 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
RegionCL: Can Simple Region Swapping Contribute to Contrastive Learning?
Nov 24, 2021
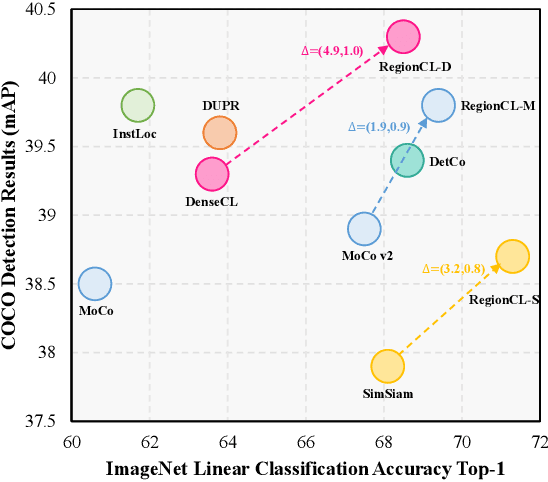
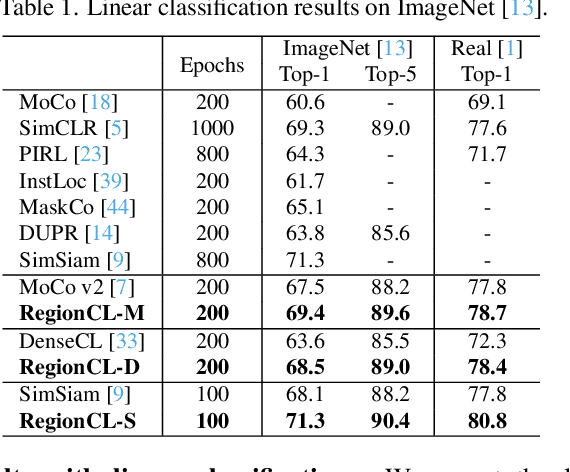
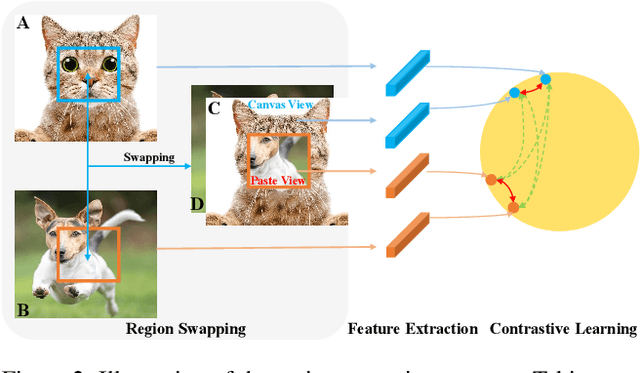
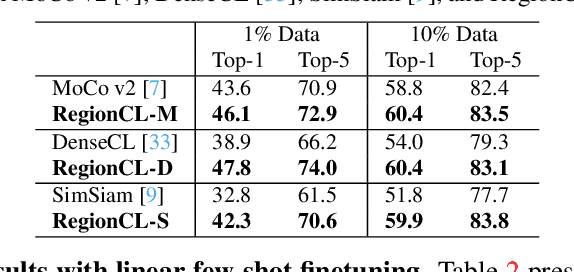
Self-supervised methods (SSL) have achieved significant success via maximizing the mutual information between two augmented views, where cropping is a popular augmentation technique. Cropped regions are widely used to construct positive pairs, while the left regions after cropping have rarely been explored in existing methods, although they together constitute the same image instance and both contribute to the description of the category. In this paper, we make the first attempt to demonstrate the importance of both regions in cropping from a complete perspective and propose a simple yet effective pretext task called Region Contrastive Learning (RegionCL). Specifically, given two different images, we randomly crop a region (called the paste view) from each image with the same size and swap them to compose two new images together with the left regions (called the canvas view), respectively. Then, contrastive pairs can be efficiently constructed according to the following simple criteria, i.e., each view is (1) positive with views augmented from the same original image and (2) negative with views augmented from other images. With minor modifications to popular SSL methods, RegionCL exploits those abundant pairs and helps the model distinguish the regions features from both canvas and paste views, therefore learning better visual representations. Experiments on ImageNet, MS COCO, and Cityscapes demonstrate that RegionCL improves MoCo v2, DenseCL, and SimSiam by large margins and achieves state-of-the-art performance on classification, detection, and segmentation tasks. The code will be available at https://github.com/Annbless/RegionCL.git.
SSMF: Shifting Seasonal Matrix Factorization
Oct 25, 2021

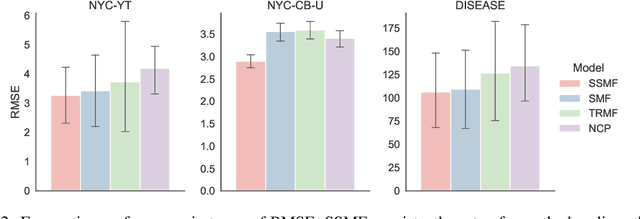
Given taxi-ride counts information between departure and destination locations, how can we forecast their future demands? In general, given a data stream of events with seasonal patterns that innovate over time, how can we effectively and efficiently forecast future events? In this paper, we propose Shifting Seasonal Matrix Factorization approach, namely SSMF, that can adaptively learn multiple seasonal patterns (called regimes), as well as switching between them. Our proposed method has the following properties: (a) it accurately forecasts future events by detecting regime shifts in seasonal patterns as the data stream evolves; (b) it works in an online setting, i.e., processes each observation in constant time and memory; (c) it effectively realizes regime shifts without human intervention by using a lossless data compression scheme. We demonstrate that our algorithm outperforms state-of-the-art baseline methods by accurately forecasting upcoming events on three real-world data streams.
Global and Local Alignment Networks for Unpaired Image-to-Image Translation
Nov 19, 2021
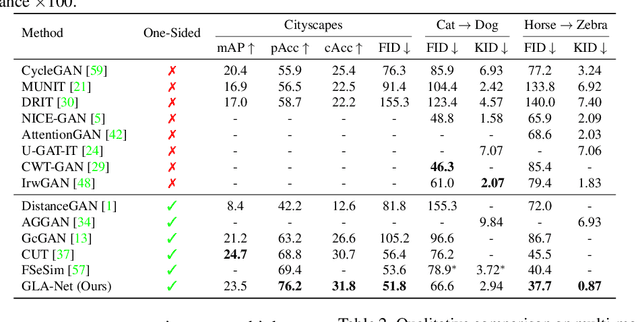
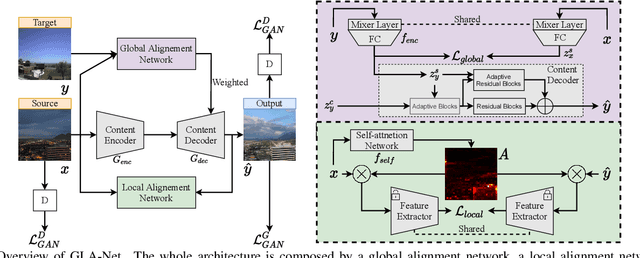
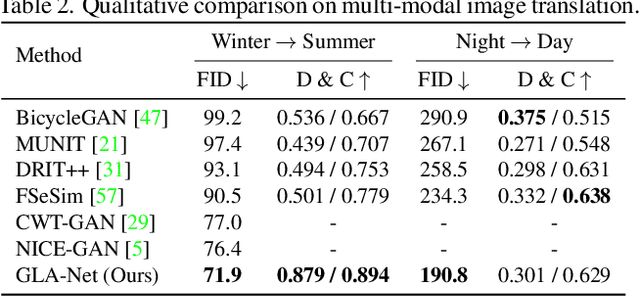
The goal of unpaired image-to-image translation is to produce an output image reflecting the target domain's style while keeping unrelated contents of the input source image unchanged. However, due to the lack of attention to the content change in existing methods, the semantic information from source images suffers from degradation during translation. In the paper, to address this issue, we introduce a novel approach, Global and Local Alignment Networks (GLA-Net). The global alignment network aims to transfer the input image from the source domain to the target domain. To effectively do so, we learn the parameters (mean and standard deviation) of multivariate Gaussian distributions as style features by using an MLP-Mixer based style encoder. To transfer the style more accurately, we employ an adaptive instance normalization layer in the encoder, with the parameters of the target multivariate Gaussian distribution as input. We also adopt regularization and likelihood losses to further reduce the domain gap and produce high-quality outputs. Additionally, we introduce a local alignment network, which employs a pretrained self-supervised model to produce an attention map via a novel local alignment loss, ensuring that the translation network focuses on relevant pixels. Extensive experiments conducted on five public datasets demonstrate that our method effectively generates sharper and more realistic images than existing approaches. Our code is available at https://github.com/ygjwd12345/GLANet.
An Emotional Analysis of False Information in Social Media and News Articles
Aug 26, 2019
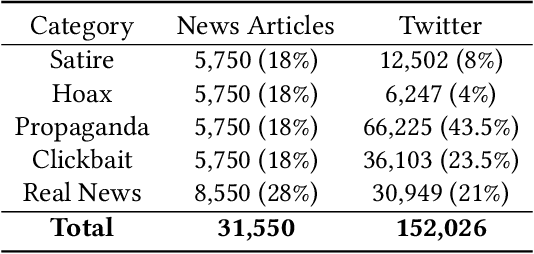
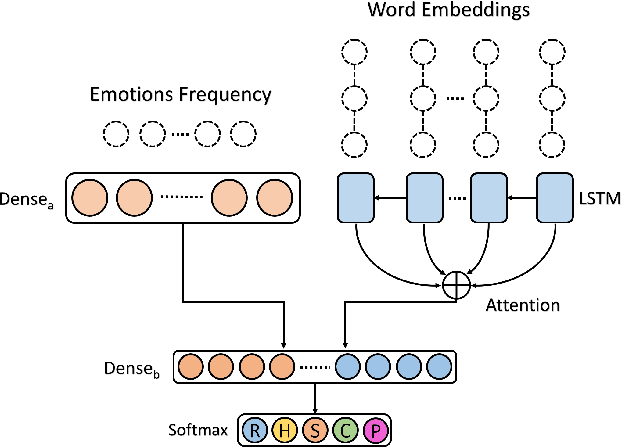
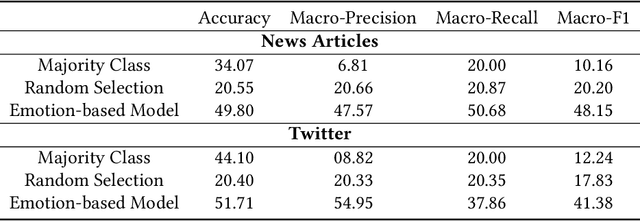
Fake news is risky since it has been created to manipulate the readers' opinions and beliefs. In this work, we compared the language of false news to the real one of real news from an emotional perspective, considering a set of false information types (propaganda, hoax, clickbait, and satire) from social media and online news articles sources. Our experiments showed that false information has different emotional patterns in each of its types, and emotions play a key role in deceiving the reader. Based on that, we proposed a LSTM neural network model that is emotionally-infused to detect false news.
Blending Anti-Aliasing into Vision Transformer
Oct 28, 2021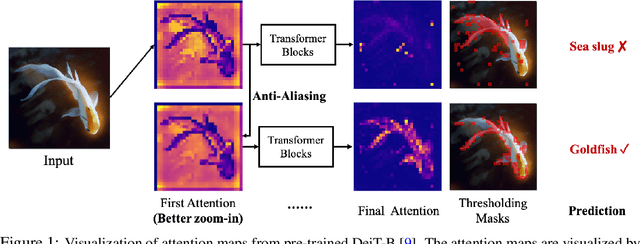
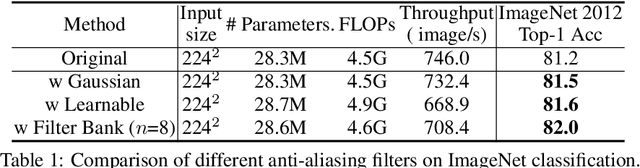

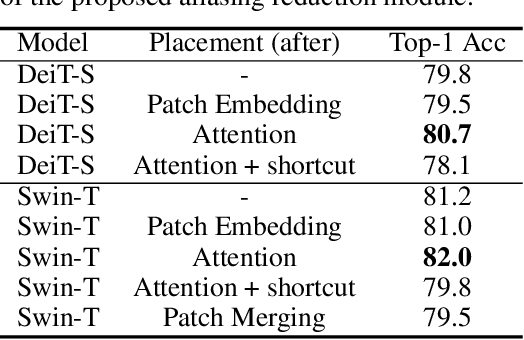
The transformer architectures, based on self-attention mechanism and convolution-free design, recently found superior performance and booming applications in computer vision. However, the discontinuous patch-wise tokenization process implicitly introduces jagged artifacts into attention maps, arising the traditional problem of aliasing for vision transformers. Aliasing effect occurs when discrete patterns are used to produce high frequency or continuous information, resulting in the indistinguishable distortions. Recent researches have found that modern convolution networks still suffer from this phenomenon. In this work, we analyze the uncharted problem of aliasing in vision transformer and explore to incorporate anti-aliasing properties. Specifically, we propose a plug-and-play Aliasing-Reduction Module(ARM) to alleviate the aforementioned issue. We investigate the effectiveness and generalization of the proposed method across multiple tasks and various vision transformer families. This lightweight design consistently attains a clear boost over several famous structures. Furthermore, our module also improves data efficiency and robustness of vision transformers.
Two ways towards combining Sequential Neural Network and Statistical Methods to Improve the Prediction of Time Series
Sep 30, 2021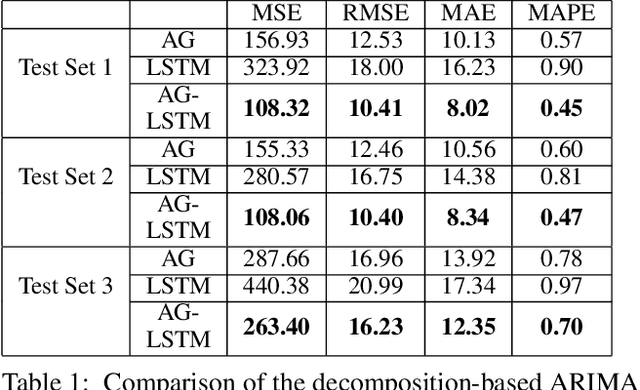
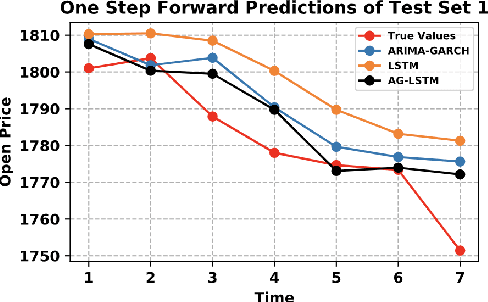
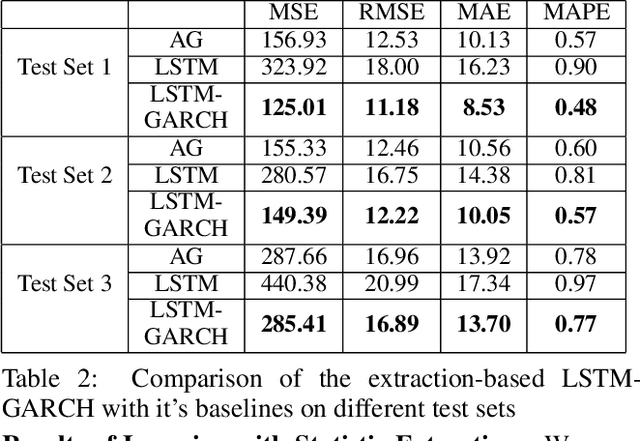
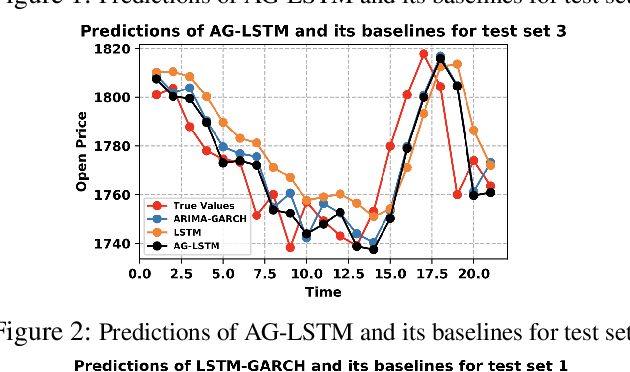
Statistic modeling and data-driven learning are the two vital fields that attract many attentions. Statistic models intend to capture and interpret the relationships among variables, while data-based learning attempt to extract information directly from the data without pre-processing through complex models. Given the extensive studies in both fields, a subtle issue is how to properly integrate data based methods with existing knowledge or models. In this paper, based on the time series data, we propose two different directions to integrate the two, a decomposition-based method and a method exploiting the statistic extraction of data features. The first one decomposes the data into linear stable, nonlinear stable and unstable parts, where suitable statistical models are used for the linear stable and nonlinear stable parts while the appropriate machine learning tools are used for the unstable parts. The second one applies statistic models to extract statistics features of data and feed them as additional inputs into the machine learning platform for training. The most critical and challenging thing is how to determine and extract the valuable information from mathematical or statistical models to boost the performance of machine learning algorithms. We evaluate the proposal using time series data with varying degrees of stability. Performance results show that both methods can outperform existing schemes that use models and learning separately, and the improvements can be over 60%. Both our proposed methods are promising in bridging the gap between model-based and data-driven schemes and integrating the two to provide an overall higher learning performance.
Data-Efficient Mutual Information Neural Estimator
May 24, 2019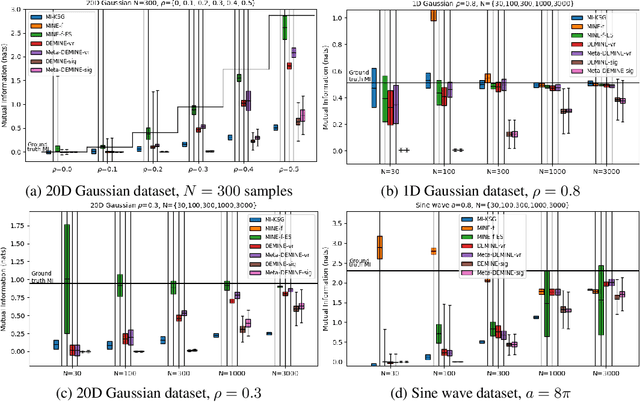
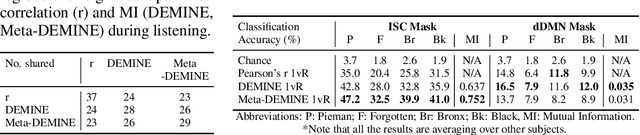
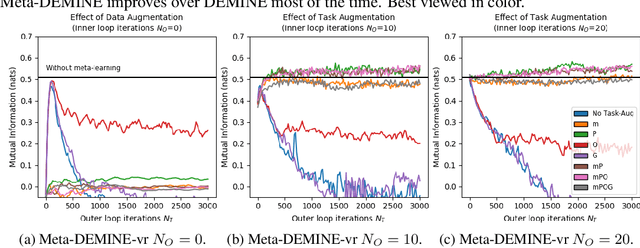
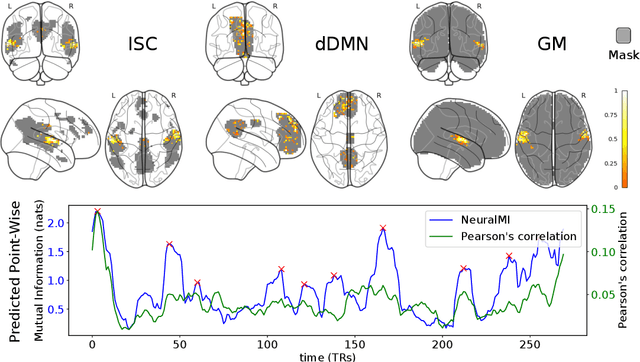
Measuring Mutual Information (MI) between high-dimensional, continuous, random variables from observed samples has wide theoretical and practical applications. Recent work, MINE (Belghazi et al. 2018), focused on estimating tight variational lower bounds of MI using neural networks, but assumed unlimited supply of samples to prevent overfitting. In real world applications, data is not always available at a surplus. In this work, we focus on improving data efficiency and propose a Data-Efficient MINE Estimator (DEMINE), by developing a relaxed predictive MI lower bound that can be estimated at higher data efficiency by orders of magnitudes. The predictive MI lower bound also enables us to develop a new meta-learning approach using task augmentation, Meta-DEMINE, to improve generalization of the network and further boost estimation accuracy empirically. With improved data-efficiency, our estimators enables statistical testing of dependency at practical dataset sizes. We demonstrate the effectiveness of our estimators on synthetic benchmarks and a real world fMRI data, with application of inter-subject correlation analysis.
Topic Model Supervised by Understanding Map
Oct 21, 2021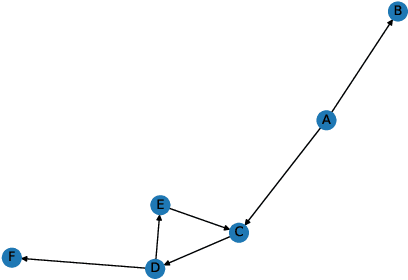

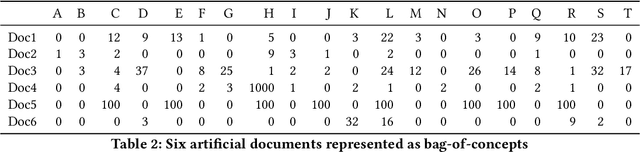
Inspired by the notion of Center of Mass in physics, an extension called Semantic Center of Mass (SCOM) is proposed, and used to discover the abstract "topic" of a document. The notion is under a framework model called Understanding Map Supervised Topic Model (UM-S-TM). The devise aim of UM-S-TM is to let both the document content and a semantic network -- specifically, Understanding Map -- play a role, in interpreting the meaning of a document. Based on different justifications, three possible methods are devised to discover the SCOM of a document. Some experiments on artificial documents and Understanding Maps are conducted to test their outcomes. In addition, its ability of vectorization of documents and capturing sequential information are tested. We also compared UM-S-TM with probabilistic topic models like Latent Dirichlet Allocation (LDA) and probabilistic Latent Semantic Analysis (pLSA).
Data privacy protection in microscopic image analysis for material data mining
Nov 09, 2021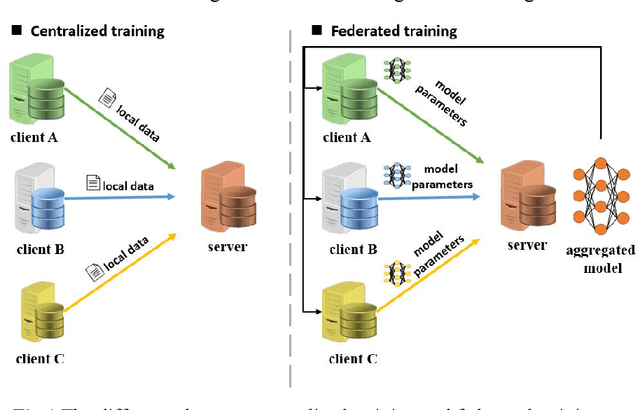
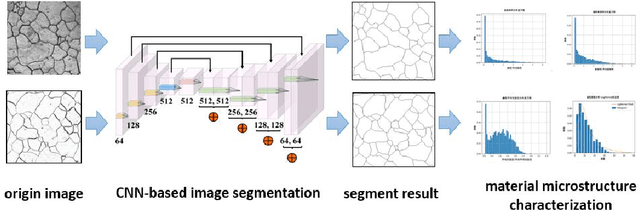
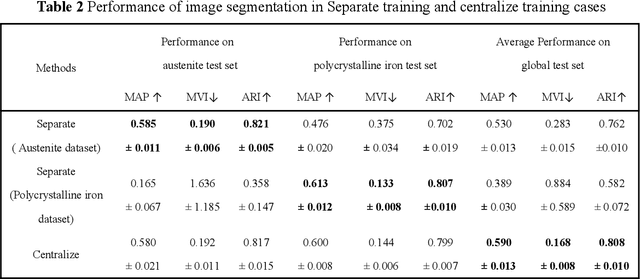
Recent progress in material data mining has been driven by high-capacity models trained on large datasets. However, collecting experimental data has been extremely costly owing to the amount of human effort and expertise required. Therefore, material researchers are often reluctant to easily disclose their private data, which leads to the problem of data island, and it is difficult to collect a large amount of data to train high-quality models. In this study, a material microstructure image feature extraction algorithm FedTransfer based on data privacy protection is proposed. The core contributions are as follows: 1) the federated learning algorithm is introduced into the polycrystalline microstructure image segmentation task to make full use of different user data to carry out machine learning, break the data island and improve the model generalization ability under the condition of ensuring the privacy and security of user data; 2) A data sharing strategy based on style transfer is proposed. By sharing style information of images that is not urgent for user confidentiality, it can reduce the performance penalty caused by the distribution difference of data among different users.
Unsupervised Keyphrase Extraction by Jointly Modeling Local and Global Context
Sep 15, 2021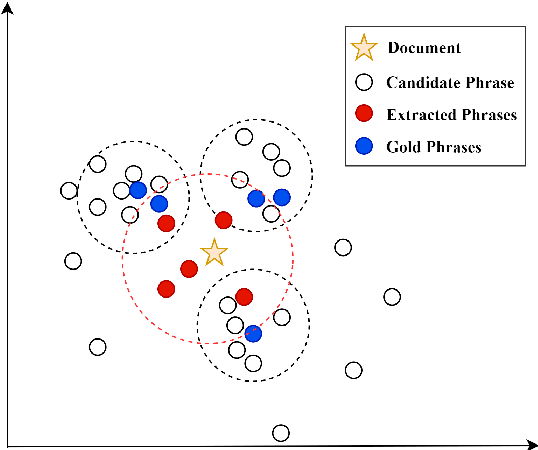
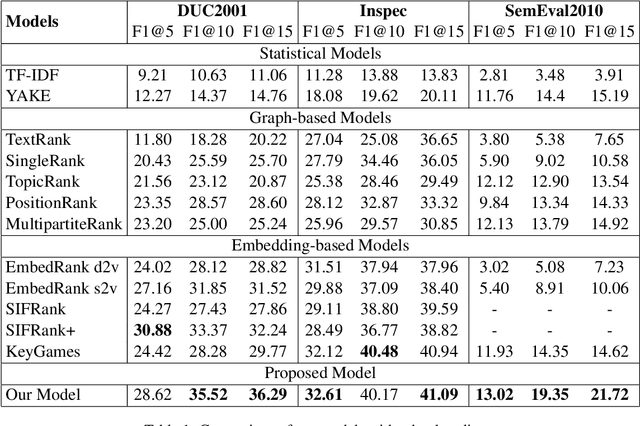
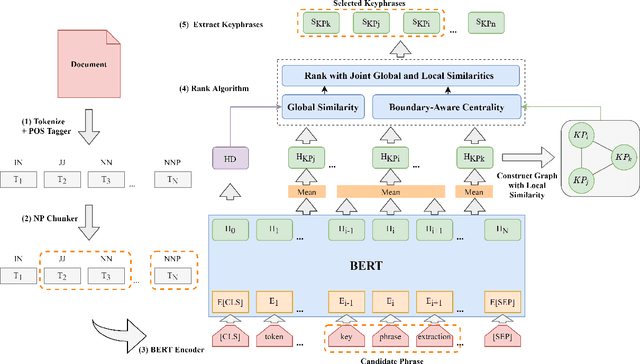

Embedding based methods are widely used for unsupervised keyphrase extraction (UKE) tasks. Generally, these methods simply calculate similarities between phrase embeddings and document embedding, which is insufficient to capture different context for a more effective UKE model. In this paper, we propose a novel method for UKE, where local and global contexts are jointly modeled. From a global view, we calculate the similarity between a certain phrase and the whole document in the vector space as transitional embedding based models do. In terms of the local view, we first build a graph structure based on the document where phrases are regarded as vertices and the edges are similarities between vertices. Then, we proposed a new centrality computation method to capture local salient information based on the graph structure. Finally, we further combine the modeling of global and local context for ranking. We evaluate our models on three public benchmarks (Inspec, DUC 2001, SemEval 2010) and compare with existing state-of-the-art models. The results show that our model outperforms most models while generalizing better on input documents with different domains and length. Additional ablation study shows that both the local and global information is crucial for unsupervised keyphrase extraction tasks.