 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Leveraging Pre-trained Language Model for Speech Sentiment Analysis
Jun 11, 2021
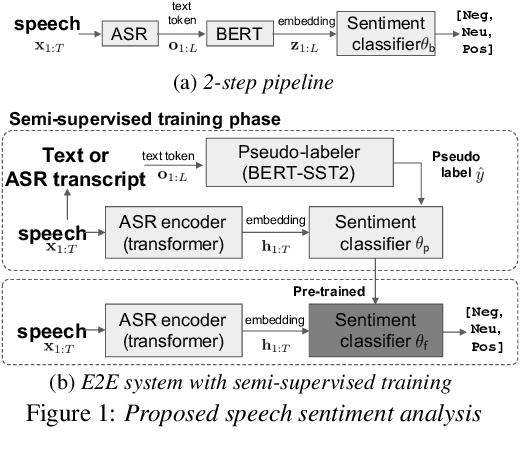
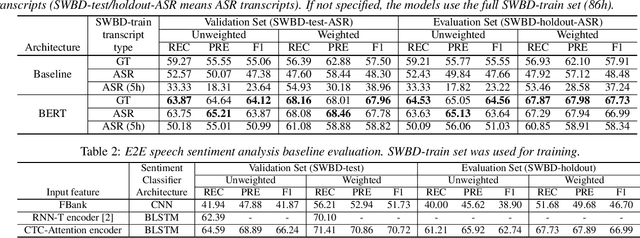
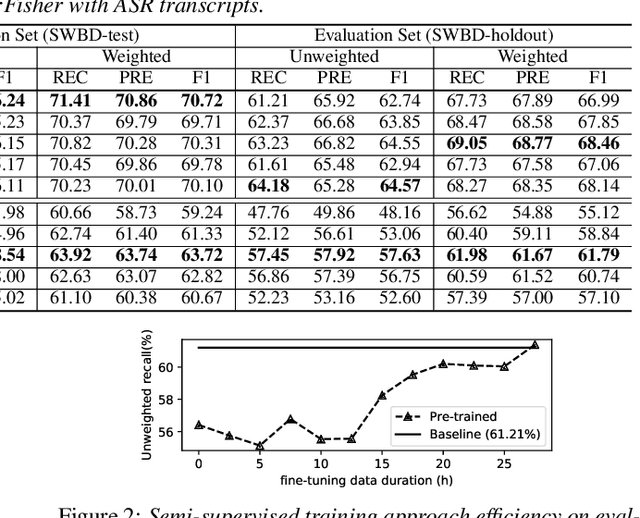
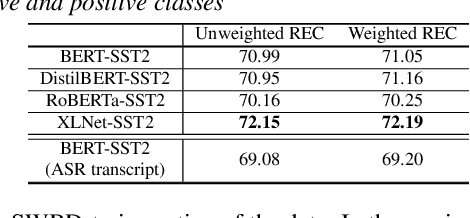
In this paper, we explore the use of pre-trained language models to learn sentiment information of written texts for speech sentiment analysis. First, we investigate how useful a pre-trained language model would be in a 2-step pipeline approach employing Automatic Speech Recognition (ASR) and transcripts-based sentiment analysis separately. Second, we propose a pseudo label-based semi-supervised training strategy using a language model on an end-to-end speech sentiment approach to take advantage of a large, but unlabeled speech dataset for training. Although spoken and written texts have different linguistic characteristics, they can complement each other in understanding sentiment. Therefore, the proposed system can not only model acoustic characteristics to bear sentiment-specific information in speech signals, but learn latent information to carry sentiments in the text representation. In these experiments, we demonstrate the proposed approaches improve F1 scores consistently compared to systems without a language model. Moreover, we also show that the proposed framework can reduce 65% of human supervision by leveraging a large amount of data without human sentiment annotation and boost performance in a low-resource condition where the human sentiment annotation is not available enough.
N15News: A New Dataset for Multimodal News Classification
Aug 30, 2021
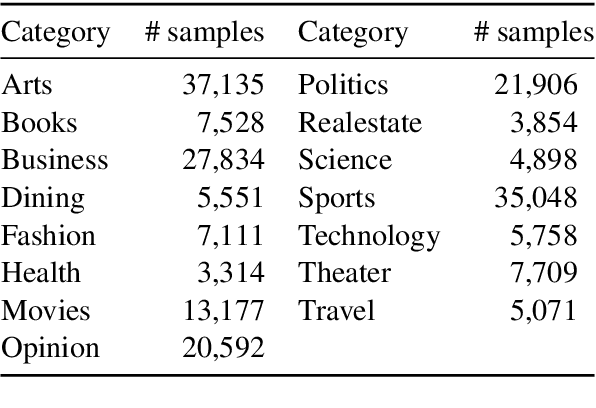
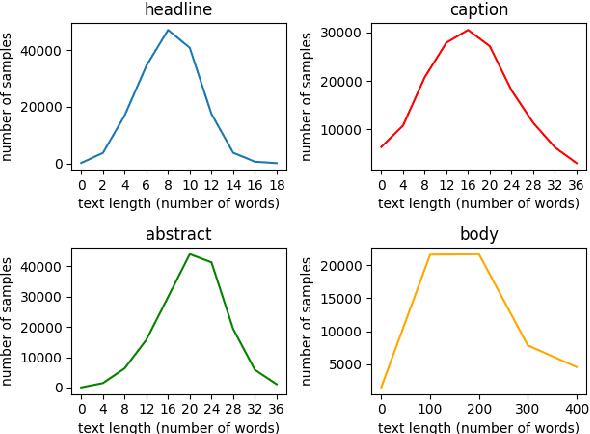

Current news datasets merely focus on text features on the news and rarely leverage the feature of images, excluding numerous essential features for news classification. In this paper, we propose a new dataset, N15News, which is generated from New York Times with 15 categories and contains both text and image information in each news. We design a novel multitask multimodal network with different fusion methods, and experiments show multimodal news classification performs better than text-only news classification. Depending on the length of the text, the classification accuracy can be increased by up to 5.8%. Our research reveals the relationship between the performance of a multimodal classifier and its sub-classifiers, and also the possible improvements when applying multimodal in news classification. N15News is shown to have great potential to prompt the multimodal news studies.
Gap-Dependent Unsupervised Exploration for Reinforcement Learning
Aug 11, 2021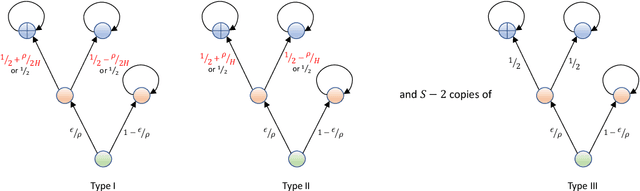
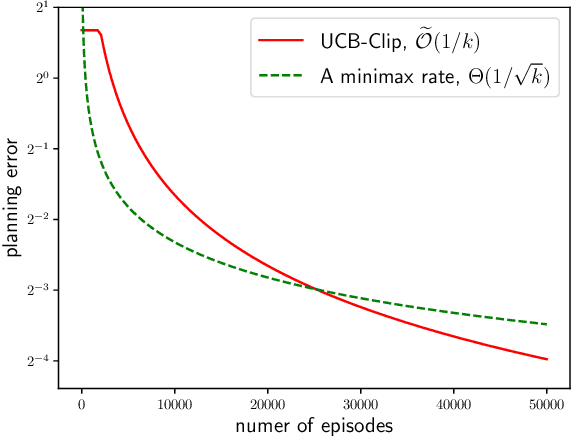
For the problem of task-agnostic reinforcement learning (RL), an agent first collects samples from an unknown environment without the supervision of reward signals, then is revealed with a reward and is asked to compute a corresponding near-optimal policy. Existing approaches mainly concern the worst-case scenarios, in which no structural information of the reward/transition-dynamics is utilized. Therefore the best sample upper bound is $\propto\widetilde{\mathcal{O}}(1/\epsilon^2)$, where $\epsilon>0$ is the target accuracy of the obtained policy, and can be overly pessimistic. To tackle this issue, we provide an efficient algorithm that utilizes a gap parameter, $\rho>0$, to reduce the amount of exploration. In particular, for an unknown finite-horizon Markov decision process, the algorithm takes only $\widetilde{\mathcal{O}} (1/\epsilon \cdot (H^3SA / \rho + H^4 S^2 A) )$ episodes of exploration, and is able to obtain an $\epsilon$-optimal policy for a post-revealed reward with sub-optimality gap at least $\rho$, where $S$ is the number of states, $A$ is the number of actions, and $H$ is the length of the horizon, obtaining a nearly \emph{quadratic saving} in terms of $\epsilon$. We show that, information-theoretically, this bound is nearly tight for $\rho < \Theta(1/(HS))$ and $H>1$. We further show that $\propto\widetilde{\mathcal{O}}(1)$ sample bound is possible for $H=1$ (i.e., multi-armed bandit) or with a sampling simulator, establishing a stark separation between those settings and the RL setting.
Blind Image Quality Assessment for MRI with A Deep Three-dimensional content-adaptive Hyper-Network
Jul 13, 2021



Image Quality Assessment (IQA) is of great value in the workflow of Magnetic Resonance Imaging (MRI)-based analysis. Blind IQA (BIQA) methods are especially required since high-quality reference MRI images are usually not available. Recently, many efforts have been devoted to developing deep learning-based BIQA approaches. However, the performance of these methods is limited due to the utilization of simple content-non-adaptive network parameters and the waste of the important 3D spatial information of the medical images. To address these issues, we design a 3D content-adaptive hyper-network for MRI BIQA. The overall 3D configuration enables the exploration of comprehensive 3D spatial information from MRI images, while the developed content-adaptive hyper-network contributes to the self-adaptive capacity of network parameters and thus, facilitates better BIQA performance. The effectiveness of the proposed method is extensively evaluated on the open dataset, MRIQC. Promising performance is achieved compared with the corresponding baseline and 4 state-of-the-art BIQA methods. We make our code available at \url{https://git.openi.org.cn/SIAT_Wangshanshan/HyS-Net}.
Survey of Recent Multi-Agent Reinforcement Learning Algorithms Utilizing Centralized Training
Jul 29, 2021Much work has been dedicated to the exploration of Multi-Agent Reinforcement Learning (MARL) paradigms implementing a centralized learning with decentralized execution (CLDE) approach to achieve human-like collaboration in cooperative tasks. Here, we discuss variations of centralized training and describe a recent survey of algorithmic approaches. The goal is to explore how different implementations of information sharing mechanism in centralized learning may give rise to distinct group coordinated behaviors in multi-agent systems performing cooperative tasks.
* This article appeared in the news at: https://www.army.mil/article/247261/army_researchers_develop_innovative_framework_for_training_ai
Scalable End-to-End Training of Knowledge Graph-Enhanced Aspect Embedding for Aspect Level Sentiment Analysis
Aug 26, 2021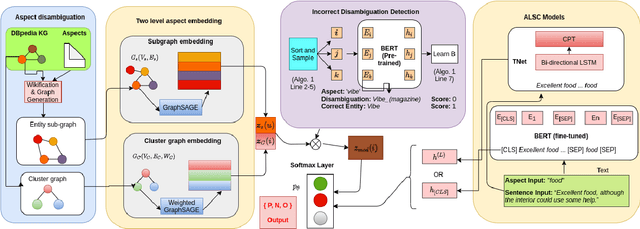

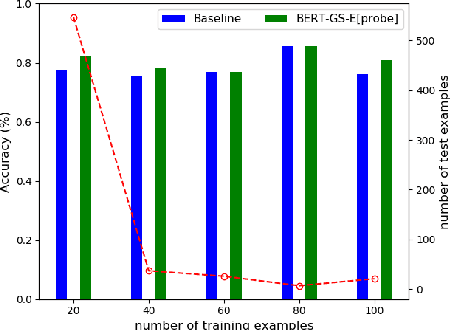
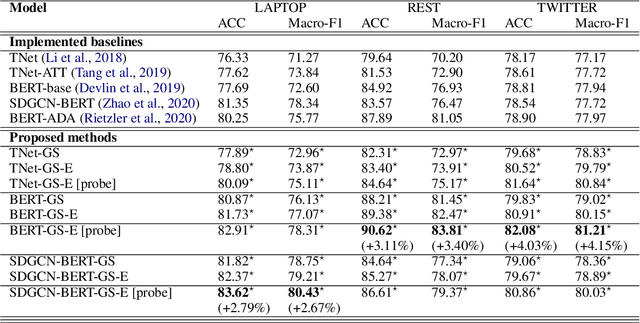
Aspect level sentiment classification (ALSC) is a difficult problem with state-of-the-art models showing less than 80% macro-F1 score on benchmark datasets. Existing models do not incorporate information on aspect-aspect relations in knowledge graphs (KGs), e.g. DBpedia. Two main challenges stem from inaccurate disambiguation of aspects to KG entities, and the inability to learn aspect representations from the large KGs in joint training with ALSC models. We propose a two-level global-local entity embedding scheme that allows efficient joint training of KG-based aspect embeddings and ALSC models. A novel incorrect disambiguation detection technique addresses the problem of inaccuracy in aspect disambiguation. The proposed methods show a consistent improvement of $2.5 - 4.1$ percentage points, over the recent BERT-based baselines.
CNN-DST: ensemble deep learning based on Dempster-Shafer theory for vibration-based fault recognition
Oct 14, 2021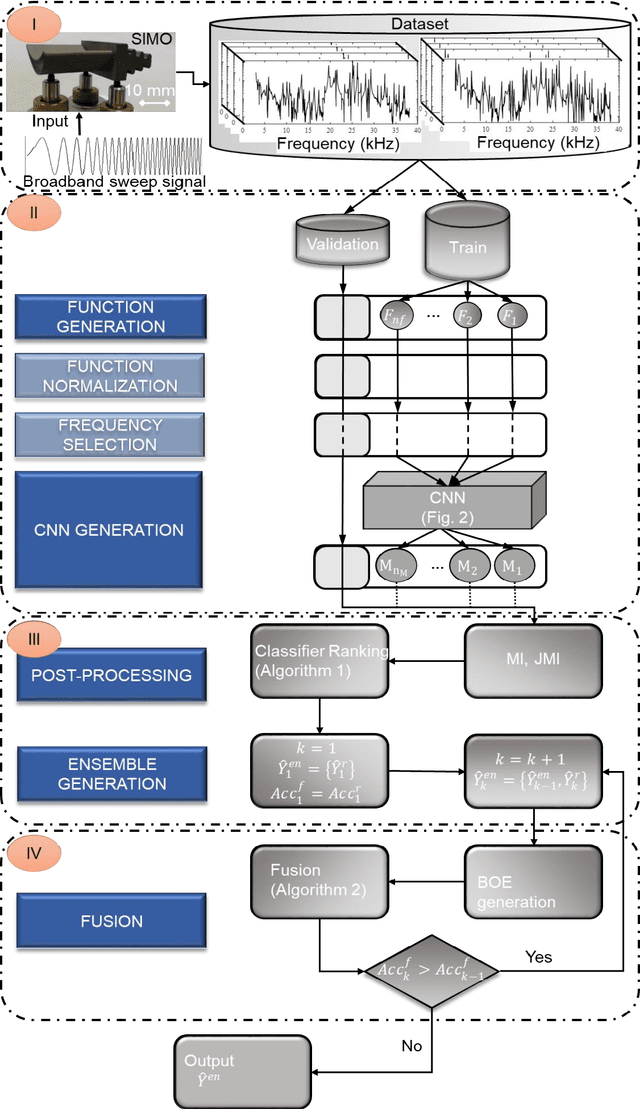
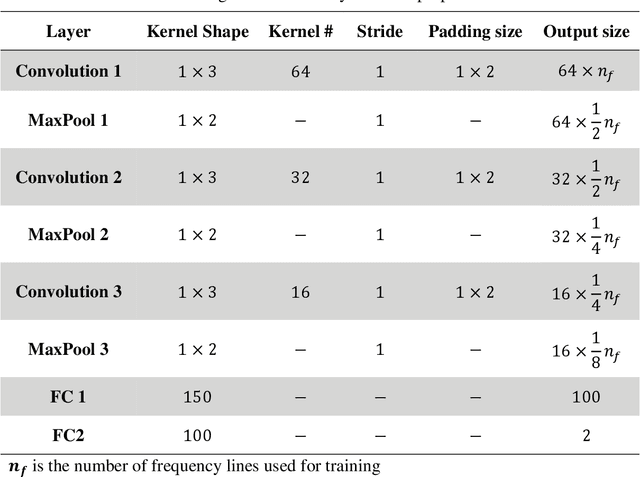
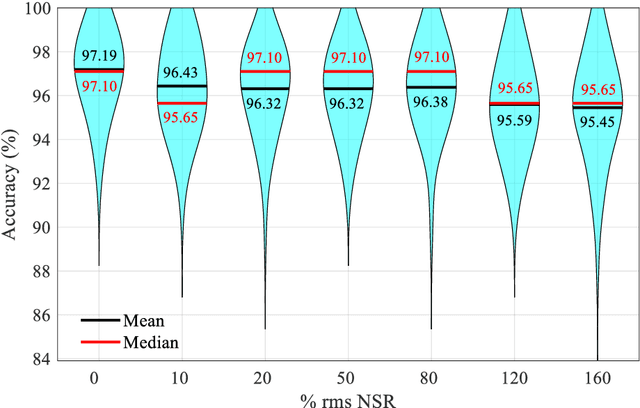
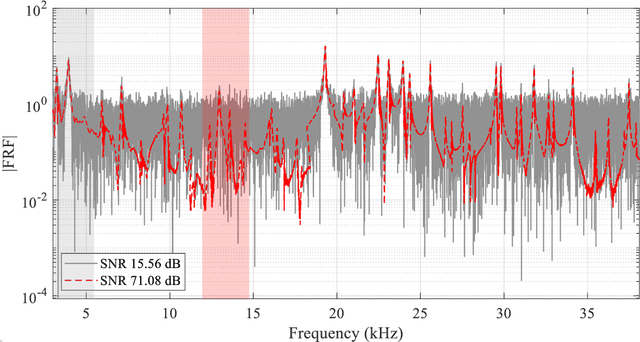
Nowadays, using vibration data in conjunction with pattern recognition methods is one of the most common fault detection strategies for structures. However, their performances depend on the features extracted from vibration data, the features selected to train the classifier, and the classifier used for pattern recognition. Deep learning facilitates the fault detection procedure by automating the feature extraction and selection, and classification procedure. Though, deep learning approaches have challenges in designing its structure and tuning its hyperparameters, which may result in a low generalization capability. Therefore, this study proposes an ensemble deep learning framework based on a convolutional neural network (CNN) and Dempster-Shafer theory (DST), called CNN-DST. In this framework, several CNNs with the proposed structure are first trained, and then, the outputs of the CNNs selected by the proposed technique are combined by using an improved DST-based method. To validate the proposed CNN-DST framework, it is applied to an experimental dataset created by the broadband vibrational responses of polycrystalline Nickel alloy first-stage turbine blades with different types and severities of damage. Through statistical analysis, it is shown that the proposed CNN-DST framework classifies the turbine blades with an average prediction accuracy of 97.19%. The proposed CNN-DST framework is benchmarked with other state-of-the-art classification methods, demonstrating its high performance. The robustness of the proposed CNN-DST framework with respect to measurement noise is investigated, showing its high noise-resistance. Further, bandwidth analysis reveals that most of the required information for detecting faulty samples is available in a small frequency range.
Video Coding for Machine: Compact Visual Representation Compression for Intelligent Collaborative Analytics
Oct 18, 2021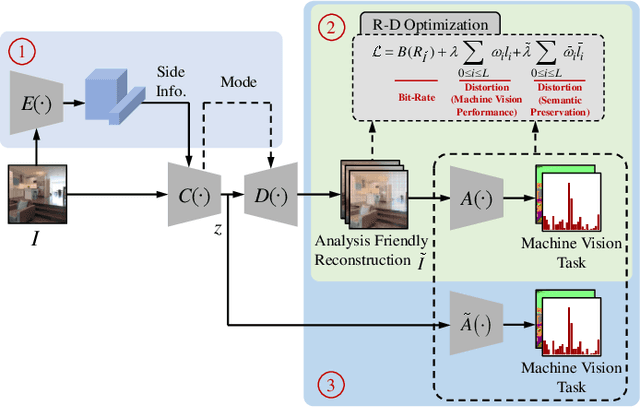
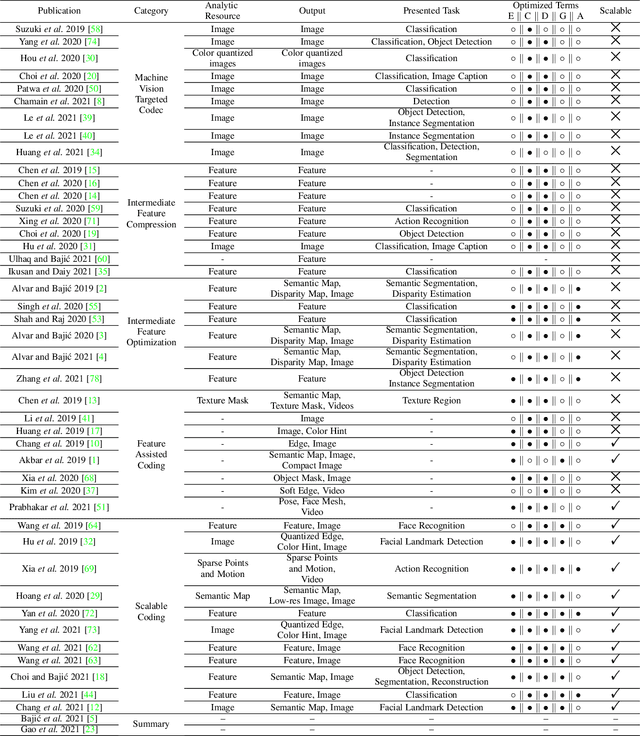
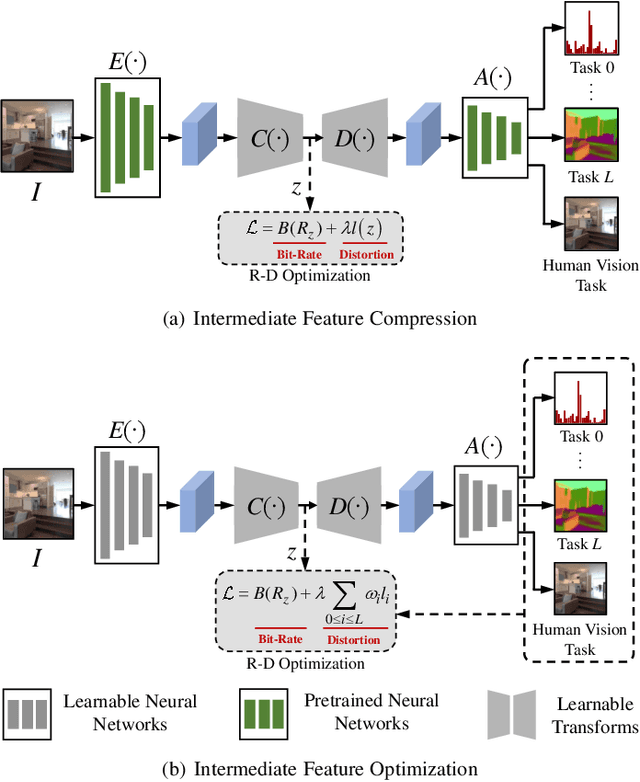
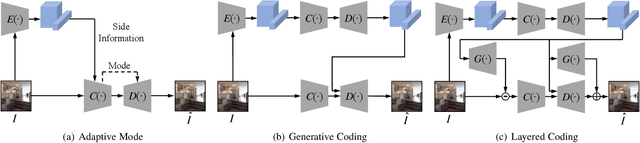
Video Coding for Machines (VCM) is committed to bridging to an extent separate research tracks of video/image compression and feature compression, and attempts to optimize compactness and efficiency jointly from a unified perspective of high accuracy machine vision and full fidelity human vision. In this paper, we summarize VCM methodology and philosophy based on existing academia and industrial efforts. The development of VCM follows a general rate-distortion optimization, and the categorization of key modules or techniques is established. From previous works, it is demonstrated that, although existing works attempt to reveal the nature of scalable representation in bits when dealing with machine and human vision tasks, there remains a rare study in the generality of low bit rate representation, and accordingly how to support a variety of visual analytic tasks. Therefore, we investigate a novel visual information compression for the analytics taxonomy problem to strengthen the capability of compact visual representations extracted from multiple tasks for visual analytics. A new perspective of task relationships versus compression is revisited. By keeping in mind the transferability among different machine vision tasks (e.g. high-level semantic and mid-level geometry-related), we aim to support multiple tasks jointly at low bit rates. In particular, to narrow the dimensionality gap between neural network generated features extracted from pixels and a variety of machine vision features/labels (e.g. scene class, segmentation labels), a codebook hyperprior is designed to compress the neural network-generated features. As demonstrated in our experiments, this new hyperprior model is expected to improve feature compression efficiency by estimating the signal entropy more accurately, which enables further investigation of the granularity of abstracting compact features among different tasks.
TERP: Reliable Planning in Uneven Outdoor Environments using Deep Reinforcement Learning
Sep 23, 2021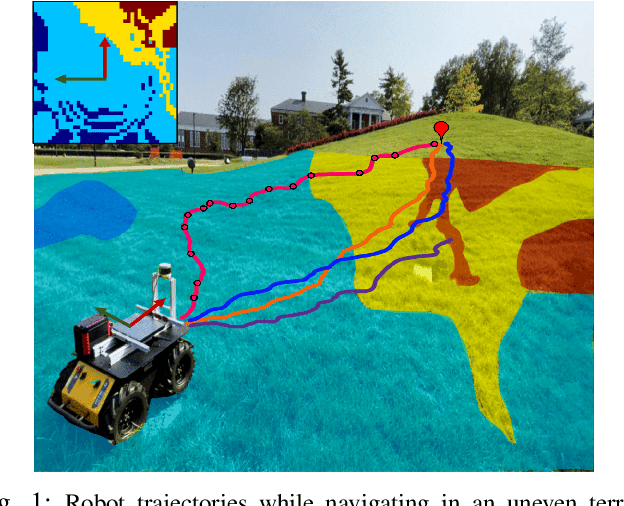
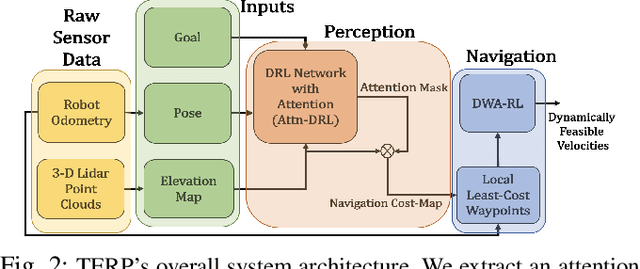
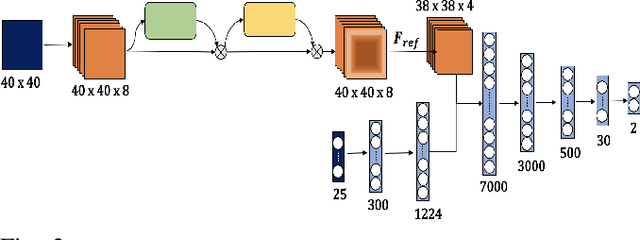
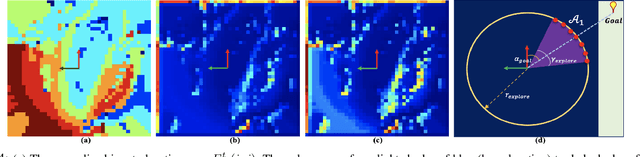
We present a novel method for reliable robot navigation in uneven outdoor terrains. Our approach employs a novel fully-trained Deep Reinforcement Learning (DRL) network that uses elevation maps of the environment, robot pose, and goal as inputs to compute an attention mask of the environment. The attention mask is used to identify reduced stability regions in the elevation map and is computed using channel and spatial attention modules and a novel reward function. We continuously compute and update a navigation cost-map that encodes the elevation information or the level-of-flatness of the terrain using the attention mask. We then generate locally least-cost waypoints on the cost-map and compute the final dynamically feasible trajectory using another DRL-based method. Our approach guarantees safe, locally least-cost paths and dynamically feasible robot velocities in uneven terrains. We observe an increase of 35.18% in terms of success rate and, a decrease of 26.14% in the cumulative elevation gradient of the robot's trajectory compared to prior navigation methods in high-elevation regions. We evaluate our method on a Husky robot in real-world uneven terrains (~ 4m of elevation gain) and demonstrate its benefits.
Entity Recognition at First Sight: Improving NER with Eye Movement Information
Mar 28, 2019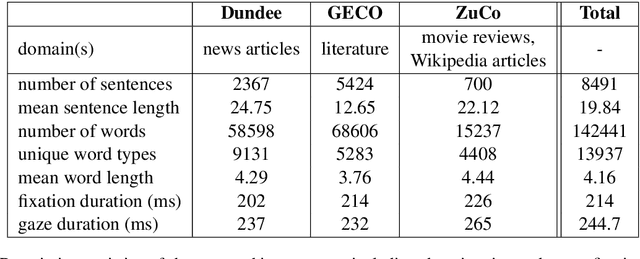
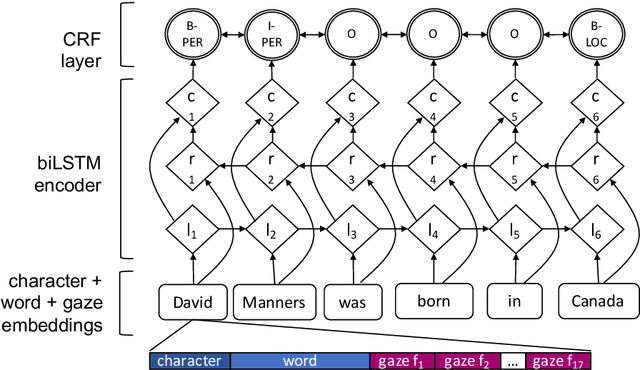
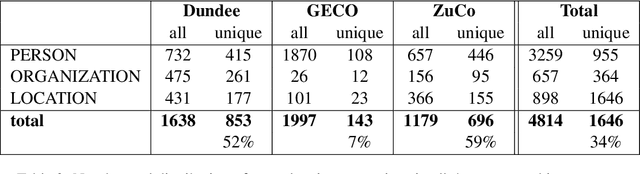
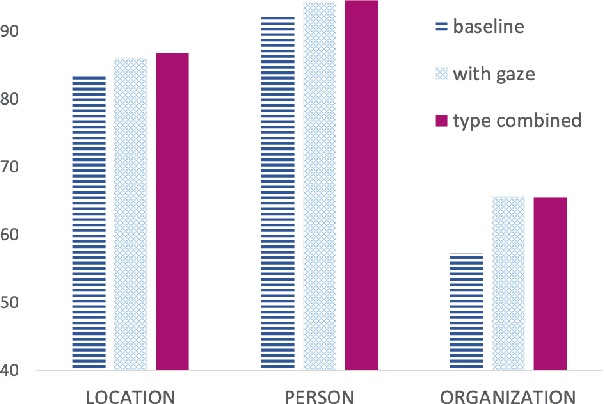
Previous research shows that eye-tracking data contains information about the lexical and syntactic properties of text, which can be used to improve natural language processing models. In this work, we leverage eye movement features from three corpora with recorded gaze information to augment a state-of-the-art neural model for named entity recognition (NER) with gaze embeddings. These corpora were manually annotated with named entity labels. Moreover, we show how gaze features, generalized on word type level, eliminate the need for recorded eye-tracking data at test time. The gaze-augmented models for NER using token-level and type-level features outperform the baselines. We present the benefits of eye-tracking features by evaluating the NER models on both individual datasets as well as in cross-domain settings.