 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePremise-based Multimodal Reasoning: A Human-like Cognitive Process
Paper and Code
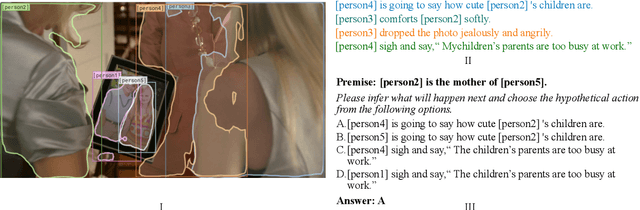
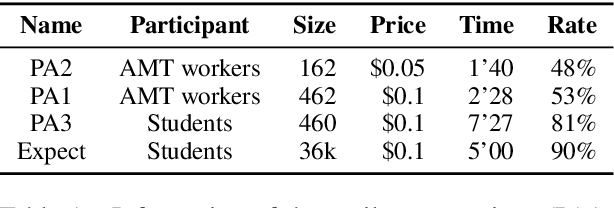
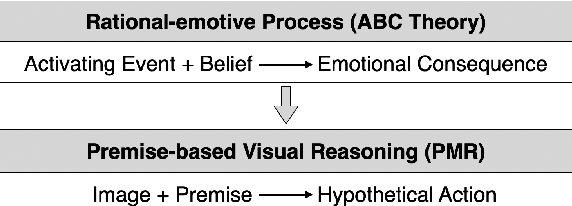

Reasoning is one of the major challenges of Human-like AI and has recently attracted intensive attention from natural language processing (NLP) researchers. However, cross-modal reasoning needs further research. For cross-modal reasoning, we observe that most methods fall into shallow feature matching without in-depth human-like reasoning.The reason lies in that existing cross-modal tasks directly ask questions for a image. However, human reasoning in real scenes is often made under specific background information, a process that is studied by the ABC theory in social psychology. We propose a shared task named "Premise-based Multimodal Reasoning" (PMR), which requires participating models to reason after establishing a profound understanding of background information. We believe that the proposed PMR would contribute to and help shed a light on human-like in-depth reasoning.