 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegionCL: Can Simple Region Swapping Contribute to Contrastive Learning?
Paper and Code
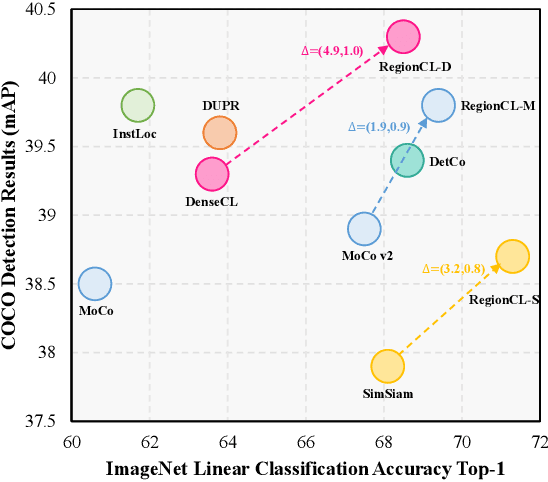
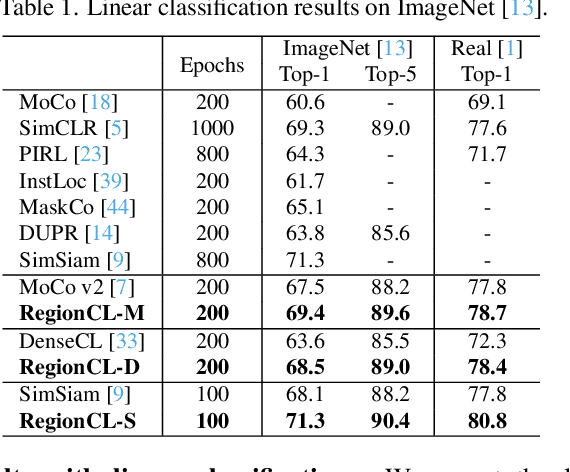
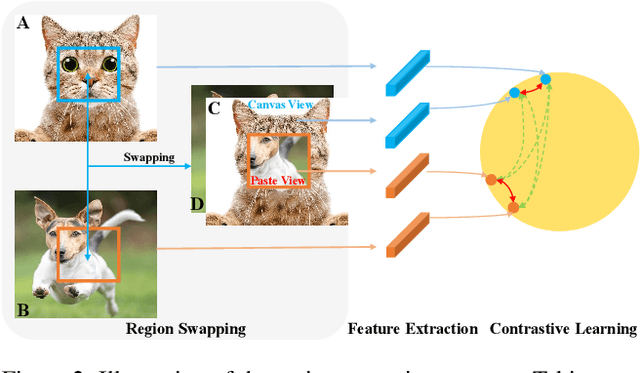
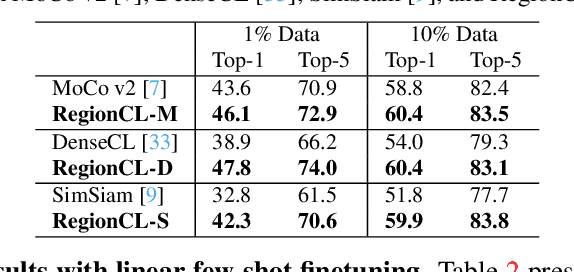
Self-supervised methods (SSL) have achieved significant success via maximizing the mutual information between two augmented views, where cropping is a popular augmentation technique. Cropped regions are widely used to construct positive pairs, while the left regions after cropping have rarely been explored in existing methods, although they together constitute the same image instance and both contribute to the description of the category. In this paper, we make the first attempt to demonstrate the importance of both regions in cropping from a complete perspective and propose a simple yet effective pretext task called Region Contrastive Learning (RegionCL). Specifically, given two different images, we randomly crop a region (called the paste view) from each image with the same size and swap them to compose two new images together with the left regions (called the canvas view), respectively. Then, contrastive pairs can be efficiently constructed according to the following simple criteria, i.e., each view is (1) positive with views augmented from the same original image and (2) negative with views augmented from other images. With minor modifications to popular SSL methods, RegionCL exploits those abundant pairs and helps the model distinguish the regions features from both canvas and paste views, therefore learning better visual representations. Experiments on ImageNet, MS COCO, and Cityscapes demonstrate that RegionCL improves MoCo v2, DenseCL, and SimSiam by large margins and achieves state-of-the-art performance on classification, detection, and segmentation tasks. The code will be available at https://github.com/Annbless/RegionCL.git.