 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Cross-Lingual Classification Approaches Enabling Topic Discovery for Multilingual Social Media Data
Feb 19, 2026Analysing multilingual social media discourse remains a major challenge in natural language processing, particularly when large-scale public debates span across diverse languages. This study investigates how different approaches for cross-lingual text classification can support reliable analysis of global conversations. Using hydrogen energy as a case study, we analyse a decade-long dataset of over nine million tweets in English, Japanese, Hindi, and Korean (2013--2022) for topic discovery. The online keyword-driven data collection results in a significant amount of irrelevant content. We explore four approaches to filter relevant content: (1) translating English annotated data into target languages for building language-specific models for each target language, (2) translating unlabelled data appearing from all languages into English for creating a single model based on English annotations, (3) applying English fine-tuned multilingual transformers directly to each target language data, and (4) a hybrid strategy that combines translated annotations with multilingual training. Each approach is evaluated for its ability to filter hydrogen-related tweets from noisy keyword-based collections. Subsequently, topic modeling is performed to extract dominant themes within the relevant subsets. The results highlight key trade-offs between translation and multilingual approaches, offering actionable insights into optimising cross-lingual pipelines for large-scale social media analysis.
Fast Model Selection and Stable Optimization for Softmax-Gated Multinomial-Logistic Mixture of Experts Models
Feb 08, 2026Mixture-of-Experts (MoE) architectures combine specialized predictors through a learned gate and are effective across regression and classification, but for classification with softmax multinomial-logistic gating, rigorous guarantees for stable maximum-likelihood training and principled model selection remain limited. We address both issues in the full-data (batch) regime. First, we derive a batch minorization-maximization (MM) algorithm for softmax-gated multinomial-logistic MoE using an explicit quadratic minorizer, yielding coordinate-wise closed-form updates that guarantee monotone ascent of the objective and global convergence to a stationary point (in the standard MM sense), avoiding approximate M-steps common in EM-type implementations. Second, we prove finite-sample rates for conditional density estimation and parameter recovery, and we adapt dendrograms of mixing measures to the classification setting to obtain a sweep-free selector of the number of experts that achieves near-parametric optimal rates after merging redundant fitted atoms. Experiments on biological protein--protein interaction prediction validate the full pipeline, delivering improved accuracy and better-calibrated probabilities than strong statistical and machine-learning baselines.
ALGAN: Time Series Anomaly Detection with Adjusted-LSTM GAN
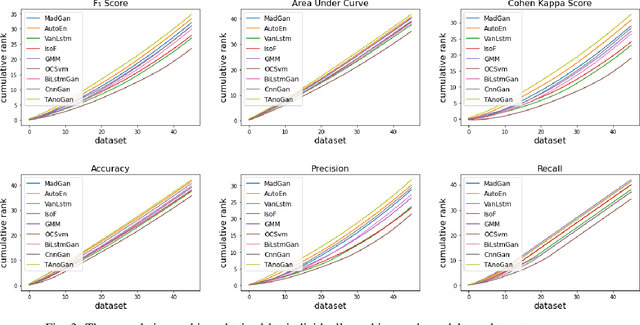
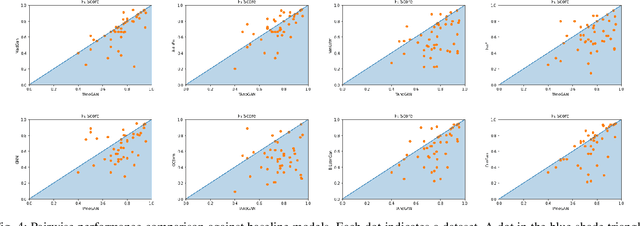
Aug 13, 2023Anomaly detection in time series data, to identify points that deviate from normal behaviour, is a common problem in various domains such as manufacturing, medical imaging, and cybersecurity. Recently, Generative Adversarial Networks (GANs) are shown to be effective in detecting anomalies in time series data. The neural network architecture of GANs (i.e. Generator and Discriminator) can significantly improve anomaly detection accuracy. In this paper, we propose a new GAN model, named Adjusted-LSTM GAN (ALGAN), which adjusts the output of an LSTM network for improved anomaly detection in both univariate and multivariate time series data in an unsupervised setting. We evaluate the performance of ALGAN on 46 real-world univariate time series datasets and a large multivariate dataset that spans multiple domains. Our experiments demonstrate that ALGAN outperforms traditional, neural network-based, and other GAN-based methods for anomaly detection in time series data.
Informed Machine Learning, Centrality, CNN, Relevant Document Detection, Repatriation of Indigenous Human Remains
Mar 25, 2023Among the pressing issues facing Australian and other First Nations peoples is the repatriation of the bodily remains of their ancestors, which are currently held in Western scientific institutions. The success of securing the return of these remains to their communities for reburial depends largely on locating information within scientific and other literature published between 1790 and 1970 documenting their theft, donation, sale, or exchange between institutions. This article reports on collaborative research by data scientists and social science researchers in the Research, Reconcile, Renew Network (RRR) to develop and apply text mining techniques to identify this vital information. We describe our work to date on developing a machine learning-based solution to automate the process of finding and semantically analysing relevant texts. Classification models, particularly deep learning-based models, are known to have low accuracy when trained with small amounts of labelled (i.e. relevant/non-relevant) documents. To improve the accuracy of our detection model, we explore the use of an Informed Neural Network (INN) model that describes documentary content using expert-informed contextual knowledge. Only a few labelled documents are used to provide specificity to the model, using conceptually related keywords identified by RRR experts in provenance research. The results confirm the value of using an INN network model for identifying relevant documents related to the investigation of the global commercial trade in Indigenous human remains. Empirical analysis suggests that this INN model can be generalized for use by other researchers in the social sciences and humanities who want to extract relevant information from large textual corpora.
* Accepted Version of the Journal Article
Deep Learning for Bias Detection: From Inception to Deployment
Oct 12, 2021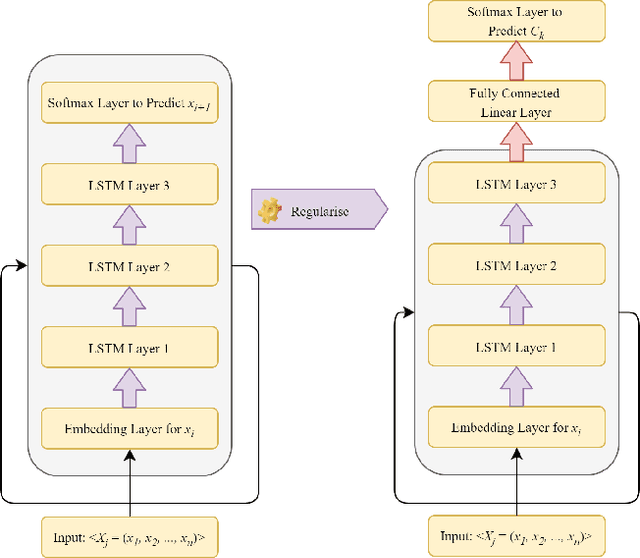

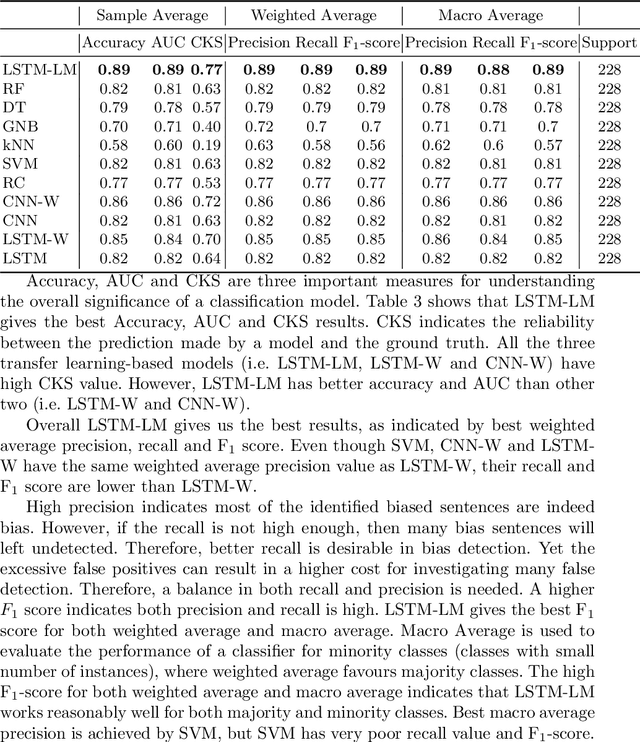
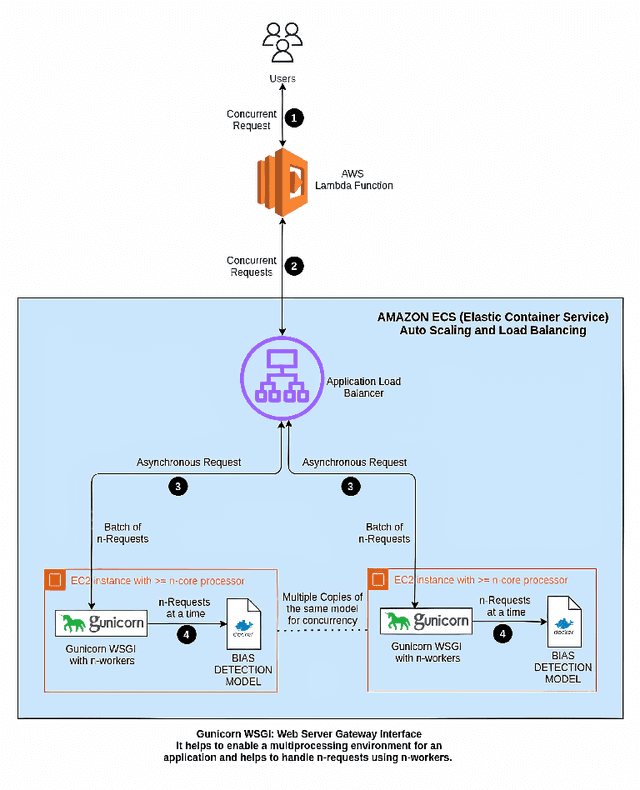
To create a more inclusive workplace, enterprises are actively investing in identifying and eliminating unconscious bias (e.g., gender, race, age, disability, elitism and religion) across their various functions. We propose a deep learning model with a transfer learning based language model to learn from manually tagged documents for automatically identifying bias in enterprise content. We first pretrain a deep learning-based language-model using Wikipedia, then fine tune the model with a large unlabelled data set related with various types of enterprise content. Finally, a linear layer followed by softmax layer is added at the end of the language model and the model is trained on a labelled bias dataset consisting of enterprise content. The trained model is thoroughly evaluated on independent datasets to ensure a general application. We present the proposed method and its deployment detail in a real-world application.
Automatic Monitoring Social Dynamics During Big Incidences: A Case Study of COVID-19 in Bangladesh
Jan 31, 2021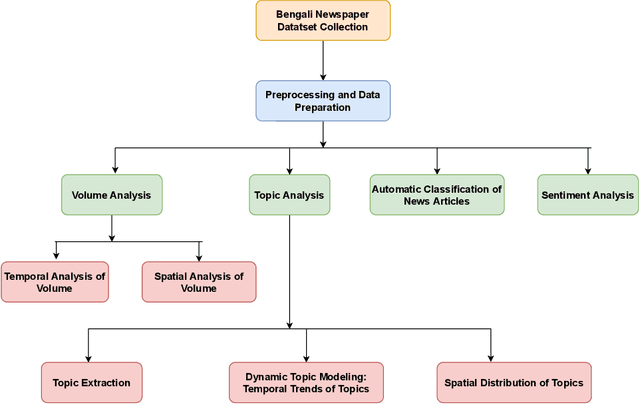
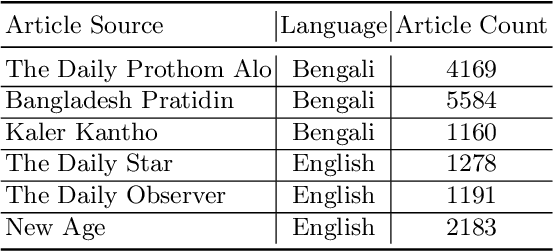
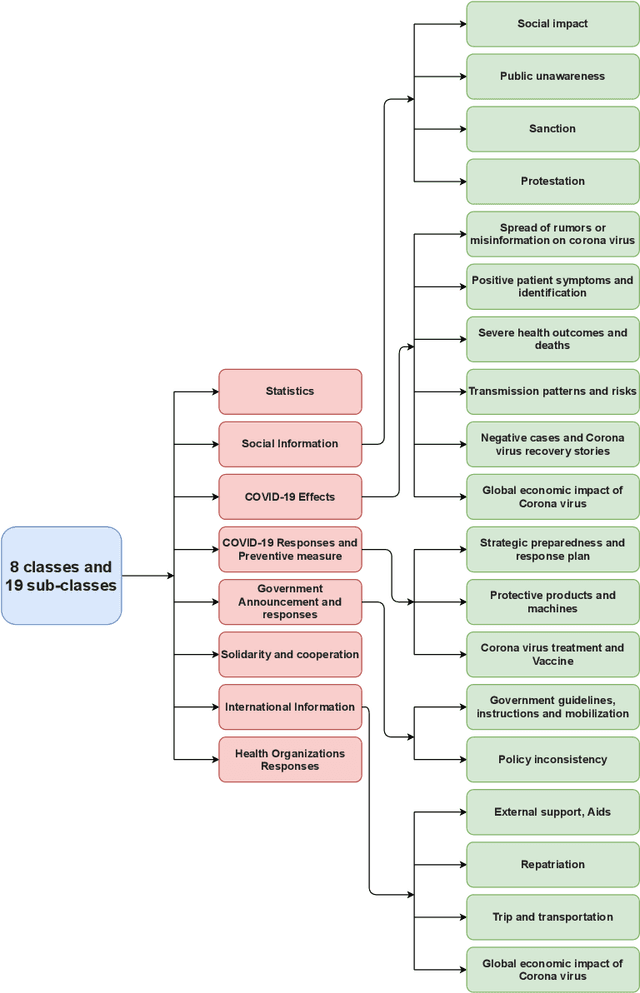
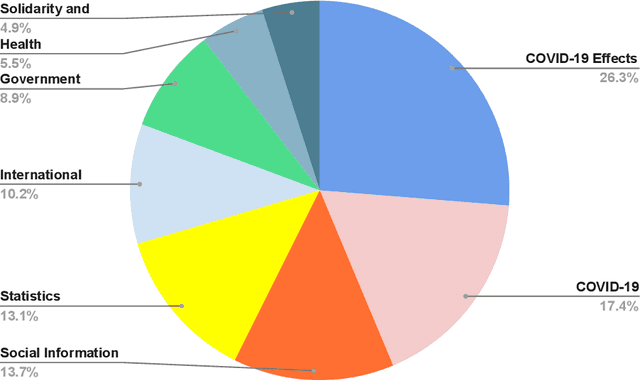
Newspapers are trustworthy media where people get the most reliable and credible information compared with other sources. On the other hand, social media often spread rumors and misleading news to get more traffic and attention. Careful characterization, evaluation, and interpretation of newspaper data can provide insight into intrigue and passionate social issues to monitor any big social incidence. This study analyzed a large set of spatio-temporal Bangladeshi newspaper data related to the COVID-19 pandemic. The methodology included volume analysis, topic analysis, automated classification, and sentiment analysis of news articles to get insight into the COVID-19 pandemic in different sectors and regions in Bangladesh over a period of time. This analysis will help the government and other organizations to figure out the challenges that have arisen in society due to this pandemic, what steps should be taken immediately and in the post-pandemic period, how the government and its allies can come together to address the crisis in the future, keeping these problems in mind.
TAnoGAN: Time Series Anomaly Detection with Generative Adversarial Networks
Sep 25, 2020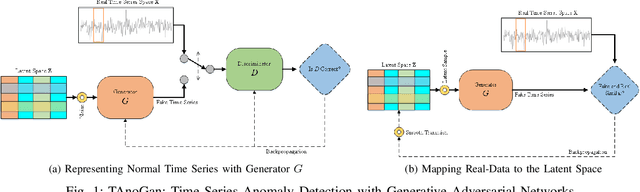
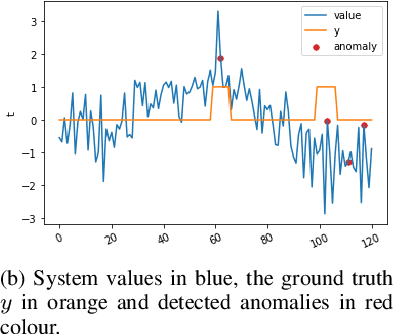
Anomaly detection in time series data is a significant problem faced in many application areas such as manufacturing, medical imaging and cyber-security. Recently, Generative Adversarial Networks (GAN) have gained attention for generation and anomaly detection in image domain. In this paper, we propose a novel GAN-based unsupervised method called TAnoGan for detecting anomalies in time series when a small number of data points are available. We evaluate TAnoGan with 46 real-world time series datasets that cover a variety of domains. Extensive experimental results show that TAnoGan performs better than traditional and neural network models.
Understanding the Spatio-temporal Topic Dynamics of Covid-19 using Nonnegative Tensor Factorization: A Case Study
Sep 19, 2020
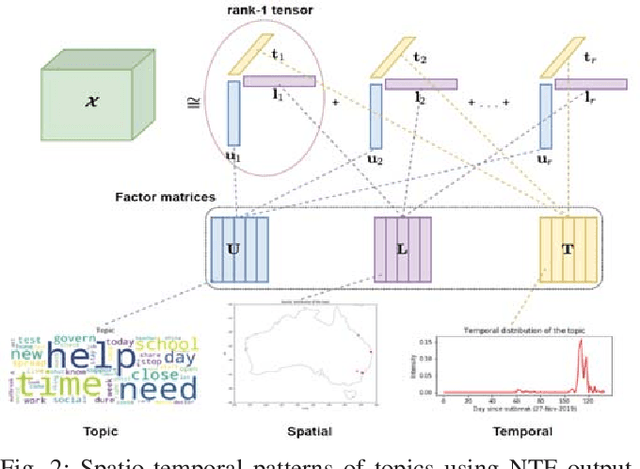
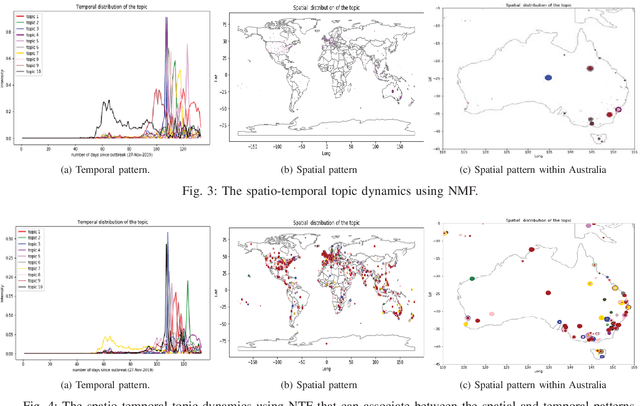
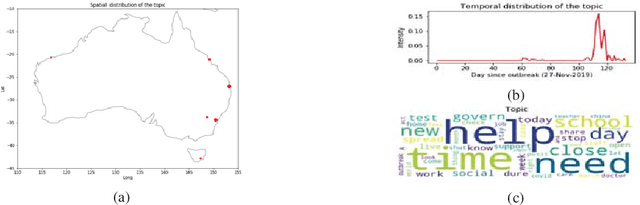
Social media platforms facilitate mankind a data-driven world by enabling billions of people to share their thoughts and activities ubiquitously. This huge collection of data, if analysed properly, can provide useful insights into people's behavior. More than ever, now is a crucial time under the Covid-19 pandemic to understand people's online behaviors detailing what topics are being discussed, and where (space) and when (time) they are discussed. Given the high complexity and poor quality of the huge social media data, an effective spatio-temporal topic detection method is needed. This paper proposes a tensor-based representation of social media data and Non-negative Tensor Factorization (NTF) to identify the topics discussed in social media data along with the spatio-temporal topic dynamics. A case study on Covid-19 related tweets from the Australia Twittersphere is presented to identify and visualize spatio-temporal topic dynamics on Covid-19
Misogynistic Tweet Detection: Modelling CNN with Small Datasets
Aug 28, 2020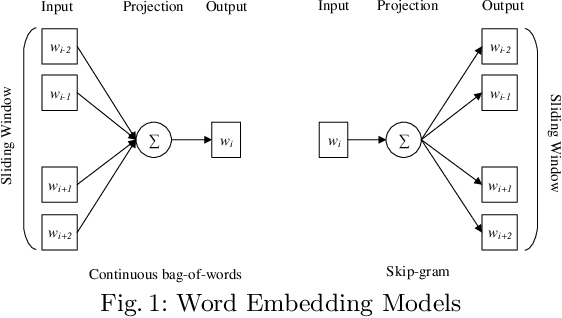
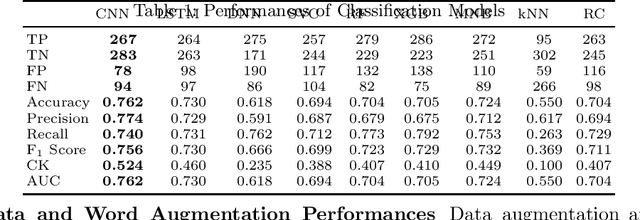
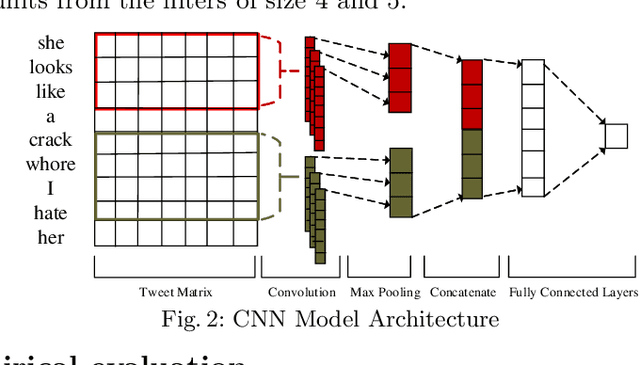
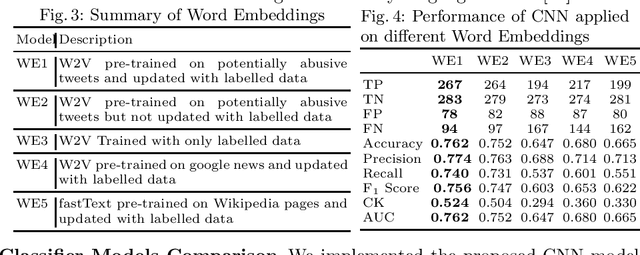
Online abuse directed towards women on the social media platform Twitter has attracted considerable attention in recent years. An automated method to effectively identify misogynistic abuse could improve our understanding of the patterns, driving factors, and effectiveness of responses associated with abusive tweets over a sustained time period. However, training a neural network (NN) model with a small set of labelled data to detect misogynistic tweets is difficult. This is partly due to the complex nature of tweets which contain misogynistic content, and the vast number of parameters needed to be learned in a NN model. We have conducted a series of experiments to investigate how to train a NN model to detect misogynistic tweets effectively. In particular, we have customised and regularised a Convolutional Neural Network (CNN) architecture and shown that the word vectors pre-trained on a task-specific domain can be used to train a CNN model effectively when a small set of labelled data is available. A CNN model trained in this way yields an improved accuracy over the state-of-the-art models.
QutNocturnal@HASOC'19: CNN for Hate Speech and Offensive Content Identification in Hindi Language
Aug 28, 2020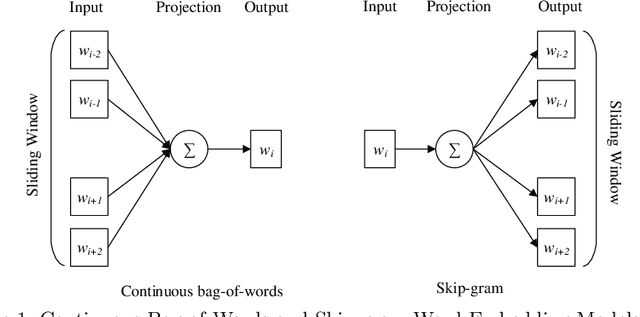
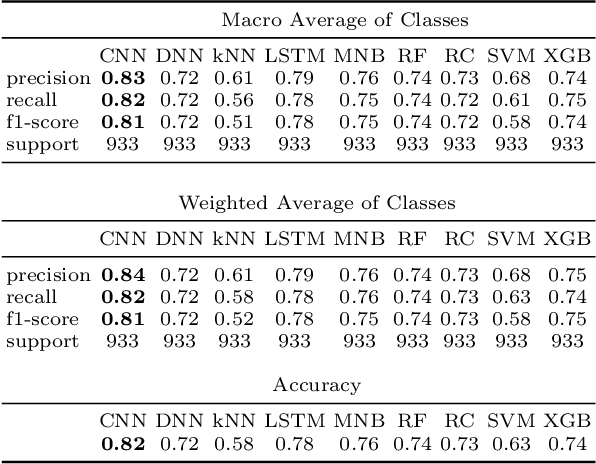
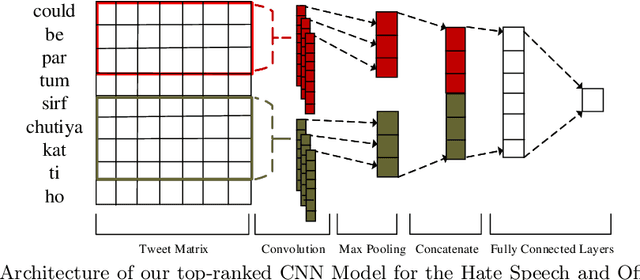
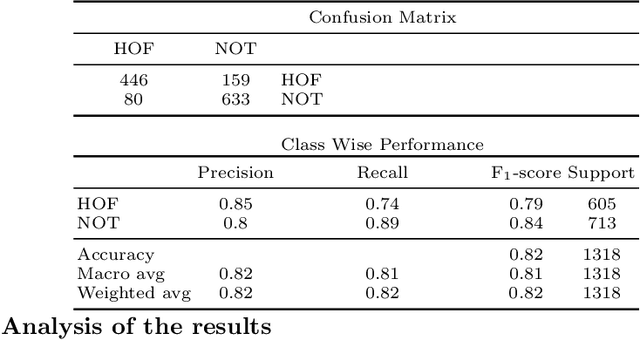
We describe our top-team solution to Task 1 for Hindi in the HASOC contest organised by FIRE 2019. The task is to identify hate speech and offensive language in Hindi. More specifically, it is a binary classification problem where a system is required to classify tweets into two classes: (a) \emph{Hate and Offensive (HOF)} and (b) \emph{Not Hate or Offensive (NOT)}. In contrast to the popular idea of pretraining word vectors (a.k.a. word embedding) with a large corpus from a general domain such as Wikipedia, we used a relatively small collection of relevant tweets (i.e. random and sarcasm tweets in Hindi and Hinglish) for pretraining. We trained a Convolutional Neural Network (CNN) on top of the pretrained word vectors. This approach allowed us to be ranked first for this task out of all teams. Our approach could easily be adapted to other applications where the goal is to predict class of a text when the provided context is limited.