step then introduces its own artifacts (e.g., identity distortion) on top of this loss. Existing reference-guided generated content refinement (RefGCR) methods can correct some of these artifacts but still operate in the LR domain; reference-guided super-resolution (RefSR) methods recover resolution but assume natural-image degradations and ignore the artifact distribution of generative pipelines. To address both gaps in a single formulation, we introduce a new task: reference-guided generated content super-resolution-refinement (RefGC-SR$^2$), where the original HRRI is reused at the post-processing stage to recover lost details, refine generative artifacts, and upscale the output simultaneously. We construct the first real-world triplet data generation pipeline for this RefGC-SR$^2$ task, training a diptych-conditioned generator to synthesize paired low-quality anchors that public pretrained models cannot provide. We further present a frequency-aware diffusion transformer model for RefGC-SR$^2$ that selectively injects fine details from the HRRI while removing generative artifacts. Extensive experiments demonstrate that our RefGC-SR$^2$ model successfully (i) refines the object identity faithfully with respect to the reference, and (ii) recovers high-resolution details, so that the final result is significantly higher quality and practically more usable compared to existing RefGCR and RefSR baselines.
Chameleon: Style-Content Disentangled Framework for Cross-Domain Object Compositing
May 31, 2026Image compositing aims to seamlessly insert a foreground object into a background image, and recent advances in diffusion models have significantly enhanced the quality, especially when the foreground and background images come from the same domain (e.g., natural images). However, cross-domain compositing, where the foreground and background come from different domains, is relatively underexplored and remains challenging because the model must preserve the foreground object's identity while stylizing it to match the background domain. Existing cross-domain compositing approaches largely rely on training-free blending and refinement strategies. This is partly due to the lack of large-scale paired datasets for cross-domain compositing, limiting the development of training-based solutions. As a result, they are limited to tone-level alignment and often produce style-inconsistent or overstylized results. To overcome such limitations, we construct ChameleonDataset, the first large-scale training dataset for cross-domain compositing, with a comprehensive evaluation benchmark, built through a scalable data construction pipeline. Building on this, we propose Chameleon, a novel two-stage training-based cross-domain compositing framework. In the first stage, we propose Joint Hard Contrastive Learning (JHCL) to train ChameleonEncoder, which effectively disentangles style and content representations. In the second stage, we introduce Spatio-Temporal Attention Gating (STAG) into a diffusion transformer for effective stylization, adaptively regulating how style tokens from the first-stage encoder are injected across spatial and temporal dimensions. Our method outperforms state-of-the-art in-domain and cross-domain compositing models, sequential pipelines and commercial models, achieving improvements in both compositional plausibility and stylistic fidelity.
DiTTo: Scalable Order-aware All-in-One Image Restoration Agent
May 29, 2026Real-world images rarely suffer from a single degradation, and the order in which degradations are removed substantially affects the final restoration quality, motivating agent-based image restoration (IR), where a vision-language model schedules a pool of pre-built restoration-experts. However, existing training-based agents require $\mathcal{O}((N^{\mathbf{D}})^{2})$ restoration-expert calls per image to construct the Optimal Restoration-action Trajectory Dataset (ORTD), where $N^{\mathbf{D}}$ denotes the number of degradation types in the universe $\mathbf{D}$, and couple agent training to a fixed restoration-expert pool, preventing extension to newly introduced restoration-experts without full retraining. To overcome these efficiency and extensibility bottlenecks, we propose \textbf{DiTTo}, a novel order-aware image restoration agent framework consisting of the DiTTo Simulator and the DiTTo Agent. The DiTTo Simulator combines $\cup$S-IR for single-step restoration-action simulation and AiO-IQA for per-action quality prediction, reducing ORTD construction to $\mathcal{O}(N^{\mathbf{D}})$ simulator calls per image; the DiTTo Agent is trained by SFT on the simulator-generated ORTD, followed by \textbf{Order-aware Restoration Alignment (ORA)} that aligns degradation identification, restoration-action-ordering, and output format along independent axes. This enables \textbf{plug-and-play scalable extensibility}: adding a new restoration-expert requires updating only the lightweight ORA stage. On the MiO-100 evaluation set with up to five concurrent degradations, our DiTTo Agent achieves state-of-the-art multi-degradation restoration quality among previous agent-based IR methods.
MotionGrounder: Grounded Multi-Object Motion Transfer via Diffusion Transformer
Apr 01, 2026Motion transfer enables controllable video generation by transferring temporal dynamics from a reference video to synthesize a new video conditioned on a target caption. However, existing Diffusion Transformer (DiT)-based methods are limited to single-object videos, restricting fine-grained control in real-world scenes with multiple objects. In this work, we introduce MotionGrounder, a DiT-based framework that firstly handles motion transfer with multi-object controllability. Our Flow-based Motion Signal (FMS) in MotionGrounder provides a stable motion prior for target video generation, while our Object-Caption Alignment Loss (OCAL) grounds object captions to their corresponding spatial regions. We further propose a new Object Grounding Score (OGS), which jointly evaluates (i) spatial alignment between source video objects and their generated counterparts and (ii) semantic consistency between each generated object and its target caption. Our experiments show that MotionGrounder consistently outperforms recent baselines across quantitative, qualitative, and human evaluations.
EcoSplat: Efficiency-controllable Feed-forward 3D Gaussian Splatting from Multi-view Images
Dec 21, 2025Feed-forward 3D Gaussian Splatting (3DGS) enables efficient one-pass scene reconstruction, providing 3D representations for novel view synthesis without per-scene optimization. However, existing methods typically predict pixel-aligned primitives per-view, producing an excessive number of primitives in dense-view settings and offering no explicit control over the number of predicted Gaussians. To address this, we propose EcoSplat, the first efficiency-controllable feed-forward 3DGS framework that adaptively predicts the 3D representation for any given target primitive count at inference time. EcoSplat adopts a two-stage optimization process. The first stage is Pixel-aligned Gaussian Training (PGT) where our model learns initial primitive prediction. The second stage is Importance-aware Gaussian Finetuning (IGF) stage where our model learns rank primitives and adaptively adjust their parameters based on the target primitive count. Extensive experiments across multiple dense-view settings show that EcoSplat is robust and outperforms state-of-the-art methods under strict primitive-count constraints, making it well-suited for flexible downstream rendering tasks.
MoRel: Long-Range Flicker-Free 4D Motion Modeling via Anchor Relay-based Bidirectional Blending with Hierarchical Densification
Dec 10, 2025



Recent advances in 4D Gaussian Splatting (4DGS) have extended the high-speed rendering capability of 3D Gaussian Splatting (3DGS) into the temporal domain, enabling real-time rendering of dynamic scenes. However, one of the major remaining challenges lies in modeling long-range motion-contained dynamic videos, where a naive extension of existing methods leads to severe memory explosion, temporal flickering, and failure to handle appearing or disappearing occlusions over time. To address these challenges, we propose a novel 4DGS framework characterized by an Anchor Relay-based Bidirectional Blending (ARBB) mechanism, named MoRel, which enables temporally consistent and memory-efficient modeling of long-range dynamic scenes. Our method progressively constructs locally canonical anchor spaces at key-frame time index and models inter-frame deformations at the anchor level, enhancing temporal coherence. By learning bidirectional deformations between KfA and adaptively blending them through learnable opacity control, our approach mitigates temporal discontinuities and flickering artifacts. We further introduce a Feature-variance-guided Hierarchical Densification (FHD) scheme that effectively densifies KfA's while keeping rendering quality, based on an assigned level of feature-variance. To effectively evaluate our model's capability to handle real-world long-range 4D motion, we newly compose long-range 4D motion-contained dataset, called SelfCap$_{\text{LR}}$. It has larger average dynamic motion magnitude, captured at spatially wider spaces, compared to previous dynamic video datasets. Overall, our MoRel achieves temporally coherent and flicker-free long-range 4D reconstruction while maintaining bounded memory usage, demonstrating both scalability and efficiency in dynamic Gaussian-based representations.
SUCCESS-GS: Survey of Compactness and Compression for Efficient Static and Dynamic Gaussian Splatting
Dec 08, 2025



3D Gaussian Splatting (3DGS) has emerged as a powerful explicit representation enabling real-time, high-fidelity 3D reconstruction and novel view synthesis. However, its practical use is hindered by the massive memory and computational demands required to store and render millions of Gaussians. These challenges become even more severe in 4D dynamic scenes. To address these issues, the field of Efficient Gaussian Splatting has rapidly evolved, proposing methods that reduce redundancy while preserving reconstruction quality. This survey provides the first unified overview of efficient 3D and 4D Gaussian Splatting techniques. For both 3D and 4D settings, we systematically categorize existing methods into two major directions, Parameter Compression and Restructuring Compression, and comprehensively summarize the core ideas and methodological trends within each category. We further cover widely used datasets, evaluation metrics, and representative benchmark comparisons. Finally, we discuss current limitations and outline promising research directions toward scalable, compact, and real-time Gaussian Splatting for both static and dynamic 3D scene representation.
Leveraging Prior Knowledge of Diffusion Model for Person Search
Oct 02, 2025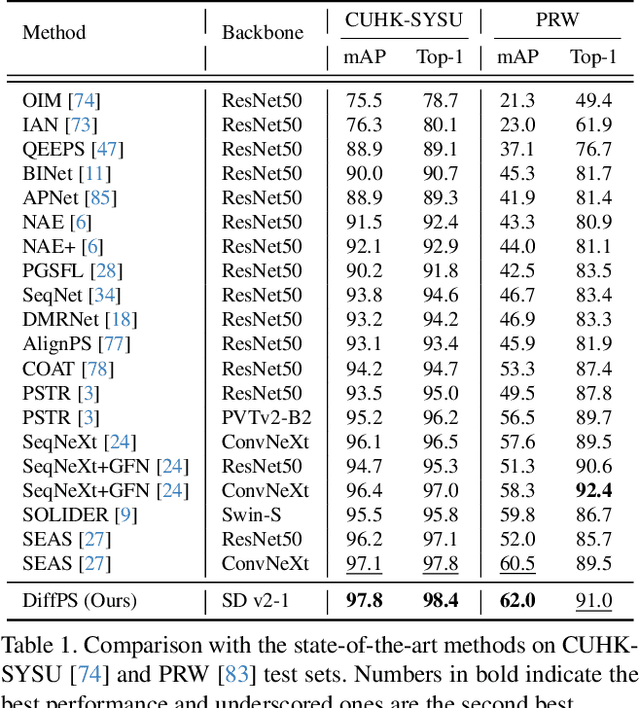
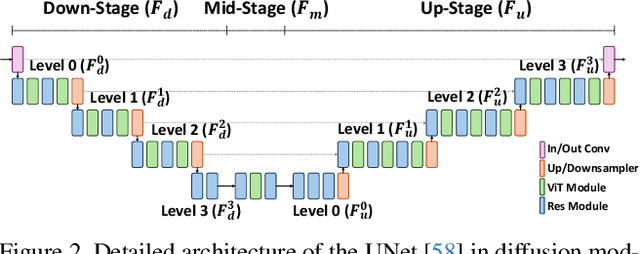
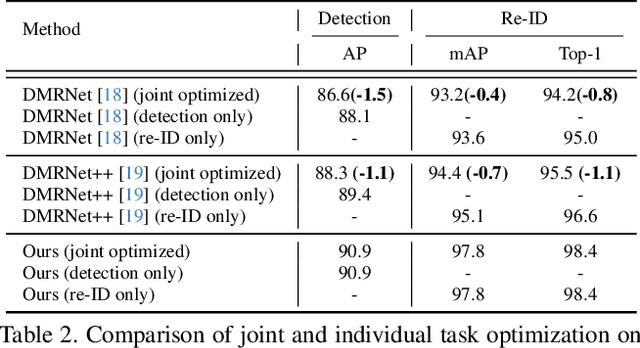

Person search aims to jointly perform person detection and re-identification by localizing and identifying a query person within a gallery of uncropped scene images. Existing methods predominantly utilize ImageNet pre-trained backbones, which may be suboptimal for capturing the complex spatial context and fine-grained identity cues necessary for person search. Moreover, they rely on a shared backbone feature for both person detection and re-identification, leading to suboptimal features due to conflicting optimization objectives. In this paper, we propose DiffPS (Diffusion Prior Knowledge for Person Search), a novel framework that leverages a pre-trained diffusion model while eliminating the optimization conflict between two sub-tasks. We analyze key properties of diffusion priors and propose three specialized modules: (i) Diffusion-Guided Region Proposal Network (DGRPN) for enhanced person localization, (ii) Multi-Scale Frequency Refinement Network (MSFRN) to mitigate shape bias, and (iii) Semantic-Adaptive Feature Aggregation Network (SFAN) to leverage text-aligned diffusion features. DiffPS sets a new state-of-the-art on CUHK-SYSU and PRW.
MoCHA-former: Moiré-Conditioned Hybrid Adaptive Transformer for Video Demoiréing
Aug 21, 2025Recent advances in portable imaging have made camera-based screen capture ubiquitous. Unfortunately, frequency aliasing between the camera's color filter array (CFA) and the display's sub-pixels induces moir\'e patterns that severely degrade captured photos and videos. Although various demoir\'eing models have been proposed to remove such moir\'e patterns, these approaches still suffer from several limitations: (i) spatially varying artifact strength within a frame, (ii) large-scale and globally spreading structures, (iii) channel-dependent statistics and (iv) rapid temporal fluctuations across frames. We address these issues with the Moir\'e Conditioned Hybrid Adaptive Transformer (MoCHA-former), which comprises two key components: Decoupled Moir\'e Adaptive Demoir\'eing (DMAD) and Spatio-Temporal Adaptive Demoir\'eing (STAD). DMAD separates moir\'e and content via a Moir\'e Decoupling Block (MDB) and a Detail Decoupling Block (DDB), then produces moir\'e-adaptive features using a Moir\'e Conditioning Block (MCB) for targeted restoration. STAD introduces a Spatial Fusion Block (SFB) with window attention to capture large-scale structures, and a Feature Channel Attention (FCA) to model channel dependence in RAW frames. To ensure temporal consistency, MoCHA-former performs implicit frame alignment without any explicit alignment module. We analyze moir\'e characteristics through qualitative and quantitative studies, and evaluate on two video datasets covering RAW and sRGB domains. MoCHA-former consistently surpasses prior methods across PSNR, SSIM, and LPIPS.
Domain Generalization for Person Re-identification: A Survey Towards Domain-Agnostic Person Matching
Jun 14, 2025Person Re-identification (ReID) aims to retrieve images of the same individual captured across non-overlapping camera views, making it a critical component of intelligent surveillance systems. Traditional ReID methods assume that the training and test domains share similar characteristics and primarily focus on learning discriminative features within a given domain. However, they often fail to generalize to unseen domains due to domain shifts caused by variations in viewpoint, background, and lighting conditions. To address this issue, Domain-Adaptive ReID (DA-ReID) methods have been proposed. These approaches incorporate unlabeled target domain data during training and improve performance by aligning feature distributions between source and target domains. Domain-Generalizable ReID (DG-ReID) tackles a more realistic and challenging setting by aiming to learn domain-invariant features without relying on any target domain data. Recent methods have explored various strategies to enhance generalization across diverse environments, but the field remains relatively underexplored. In this paper, we present a comprehensive survey of DG-ReID. We first review the architectural components of DG-ReID including the overall setting, commonly used backbone networks and multi-source input configurations. Then, we categorize and analyze domain generalization modules that explicitly aim to learn domain-invariant and identity-discriminative representations. To examine the broader applicability of these techniques, we further conduct a case study on a related task that also involves distribution shifts. Finally, we discuss recent trends, open challenges, and promising directions for future research in DG-ReID. To the best of our knowledge, this is the first systematic survey dedicated to DG-ReID.