 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopo-R1: Detecting Topological Anomalies via Vision-Language Models
Mar 13, 2026Topological correctness is crucial for tubular structures such as blood vessels, nerve fibers, and road networks. Existing topology-preserving methods rely on domain-specific ground truth, which is costly and rarely transfers across domains. When deployed to a new domain without annotations, a key question arises: how can we detect topological anomalies without ground-truth supervision? We reframe this as topological anomaly detection, a structured visual reasoning task requiring a model to locate and classify topological errors in predicted segmentation masks. Vision-Language Models (VLMs) are natural candidates; however, we find that state-of-the-art VLMs perform nearly at random, lacking the fine-grained, topology-aware perception needed to identify sparse connectivity errors in dense structures. To bridge this gap, we develop an automated data-curation pipeline that synthesizes diverse topological anomalies with verifiable annotations across progressively difficult levels, thereby constructing the first large-scale, multi-domain benchmark for this task. We then introduce Topo-R1, a framework that endows VLMs with topology-aware perception via two-stage training: supervised fine-tuning followed by reinforcement learning with Group Relative Policy Optimization (GRPO). Central to our approach is a topology-aware composite reward that integrates type-aware Hungarian matching for structured error classification, spatial localization scoring, and a centerline Dice (clDice) reward that directly penalizes connectivity disruptions, thereby jointly incentivizing semantic precision and structural fidelity. Extensive experiments demonstrate that Topo-R1 establishes a new paradigm for annotation-free topological quality assessment, consistently outperforming general-purpose VLMs and supervised baselines across all evaluation protocols.
Blind Image Quality Assessment for MRI with A Deep Three-dimensional content-adaptive Hyper-Network
Jul 13, 2021



Image Quality Assessment (IQA) is of great value in the workflow of Magnetic Resonance Imaging (MRI)-based analysis. Blind IQA (BIQA) methods are especially required since high-quality reference MRI images are usually not available. Recently, many efforts have been devoted to developing deep learning-based BIQA approaches. However, the performance of these methods is limited due to the utilization of simple content-non-adaptive network parameters and the waste of the important 3D spatial information of the medical images. To address these issues, we design a 3D content-adaptive hyper-network for MRI BIQA. The overall 3D configuration enables the exploration of comprehensive 3D spatial information from MRI images, while the developed content-adaptive hyper-network contributes to the self-adaptive capacity of network parameters and thus, facilitates better BIQA performance. The effectiveness of the proposed method is extensively evaluated on the open dataset, MRIQC. Promising performance is achieved compared with the corresponding baseline and 4 state-of-the-art BIQA methods. We make our code available at \url{https://git.openi.org.cn/SIAT_Wangshanshan/HyS-Net}.
Multi-task MR Imaging with Iterative Teacher Forcing and Re-weighted Deep Learning
Nov 27, 2020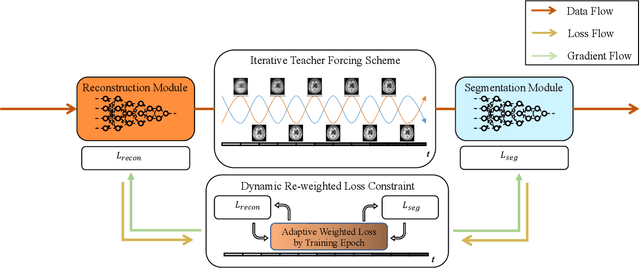

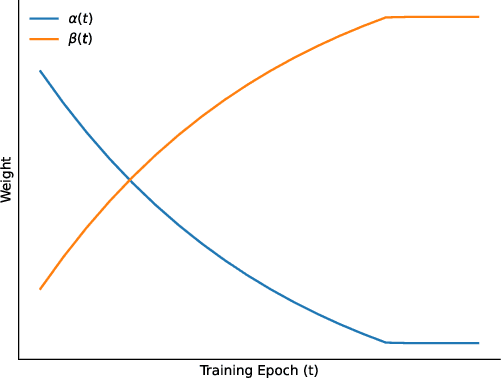
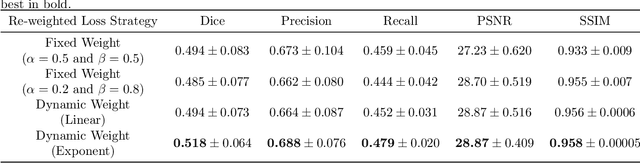
Noises, artifacts, and loss of information caused by the magnetic resonance (MR) reconstruction may compromise the final performance of the downstream applications. In this paper, we develop a re-weighted multi-task deep learning method to learn prior knowledge from the existing big dataset and then utilize them to assist simultaneous MR reconstruction and segmentation from the under-sampled k-space data. The multi-task deep learning framework is equipped with two network sub-modules, which are integrated and trained by our designed iterative teacher forcing scheme (ITFS) under the dynamic re-weighted loss constraint (DRLC). The ITFS is designed to avoid error accumulation by injecting the fully-sampled data into the training process. The DRLC is proposed to dynamically balance the contributions from the reconstruction and segmentation sub-modules so as to co-prompt the multi-task accuracy. The proposed method has been evaluated on two open datasets and one in vivo in-house dataset and compared to six state-of-the-art methods. Results show that the proposed method possesses encouraging capabilities for simultaneous and accurate MR reconstruction and segmentation.
CLCI-Net: Cross-Level fusion and Context Inference Networks for Lesion Segmentation of Chronic Stroke
Jul 17, 2019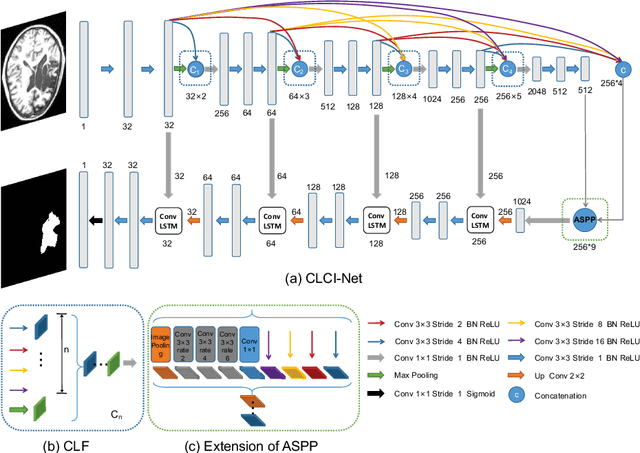
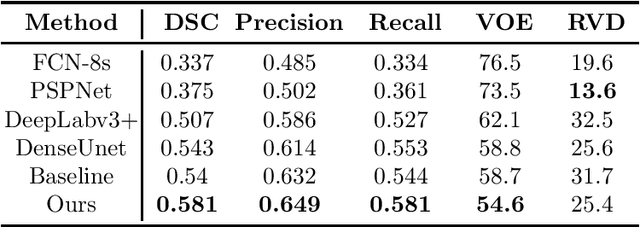
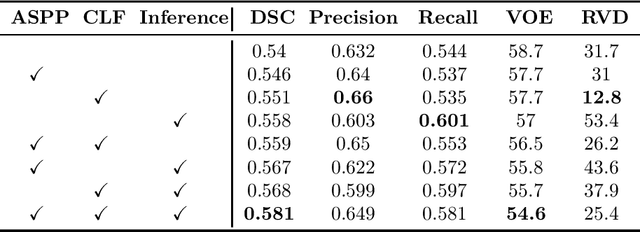
Segmenting stroke lesions from T1-weighted MR images is of great value for large-scale stroke rehabilitation neuroimaging analyses. Nevertheless, there are great challenges with this task, such as large range of stroke lesion scales and the tissue intensity similarity. The famous encoder-decoder convolutional neural network, which although has made great achievements in medical image segmentation areas, may fail to address these challenges due to the insufficient uses of multi-scale features and context information. To address these challenges, this paper proposes a Cross-Level fusion and Context Inference Network (CLCI-Net) for the chronic stroke lesion segmentation from T1-weighted MR images. Specifically, a Cross-Level feature Fusion (CLF) strategy was developed to make full use of different scale features across different levels; Extending Atrous Spatial Pyramid Pooling (ASPP) with CLF, we have enriched multi-scale features to handle the different lesion sizes; In addition, convolutional long short-term memory (ConvLSTM) is employed to infer context information and thus capture fine structures to address the intensity similarity issue. The proposed approach was evaluated on an open-source dataset, the Anatomical Tracings of Lesions After Stroke (ATLAS) with the results showing that our network outperforms five state-of-the-art methods. We make our code and models available at https://github.com/YH0517/CLCI_Net.
X-Net: Brain Stroke Lesion Segmentation Based on Depthwise Separable Convolution and Long-range Dependencies
Jul 16, 2019



The morbidity of brain stroke increased rapidly in the past few years. To help specialists in lesion measurements and treatment planning, automatic segmentation methods are critically required for clinical practices. Recently, approaches based on deep learning and methods for contextual information extraction have served in many image segmentation tasks. However, their performances are limited due to the insufficient training of a large number of parameters, which sometimes fail in capturing long-range dependencies. To address these issues, we propose a depthwise separable convolution based X-Net that designs a nonlocal operation namely Feature Similarity Module (FSM) to capture long-range dependencies. The adopted depthwise convolution allows to reduce the network size, while the developed FSM provides a more effective, dense contextual information extraction and thus facilitates better segmentation. The effectiveness of X-Net was evaluated on an open dataset Anatomical Tracings of Lesions After Stroke (ATLAS) with superior performance achieved compared to other six state-of-the-art approaches. We make our code and models available at https://github.com/Andrewsher/X-Net.