 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurfelSoup: Learned Point Cloud Geometry Compression With a Probablistic SurfelTree Representation
Jan 30, 2026This paper presents SurfelSoup, an end-to-end learned surface-based framework for point cloud geometry compression, with surface-structured primitives for representation. It proposes a probabilistic surface representation, pSurfel, which models local point occupancies using a bounded generalized Gaussian distribution. In addition, the pSurfels are organized into an octree-like hierarchy, pSurfelTree, with a Tree Decision module that adaptively terminates the tree subdivision for rate-distortion optimal Surfel granularity selection. This formulation avoids redundant point-wise compression in smooth regions and produces compact yet smooth surface reconstructions. Experimental results under the MPEG common test condition show consistent gain on geometry compression over voxel-based baselines and MPEG standard G-PCC-GesTM-TriSoup, while providing visually superior reconstructions with smooth and coherent surface structures.
TeSO: Representing and Compressing 3D Point Cloud Scenes with Textured Surfel Octree
Aug 09, 20253D visual content streaming is a key technology for emerging 3D telepresence and AR/VR applications. One fundamental element underlying the technology is a versatile 3D representation that is capable of producing high-quality renders and can be efficiently compressed at the same time. Existing 3D representations like point clouds, meshes and 3D Gaussians each have limitations in terms of rendering quality, surface definition, and compressibility. In this paper, we present the Textured Surfel Octree (TeSO), a novel 3D representation that is built from point clouds but addresses the aforementioned limitations. It represents a 3D scene as cube-bounded surfels organized on an octree, where each surfel is further associated with a texture patch. By approximating a smooth surface with a large surfel at a coarser level of the octree, it reduces the number of primitives required to represent the 3D scene, and yet retains the high-frequency texture details through the texture map attached to each surfel. We further propose a compression scheme to encode the geometry and texture efficiently, leveraging the octree structure. The proposed textured surfel octree combined with the compression scheme achieves higher rendering quality at lower bit-rates compared to multiple point cloud and 3D Gaussian-based baselines.
U-Motion: Learned Point Cloud Video Compression with U-Structured Motion Estimation
Nov 21, 2024



Point cloud video (PCV) is a versatile 3D representation of dynamic scenes with many emerging applications. This paper introduces U-Motion, a learning-based compression scheme for both PCV geometry and attributes. We propose a U-Structured multiscale inter-frame prediction framework, U-Inter, which performs layer-wise explicit motion estimation and compensation (ME/MC) at different scales with varying levels of detail. It integrates both higher and lower-scale motion features, in addition to the information of current and previous frames, to enable accurate motion estimation at the current scale. In addition, we design a cascaded spatial predictive coding module to capture the inter-scale spatial redundancy remaining after U-Inter prediction. We further propose an effective context detach and restore scheme to reduce spatial-temporal redundancy in the motion and latent bit-streams and improve compression performance. We conduct experiments following the MPEG Common Test Condition and demonstrate that U-Motion can achieve significant gains over MPEG G-PCC-GesTM v3.0 and recently published learning-based methods for both geometry and attribute compression.
Spatial Visibility and Temporal Dynamics: Revolutionizing Field of View Prediction in Adaptive Point Cloud Video Streaming
Sep 26, 2024



Field-of-View (FoV) adaptive streaming significantly reduces bandwidth requirement of immersive point cloud video (PCV) by only transmitting visible points in a viewer's FoV. The traditional approaches often focus on trajectory-based 6 degree-of-freedom (6DoF) FoV predictions. The predicted FoV is then used to calculate point visibility. Such approaches do not explicitly consider video content's impact on viewer attention, and the conversion from FoV to point visibility is often error-prone and time-consuming. We reformulate the PCV FoV prediction problem from the cell visibility perspective, allowing for precise decision-making regarding the transmission of 3D data at the cell level based on the predicted visibility distribution. We develop a novel spatial visibility and object-aware graph model that leverages the historical 3D visibility data and incorporates spatial perception, neighboring cell correlation, and occlusion information to predict the cell visibility in the future. Our model significantly improves the long-term cell visibility prediction, reducing the prediction MSE loss by up to 50% compared to the state-of-the-art models while maintaining real-time performance (more than 30fps) for point cloud videos with over 1 million points.
Low Latency Point Cloud Rendering with Learned Splatting
Sep 24, 2024



Point cloud is a critical 3D representation with many emerging applications. Because of the point sparsity and irregularity, high-quality rendering of point clouds is challenging and often requires complex computations to recover the continuous surface representation. On the other hand, to avoid visual discomfort, the motion-to-photon latency has to be very short, under 10 ms. Existing rendering solutions lack in either quality or speed. To tackle these challenges, we present a framework that unlocks interactive, free-viewing and high-fidelity point cloud rendering. We train a generic neural network to estimate 3D elliptical Gaussians from arbitrary point clouds and use differentiable surface splatting to render smooth texture and surface normal for arbitrary views. Our approach does not require per-scene optimization, and enable real-time rendering of dynamic point cloud. Experimental results demonstrate the proposed solution enjoys superior visual quality and speed, as well as generalizability to different scene content and robustness to compression artifacts. The code is available at https://github.com/huzi96/gaussian-pcloud-render .
Standard compliant video coding using low complexity, switchable neural wrappers
Jul 10, 2024The proliferation of high resolution videos posts great storage and bandwidth pressure on cloud video services, driving the development of next-generation video codecs. Despite great progress made in neural video coding, existing approaches are still far from economical deployment considering the complexity and rate-distortion performance tradeoff. To clear the roadblocks for neural video coding, in this paper we propose a new framework featuring standard compatibility, high performance, and low decoding complexity. We employ a set of jointly optimized neural pre- and post-processors, wrapping a standard video codec, to encode videos at different resolutions. The rate-distorion optimal downsampling ratio is signaled to the decoder at the per-sequence level for each target rate. We design a low complexity neural post-processor architecture that can handle different upsampling ratios. The change of resolution exploits the spatial redundancy in high-resolution videos, while the neural wrapper further achieves rate-distortion performance improvement through end-to-end optimization with a codec proxy. Our light-weight post-processor architecture has a complexity of 516 MACs / pixel, and achieves 9.3% BD-Rate reduction over VVC on the UVG dataset, and 6.4% on AOM CTC Class A1. Our approach has the potential to further advance the performance of the latest video coding standards using neural processing with minimal added complexity.
Bits-to-Photon: End-to-End Learned Scalable Point Cloud Compression for Direct Rendering
Jun 09, 2024



Point cloud is a promising 3D representation for volumetric streaming in emerging AR/VR applications. Despite recent advances in point cloud compression, decoding and rendering high-quality images from lossy compressed point clouds is still challenging in terms of quality and complexity, making it a major roadblock to achieve real-time 6-Degree-of-Freedom video streaming. In this paper, we address this problem by developing a point cloud compression scheme that generates a bit stream that can be directly decoded to renderable 3D Gaussians. The encoder and decoder are jointly optimized to consider both bit-rates and rendering quality. It significantly improves the rendering quality while substantially reducing decoding and rendering time, compared to existing point cloud compression methods. Furthermore, the proposed scheme generates a scalable bit stream, allowing multiple levels of details at different bit-rate ranges. Our method supports real-time color decoding and rendering of high quality point clouds, thus paving the way for interactive 3D streaming applications with free view points.
One-Click Upgrade from 2D to 3D: Sandwiched RGB-D Video Compression for Stereoscopic Teleconferencing
Apr 15, 2024



Stereoscopic video conferencing is still challenging due to the need to compress stereo RGB-D video in real-time. Though hardware implementations of standard video codecs such as H.264 / AVC and HEVC are widely available, they are not designed for stereoscopic videos and suffer from reduced quality and performance. Specific multiview or 3D extensions of these codecs are complex and lack efficient implementations. In this paper, we propose a new approach to upgrade a 2D video codec to support stereo RGB-D video compression, by wrapping it with a neural pre- and post-processor pair. The neural networks are end-to-end trained with an image codec proxy, and shown to work with a more sophisticated video codec. We also propose a geometry-aware loss function to improve rendering quality. We train the neural pre- and post-processors on a synthetic 4D people dataset, and evaluate it on both synthetic and real-captured stereo RGB-D videos. Experimental results show that the neural networks generalize well to unseen data and work out-of-box with various video codecs. Our approach saves about 30% bit-rate compared to a conventional video coding scheme and MV-HEVC at the same level of rendering quality from a novel view, without the need of a task-specific hardware upgrade.
Learning Neural Volumetric Field for Point Cloud Geometry Compression
Dec 11, 2022Due to the diverse sparsity, high dimensionality, and large temporal variation of dynamic point clouds, it remains a challenge to design an efficient point cloud compression method. We propose to code the geometry of a given point cloud by learning a neural volumetric field. Instead of representing the entire point cloud using a single overfit network, we divide the entire space into small cubes and represent each non-empty cube by a neural network and an input latent code. The network is shared among all the cubes in a single frame or multiple frames, to exploit the spatial and temporal redundancy. The neural field representation of the point cloud includes the network parameters and all the latent codes, which are generated by using back-propagation over the network parameters and its input. By considering the entropy of the network parameters and the latent codes as well as the distortion between the original and reconstructed cubes in the loss function, we derive a rate-distortion (R-D) optimal representation. Experimental results show that the proposed coding scheme achieves superior R-D performances compared to the octree-based G-PCC, especially when applied to multiple frames of a point cloud video. The code is available at https://github.com/huzi96/NVFPCC/.
Learning to Predict on Octree for Scalable Point Cloud Geometry Coding
Sep 06, 2022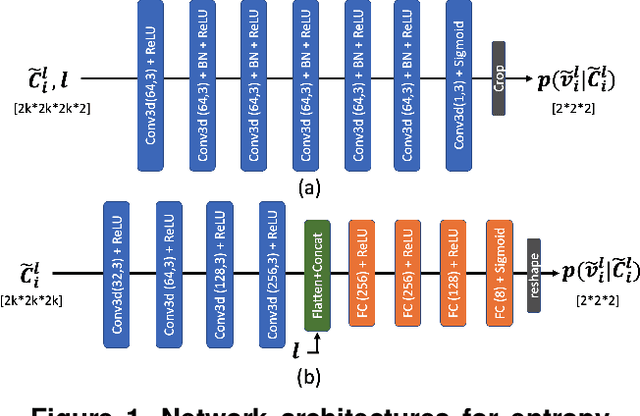
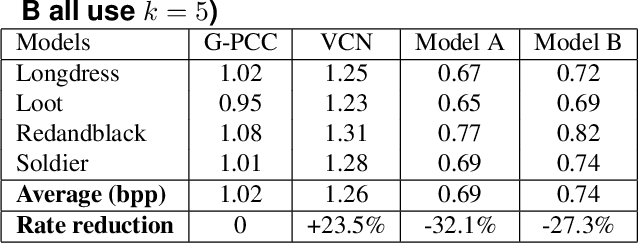
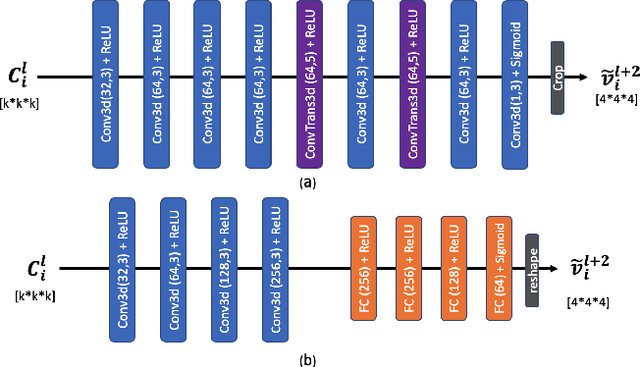
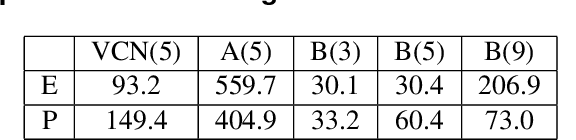
Octree-based point cloud representation and compression have been adopted by the MPEG G-PCC standard. However, it only uses handcrafted methods to predict the probability that a leaf node is non-empty, which is then used for entropy coding. We propose a novel approach for predicting such probabilities for geometry coding, which applies a denoising neural network to a "noisy" context cube that includes both neighboring decoded voxels as well as uncoded voxels. We further propose a convolution-based model to upsample the decoded point cloud at a coarse resolution on the decoder side. Integration of the two approaches significantly improves the rate-distortion performance for geometry coding compared to the original G-PCC standard and other baseline methods for dense point clouds. The proposed octree-based entropy coding approach is naturally scalable, which is desirable for dynamic rate adaptation in point cloud streaming systems.