 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMin-Max-Jump distance and its applications
Jan 15, 2023A new distance metric called Min-Max-Jump distance (MMJ distance) is proposed. Three applications of it are tested. MMJ-based K-means revises K-means with MMJ distance. MMJ-based Silhouette coefficient revises Silhouette coefficient with MMJ distance. We also tested the Clustering with Neural Network and Index (CNNI) model with MMJ-based Silhouette coefficient. In the last application, we tested using Min-Max-Jump distance for predicting labels of new points, after a clustering analysis of data. Result shows Min-Max-Jump distance achieves good performances in all the three proposed applications.
Clustering with Neural Network and Index
Dec 05, 2022A new model called Clustering with Neural Network and Index (CNNI) is introduced. CNNI uses a Neural Network to cluster data points. Training of the Neural Network mimics supervised learning, with an internal clustering evaluation index acting as the loss function. An experiment is conducted to test the feasibility of the new model, and compared with results of other clustering models like K-means and Gaussian Mixture Model (GMM).
A New Index for Clustering Evaluation Based on Density Estimation
Jul 11, 2022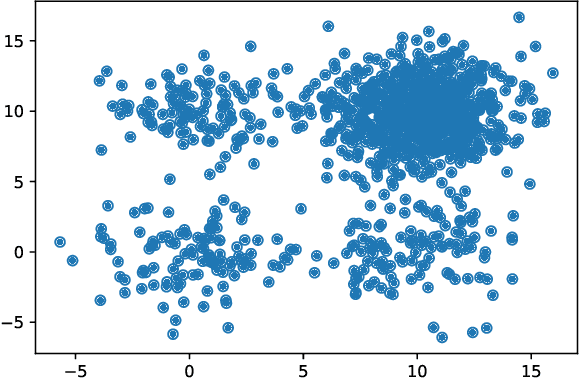

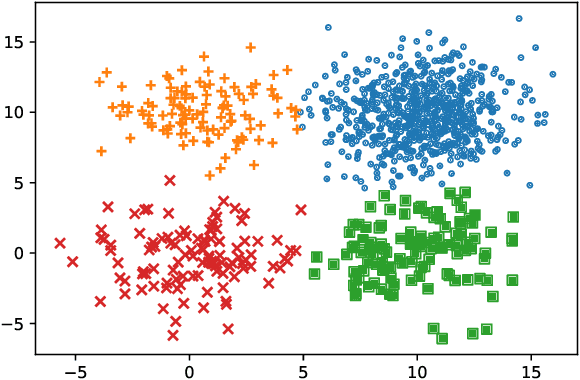
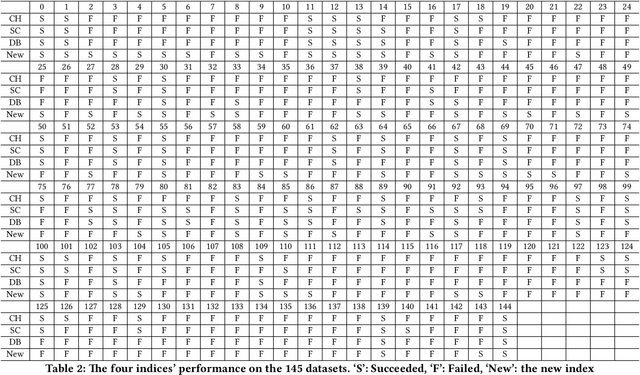
A new index for internal evaluation of clustering is introduced. The index is defined as a mixture of two sub-indices. The first sub-index $ I_a $ is called the Ambiguous Index; the second sub-index $ I_s $ is called the Similarity Index. Calculation of the two sub-indices is based on density estimation to each cluster of a partition of the data. An experiment is conducted to test the performance of the new index, and compared with three popular internal clustering evaluation indices -- Calinski-Harabasz index, Silhouette coefficient, and Davies-Bouldin index, on a set of 145 datasets. The result shows the new index improves the three popular indices by 59%, 34%, and 74%, correspondingly.
Topic Model Supervised by Understanding Map
Oct 21, 2021

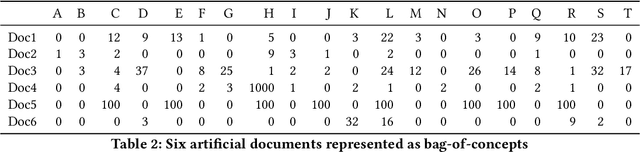
Inspired by the notion of Center of Mass in physics, an extension called Semantic Center of Mass (SCOM) is proposed, and used to discover the abstract "topic" of a document. The notion is under a framework model called Understanding Map Supervised Topic Model (UM-S-TM). The devise aim of UM-S-TM is to let both the document content and a semantic network -- specifically, Understanding Map -- play a role, in interpreting the meaning of a document. Based on different justifications, three possible methods are devised to discover the SCOM of a document. Some experiments on artificial documents and Understanding Maps are conducted to test their outcomes. In addition, its ability of vectorization of documents and capturing sequential information are tested. We also compared UM-S-TM with probabilistic topic models like Latent Dirichlet Allocation (LDA) and probabilistic Latent Semantic Analysis (pLSA).