 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Pre-trained Language Model for Speech Sentiment Analysis
Paper and Code
Jun 11, 2021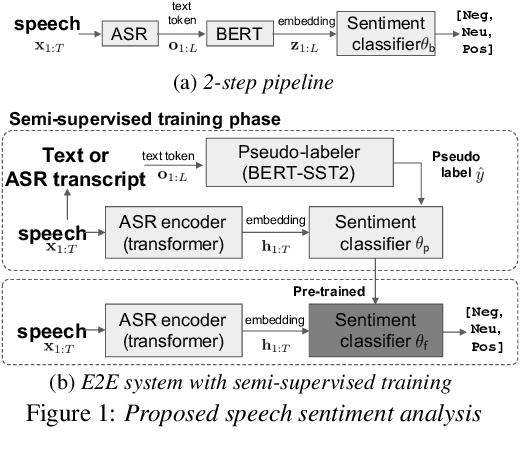
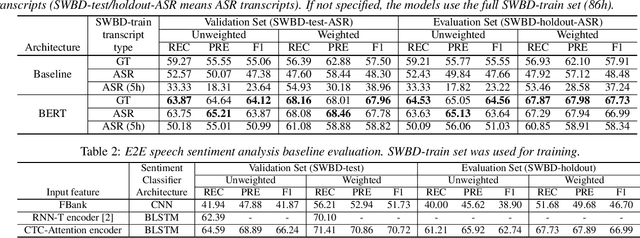
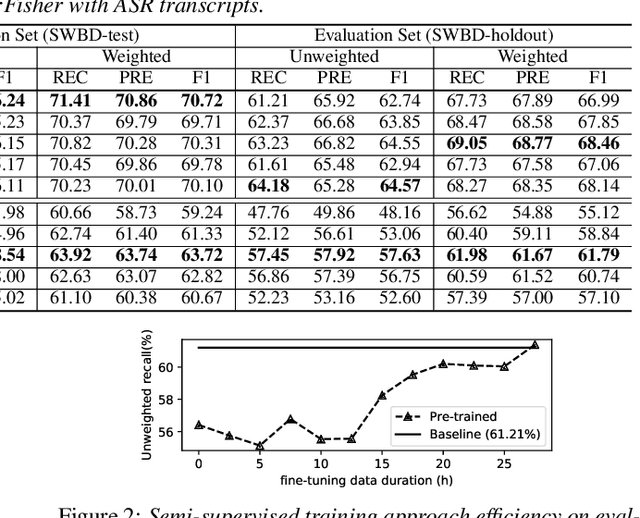
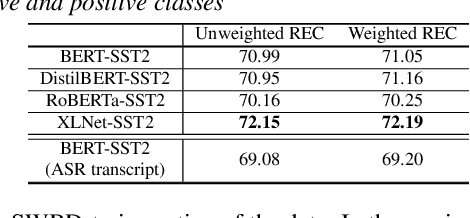
In this paper, we explore the use of pre-trained language models to learn sentiment information of written texts for speech sentiment analysis. First, we investigate how useful a pre-trained language model would be in a 2-step pipeline approach employing Automatic Speech Recognition (ASR) and transcripts-based sentiment analysis separately. Second, we propose a pseudo label-based semi-supervised training strategy using a language model on an end-to-end speech sentiment approach to take advantage of a large, but unlabeled speech dataset for training. Although spoken and written texts have different linguistic characteristics, they can complement each other in understanding sentiment. Therefore, the proposed system can not only model acoustic characteristics to bear sentiment-specific information in speech signals, but learn latent information to carry sentiments in the text representation. In these experiments, we demonstrate the proposed approaches improve F1 scores consistently compared to systems without a language model. Moreover, we also show that the proposed framework can reduce 65% of human supervision by leveraging a large amount of data without human sentiment annotation and boost performance in a low-resource condition where the human sentiment annotation is not available enough.