 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Point Process Model for Optimizing Repeated Personalized Action Delivery to Users
Jan 06, 2025This paper provides a formalism for an important class of causal inference problems inspired by user-advertiser interaction in online advertiser. Then this formalism is specialized to an extension of temporal marked point processes and the neural point processes are suggested as practical solutions to some interesting special cases.
Unified PAC-Bayesian Study of Pessimism for Offline Policy Learning with Regularized Importance Sampling
Jun 05, 2024



Off-policy learning (OPL) often involves minimizing a risk estimator based on importance weighting to correct bias from the logging policy used to collect data. However, this method can produce an estimator with a high variance. A common solution is to regularize the importance weights and learn the policy by minimizing an estimator with penalties derived from generalization bounds specific to the estimator. This approach, known as pessimism, has gained recent attention but lacks a unified framework for analysis. To address this gap, we introduce a comprehensive PAC-Bayesian framework to examine pessimism with regularized importance weighting. We derive a tractable PAC-Bayesian generalization bound that universally applies to common importance weight regularizations, enabling their comparison within a single framework. Our empirical results challenge common understanding, demonstrating the effectiveness of standard IW regularization techniques.
Bayesian Off-Policy Evaluation and Learning for Large Action Spaces
Feb 22, 2024



In interactive systems, actions are often correlated, presenting an opportunity for more sample-efficient off-policy evaluation (OPE) and learning (OPL) in large action spaces. We introduce a unified Bayesian framework to capture these correlations through structured and informative priors. In this framework, we propose sDM, a generic Bayesian approach designed for OPE and OPL, grounded in both algorithmic and theoretical foundations. Notably, sDM leverages action correlations without compromising computational efficiency. Moreover, inspired by online Bayesian bandits, we introduce Bayesian metrics that assess the average performance of algorithms across multiple problem instances, deviating from the conventional worst-case assessments. We analyze sDM in OPE and OPL, highlighting the benefits of leveraging action correlations. Empirical evidence showcases the strong performance of sDM.
Position Paper: Why the Shooting in the Dark Method Dominates Recommender Systems Practice; A Call to Abandon Anti-Utopian Thinking
Feb 08, 2024Applied recommender systems research is in a curious position. While there is a very rigorous protocol for measuring performance by A/B testing, best practice for finding a `B' to test does not explicitly target performance but rather targets a proxy measure. The success or failure of a given A/B test then depends entirely on if the proposed proxy is better correlated to performance than the previous proxy. No principle exists to identify if one proxy is better than another offline, leaving the practitioners shooting in the dark. The purpose of this position paper is to question this anti-Utopian thinking and argue that a non-standard use of the deep learning stacks actually has the potential to unlock reward optimizing recommendation.
Fast Slate Policy Optimization: Going Beyond Plackett-Luce
Aug 03, 2023An increasingly important building block of large scale machine learning systems is based on returning slates; an ordered lists of items given a query. Applications of this technology include: search, information retrieval and recommender systems. When the action space is large, decision systems are restricted to a particular structure to complete online queries quickly. This paper addresses the optimization of these large scale decision systems given an arbitrary reward function. We cast this learning problem in a policy optimization framework and propose a new class of policies, born from a novel relaxation of decision functions. This results in a simple, yet efficient learning algorithm that scales to massive action spaces. We compare our method to the commonly adopted Plackett-Luce policy class and demonstrate the effectiveness of our approach on problems with action space sizes in the order of millions.
Exponential Smoothing for Off-Policy Learning
May 25, 2023



Off-policy learning (OPL) aims at finding improved policies from logged bandit data, often by minimizing the inverse propensity scoring (IPS) estimator of the risk. In this work, we investigate a smooth regularization for IPS, for which we derive a two-sided PAC-Bayes generalization bound. The bound is tractable, scalable, interpretable and provides learning certificates. In particular, it is also valid for standard IPS without making the assumption that the importance weights are bounded. We demonstrate the relevance of our approach and its favorable performance through a set of learning tasks. Since our bound holds for standard IPS, we are able to provide insight into when regularizing IPS is useful. Namely, we identify cases where regularization might not be needed. This goes against the belief that, in practice, clipped IPS often enjoys favorable performance than standard IPS in OPL.
Learning from aggregated data with a maximum entropy model
Oct 05, 2022
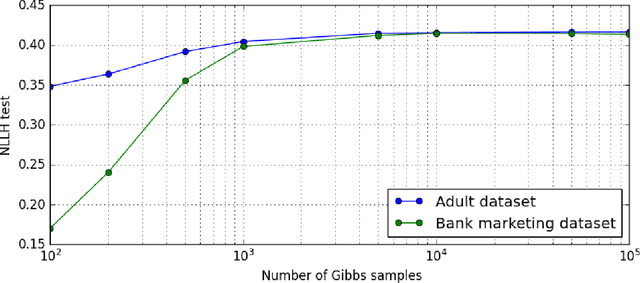
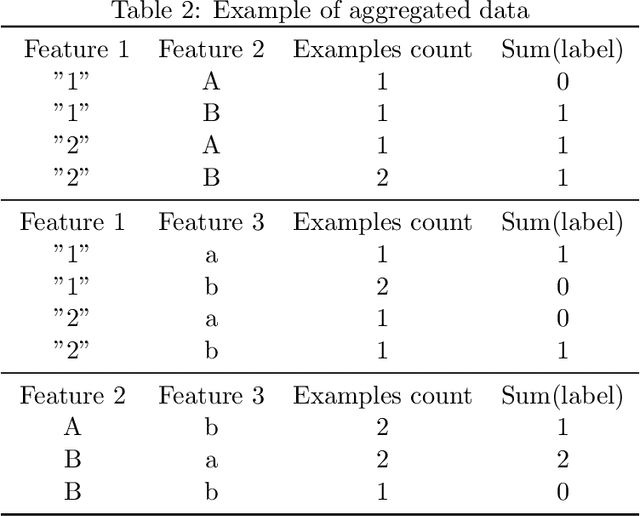
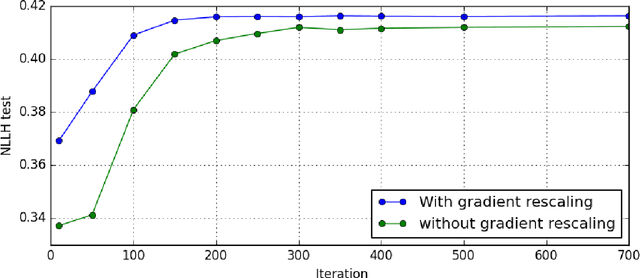
Aggregating a dataset, then injecting some noise, is a simple and common way to release differentially private data.However, aggregated data -- even without noise -- is not an appropriate input for machine learning classifiers.In this work, we show how a new model, similar to a logistic regression, may be learned from aggregated data only by approximating the unobserved feature distribution with a maximum entropy hypothesis. The resulting model is a Markov Random Field (MRF), and we detail how to apply, modify and scale a MRF training algorithm to our setting. Finally we present empirical evidence on several public datasets that the model learned this way can achieve performances comparable to those of a logistic model trained with the full unaggregated data.
Offline Evaluation of Reward-Optimizing Recommender Systems: The Case of Simulation
Sep 18, 2022Both in academic and industry-based research, online evaluation methods are seen as the golden standard for interactive applications like recommendation systems. Naturally, the reason for this is that we can directly measure utility metrics that rely on interventions, being the recommendations that are being shown to users. Nevertheless, online evaluation methods are costly for a number of reasons, and a clear need remains for reliable offline evaluation procedures. In industry, offline metrics are often used as a first-line evaluation to generate promising candidate models to evaluate online. In academic work, limited access to online systems makes offline metrics the de facto approach to validating novel methods. Two classes of offline metrics exist: proxy-based methods, and counterfactual methods. The first class is often poorly correlated with the online metrics we care about, and the latter class only provides theoretical guarantees under assumptions that cannot be fulfilled in real-world environments. Here, we make the case that simulation-based comparisons provide ways forward beyond offline metrics, and argue that they are a preferable means of evaluation.
Fast Offline Policy Optimization for Large Scale Recommendation
Aug 11, 2022
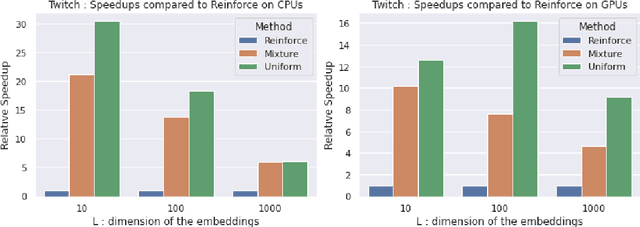
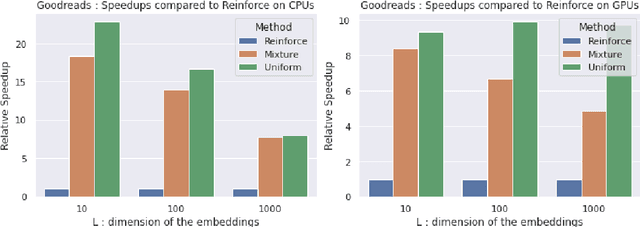
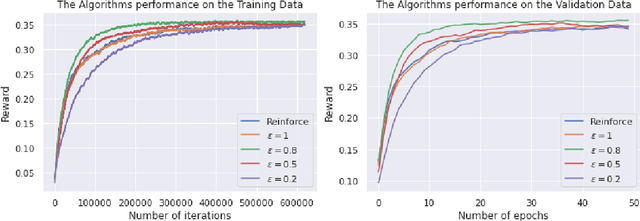
Personalised interactive systems such as recommender systems require selecting relevant items dependent on context. Production systems need to identify the items rapidly from very large catalogues which can be efficiently solved using maximum inner product search technology. Offline optimisation of maximum inner product search can be achieved by a relaxation of the discrete problem resulting in policy learning or reinforce style learning algorithms. Unfortunately this relaxation step requires computing a sum over the entire catalogue making the complexity of the evaluation of the gradient (and hence each stochastic gradient descent iterations) linear in the catalogue size. This calculation is untenable in many real world examples such as large catalogue recommender systems severely limiting the usefulness of this method in practice. In this paper we show how it is possible to produce an excellent approximation of these policy learning algorithms that scale logarithmically with the catalogue size. Our contribution is based upon combining three novel ideas: a new Monte Carlo estimate of the gradient of a policy, the self normalised importance sampling estimator and the use of fast maximum inner product search at training time. Extensive experiments show our algorithm is an order of magnitude faster than naive approaches yet produces equally good policies.
A Scalable Probabilistic Model for Reward Optimizing Slate Recommendation
Aug 10, 2022
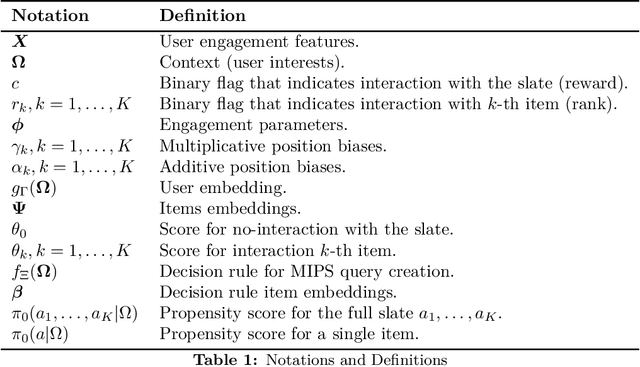
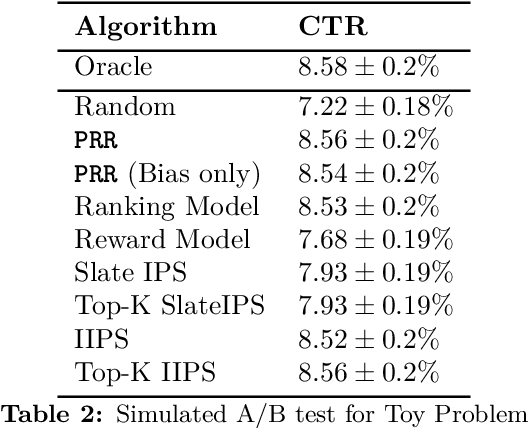
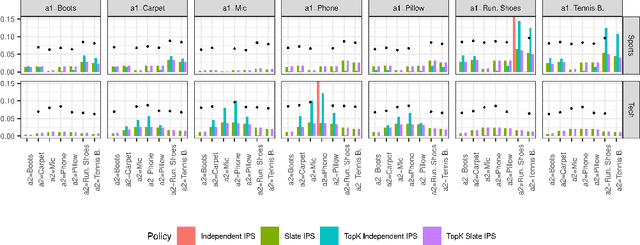
We introduce Probabilistic Rank and Reward model (PRR), a scalable probabilistic model for personalized slate recommendation. Our model allows state-of-the-art estimation of user interests in the following ubiquitous recommender system scenario: A user is shown a slate of K recommendations and the user chooses at most one of these K items. It is the goal of the recommender system to find the K items of most interest to a user in order to maximize the probability that the user interacts with the slate. Our contribution is to show that we can learn more effectively the probability of the recommendations being successful by combining the reward - whether the slate was clicked or not - and the rank - the item on the slate that was selected. Our method learns more efficiently than bandit methods that use only the reward, and user preference methods that use only the rank. It also provides similar or better estimation performance to independent inverse-propensity-score methods and is far more scalable. Our method is state of the art in terms of both speed and accuracy on massive datasets with up to 1 million items. Finally, our method allows fast delivery of recommendations powered by maximum inner product search (MIPS), making it suitable in extremely low latency domains such as computational advertising.