 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Efficient Demonstration Selection for In-Context Learning
Jun 10, 2025



The in-context learning paradigm with LLMs has been instrumental in advancing a wide range of natural language processing tasks. The selection of few-shot examples (exemplars / demonstration samples) is essential for constructing effective prompts under context-length budget constraints. In this paper, we formulate the exemplar selection task as a top-m best arms identification problem. A key challenge in this setup is the exponentially large number of arms that need to be evaluated to identify the m-best arms. We propose CASE (Challenger Arm Sampling for Exemplar selection), a novel sample-efficient selective exploration strategy that maintains a shortlist of "challenger" arms, which are current candidates for the top-m arms. In each iteration, only one of the arms from this shortlist or the current topm set is pulled, thereby reducing sample complexity and, consequently, the number of LLM evaluations. Furthermore, we model the scores of exemplar subsets (arms) using a parameterized linear scoring function, leading to stochastic linear bandits setting. CASE achieves remarkable efficiency gains of up to 7x speedup in runtime while requiring 7x fewer LLM calls (87% reduction) without sacrificing performance compared to state-of-the-art exemplar selection methods. We release our code and data at https://github.com/kiranpurohit/CASE
EXPLORA: Efficient Exemplar Subset Selection for Complex Reasoning
Nov 06, 2024



Answering reasoning-based complex questions over text and hybrid sources, including tables, is a challenging task. Recent advances in large language models (LLMs) have enabled in-context learning (ICL), allowing LLMs to acquire proficiency in a specific task using only a few demonstration samples (exemplars). A critical challenge in ICL is the selection of optimal exemplars, which can be either task-specific (static) or test-example-specific (dynamic). Static exemplars provide faster inference times and increased robustness across a distribution of test examples. In this paper, we propose an algorithm for static exemplar subset selection for complex reasoning tasks. We introduce EXPLORA, a novel exploration method designed to estimate the parameters of the scoring function, which evaluates exemplar subsets without incorporating confidence information. EXPLORA significantly reduces the number of LLM calls to ~11% of those required by state-of-the-art methods and achieves a substantial performance improvement of 12.24%. We open-source our code and data (https://github.com/kiranpurohit/EXPLORA).
VTruST: Controllable value function based subset selection for Data-Centric Trustworthy AI
Mar 08, 2024



Trustworthy AI is crucial to the widespread adoption of AI in high-stakes applications with fairness, robustness, and accuracy being some of the key trustworthiness metrics. In this work, we propose a controllable framework for data-centric trustworthy AI (DCTAI)- VTruST, that allows users to control the trade-offs between the different trustworthiness metrics of the constructed training datasets. A key challenge in implementing an efficient DCTAI framework is to design an online value-function-based training data subset selection algorithm. We pose the training data valuation and subset selection problem as an online sparse approximation formulation. We propose a novel online version of the Orthogonal Matching Pursuit (OMP) algorithm for solving this problem. Experimental results show that VTruST outperforms the state-of-the-art baselines on social, image, and scientific datasets. We also show that the data values generated by VTruST can provide effective data-centric explanations for different trustworthiness metrics.
In-Context Ability Transfer for Question Decomposition in Complex QA
Oct 26, 2023



Answering complex questions is a challenging task that requires question decomposition and multistep reasoning for arriving at the solution. While existing supervised and unsupervised approaches are specialized to a certain task and involve training, recently proposed prompt-based approaches offer generalizable solutions to tackle a wide variety of complex question-answering (QA) tasks. However, existing prompt-based approaches that are effective for complex QA tasks involve expensive hand annotations from experts in the form of rationales and are not generalizable to newer complex QA scenarios and tasks. We propose, icat (In-Context Ability Transfer) which induces reasoning capabilities in LLMs without any LLM fine-tuning or manual annotation of in-context samples. We transfer the ability to decompose complex questions to simpler questions or generate step-by-step rationales to LLMs, by careful selection from available data sources of related tasks. We also propose an automated uncertainty-aware exemplar selection approach for selecting examples from transfer data sources. Finally, we conduct large-scale experiments on a variety of complex QA tasks involving numerical reasoning, compositional complex QA, and heterogeneous complex QA which require decomposed reasoning. We show that ICAT convincingly outperforms existing prompt-based solutions without involving any model training, showcasing the benefits of re-using existing abilities.
LearnDefend: Learning to Defend against Targeted Model-Poisoning Attacks on Federated Learning
May 03, 2023



Targeted model poisoning attacks pose a significant threat to federated learning systems. Recent studies show that edge-case targeted attacks, which target a small fraction of the input space are nearly impossible to counter using existing fixed defense strategies. In this paper, we strive to design a learned-defense strategy against such attacks, using a small defense dataset. The defense dataset can be collected by the central authority of the federated learning task, and should contain a mix of poisoned and clean examples. The proposed framework, LearnDefend, estimates the probability of a client update being malicious. The examples in defense dataset need not be pre-marked as poisoned or clean. We also learn a poisoned data detector model which can be used to mark each example in the defense dataset as clean or poisoned. We estimate the poisoned data detector and the client importance models in a coupled optimization approach. Our experiments demonstrate that LearnDefend is capable of defending against state-of-the-art attacks where existing fixed defense strategies fail. We also show that LearnDefend is robust to size and noise in the marking of clean examples in the defense dataset.
Modeling Continuous Time Sequences with Intermittent Observations using Marked Temporal Point Processes
Jun 23, 2022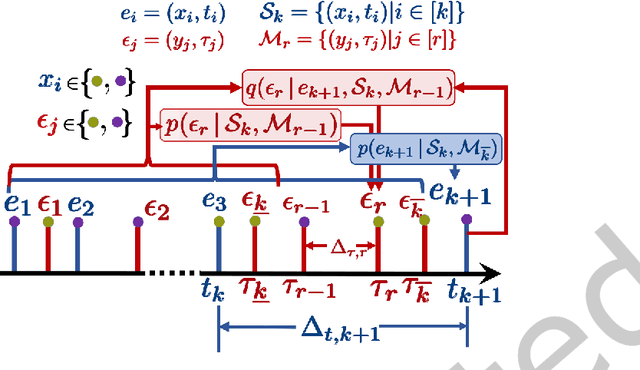

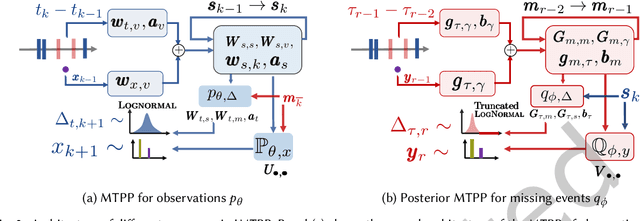
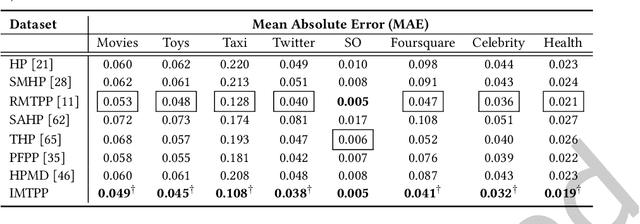
A large fraction of data generated via human activities such as online purchases, health records, spatial mobility etc. can be represented as a sequence of events over a continuous-time. Learning deep learning models over these continuous-time event sequences is a non-trivial task as it involves modeling the ever-increasing event timestamps, inter-event time gaps, event types, and the influences between different events within and across different sequences. In recent years neural enhancements to marked temporal point processes (MTPP) have emerged as a powerful framework to model the underlying generative mechanism of asynchronous events localized in continuous time. However, most existing models and inference methods in the MTPP framework consider only the complete observation scenario i.e. the event sequence being modeled is completely observed with no missing events -- an ideal setting that is rarely applicable in real-world applications. A recent line of work which considers missing events while training MTPP utilizes supervised learning techniques that require additional knowledge of missing or observed label for each event in a sequence, which further restricts its practicability as in several scenarios the details of missing events is not known apriori. In this work, we provide a novel unsupervised model and inference method for learning MTPP in presence of event sequences with missing events. Specifically, we first model the generative processes of observed events and missing events using two MTPP, where the missing events are represented as latent random variables. Then, we devise an unsupervised training method that jointly learns both the MTPP by means of variational inference. Such a formulation can effectively impute the missing data among the observed events and can identify the optimal position of missing events in a sequence.
CheckSel: Efficient and Accurate Data-valuation Through Online Checkpoint Selection
Mar 14, 2022
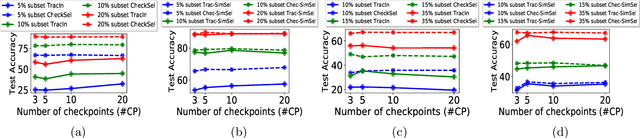
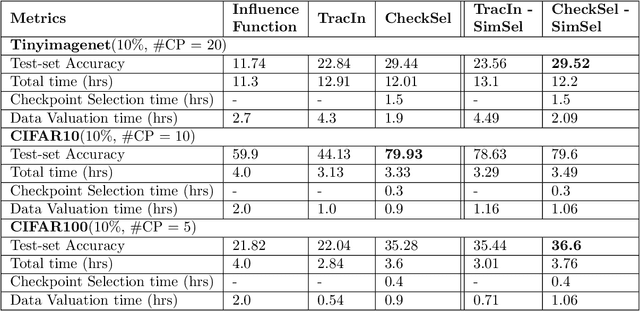
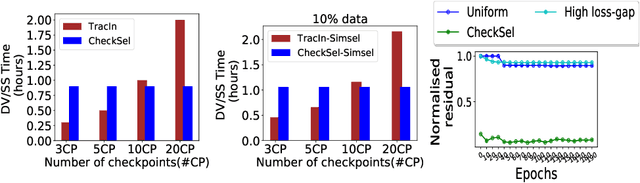
Data valuation and subset selection have emerged as valuable tools for application-specific selection of important training data. However, the efficiency-accuracy tradeoffs of state-of-the-art methods hinder their widespread application to many AI workflows. In this paper, we propose a novel 2-phase solution to this problem. Phase 1 selects representative checkpoints from an SGD-like training algorithm, which are used in phase-2 to estimate the approximate training data values, e.g. decrease in validation loss due to each training point. A key contribution of this paper is CheckSel, an Orthogonal Matching Pursuit-inspired online sparse approximation algorithm for checkpoint selection in the online setting, where the features are revealed one at a time. Another key contribution is the study of data valuation in the domain adaptation setting, where a data value estimator obtained using checkpoints from training trajectory in the source domain training dataset is used for data valuation in a target domain training dataset. Experimental results on benchmark datasets show the proposed algorithm outperforms recent baseline methods by up to 30% in terms of test accuracy while incurring a similar computational burden, for both standalone and domain adaptation settings.
Offsetting Unequal Competition through RL-assisted Incentive Schemes
Jan 05, 2022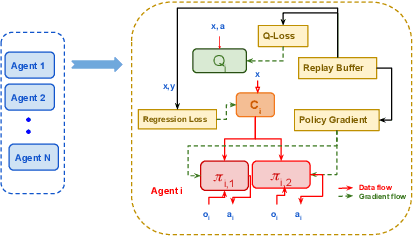
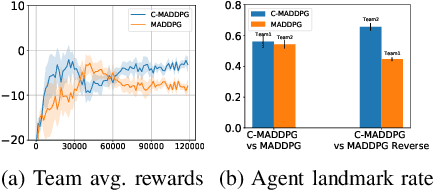
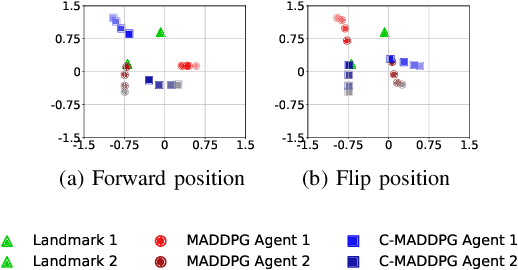
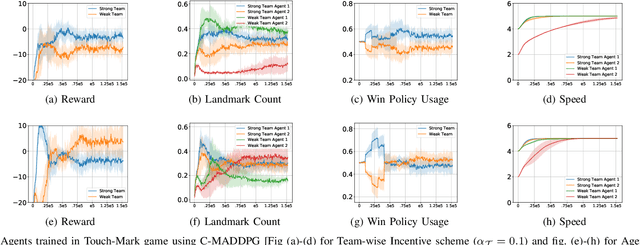
This paper investigates the dynamics of competition among organizations with unequal expertise. Multi-agent reinforcement learning has been used to simulate and understand the impact of various incentive schemes designed to offset such inequality. We design Touch-Mark, a game based on well-known multi-agent-particle-environment, where two teams (weak, strong) with unequal but changing skill levels compete against each other. For training such a game, we propose a novel controller assisted multi-agent reinforcement learning algorithm \our\, which empowers each agent with an ensemble of policies along with a supervised controller that by selectively partitioning the sample space, triggers intelligent role division among the teammates. Using C-MADDPG as an underlying framework, we propose an incentive scheme for the weak team such that the final rewards of both teams become the same. We find that in spite of the incentive, the final reward of the weak team falls short of the strong team. On inspecting, we realize that an overall incentive scheme for the weak team does not incentivize the weaker agents within that team to learn and improve. To offset this, we now specially incentivize the weaker player to learn and as a result, observe that the weak team beyond an initial phase performs at par with the stronger team. The final goal of the paper has been to formulate a dynamic incentive scheme that continuously balances the reward of the two teams. This is achieved by devising an incentive scheme enriched with an RL agent which takes minimum information from the environment.
MTLTS: A Multi-Task Framework To Obtain Trustworthy Summaries From Crisis-Related Microblogs
Dec 10, 2021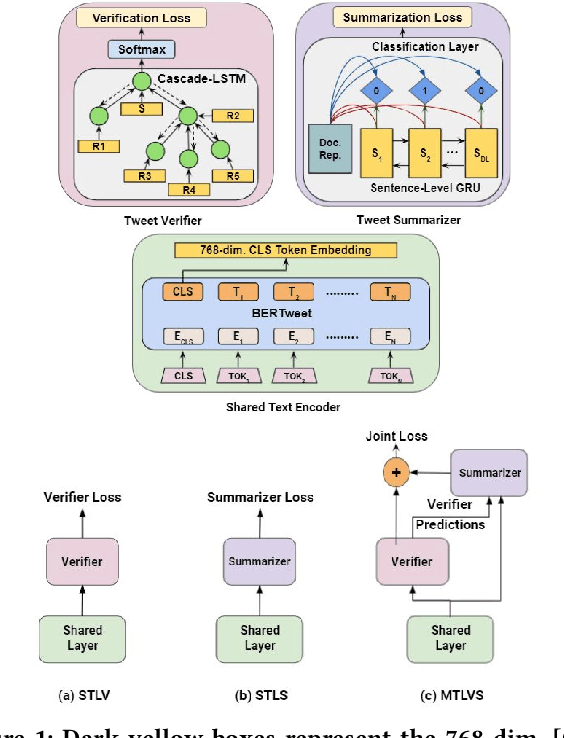
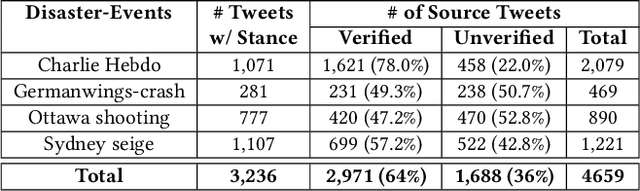
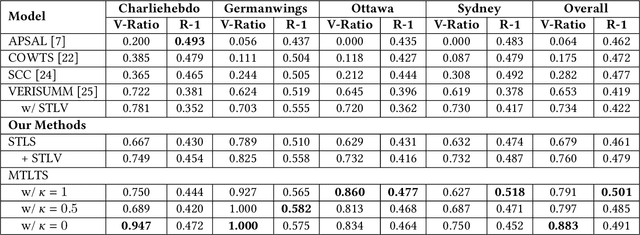
Occurrences of catastrophes such as natural or man-made disasters trigger the spread of rumours over social media at a rapid pace. Presenting a trustworthy and summarized account of the unfolding event in near real-time to the consumers of such potentially unreliable information thus becomes an important task. In this work, we propose MTLTS, the first end-to-end solution for the task that jointly determines the credibility and summary-worthiness of tweets. Our credibility verifier is designed to recursively learn the structural properties of a Twitter conversation cascade, along with the stances of replies towards the source tweet. We then take a hierarchical multi-task learning approach, where the verifier is trained at a lower layer, and the summarizer is trained at a deeper layer where it utilizes the verifier predictions to determine the salience of a tweet. Different from existing disaster-specific summarizers, we model tweet summarization as a supervised task. Such an approach can automatically learn summary-worthy features, and can therefore generalize well across domains. When trained on the PHEME dataset [29], not only do we outperform the strongest baselines for the auxiliary task of verification/rumour detection, we also achieve 21 - 35% gains in the verified ratio of summary tweets, and 16 - 20% gains in ROUGE1-F1 scores over the existing state-of-the-art solutions for the primary task of trustworthy summarization.
PASTE: A Tagging-Free Decoding Framework Using Pointer Networks for Aspect Sentiment Triplet Extraction
Oct 10, 2021


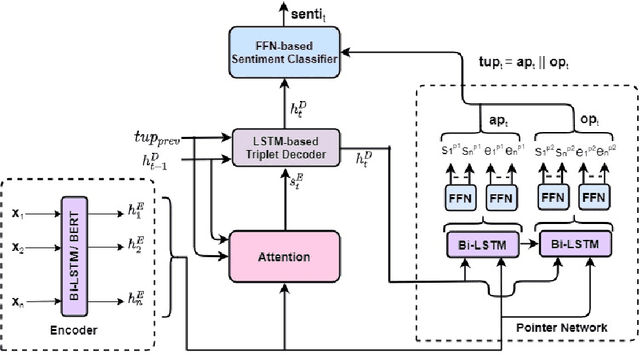
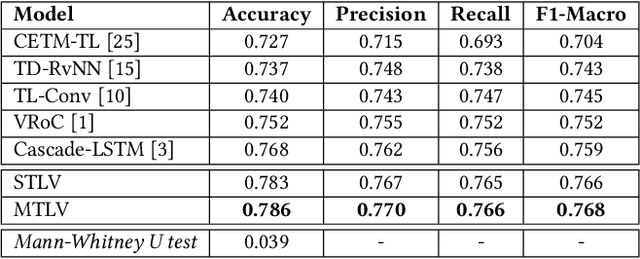
Aspect Sentiment Triplet Extraction (ASTE) deals with extracting opinion triplets, consisting of an opinion target or aspect, its associated sentiment, and the corresponding opinion term/span explaining the rationale behind the sentiment. Existing research efforts are majorly tagging-based. Among the methods taking a sequence tagging approach, some fail to capture the strong interdependence between the three opinion factors, whereas others fall short of identifying triplets with overlapping aspect/opinion spans. A recent grid tagging approach on the other hand fails to capture the span-level semantics while predicting the sentiment between an aspect-opinion pair. Different from these, we present a tagging-free solution for the task, while addressing the limitations of the existing works. We adapt an encoder-decoder architecture with a Pointer Network-based decoding framework that generates an entire opinion triplet at each time step thereby making our solution end-to-end. Interactions between the aspects and opinions are effectively captured by the decoder by considering their entire detected spans while predicting their connecting sentiment. Extensive experiments on several benchmark datasets establish the better efficacy of our proposed approach, especially in the recall, and in predicting multiple and aspect/opinion-overlapped triplets from the same review sentence. We report our results both with and without BERT and also demonstrate the utility of domain-specific BERT post-training for the task.