 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ZUPT Aided GNSS Factor Graph with Inertial Navigation Integration for Wheeled Robots
Dec 14, 2021
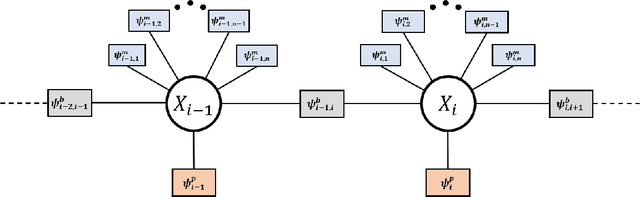
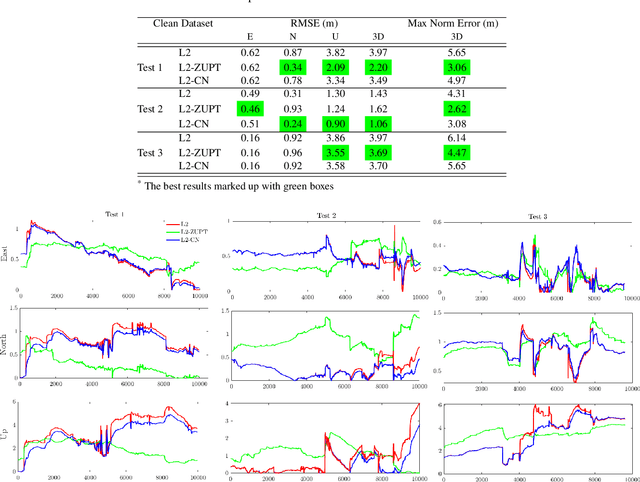
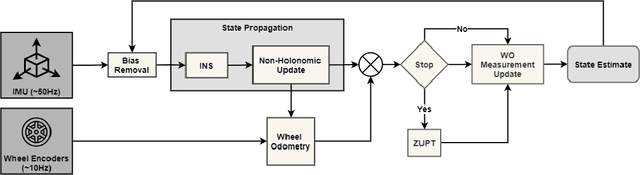
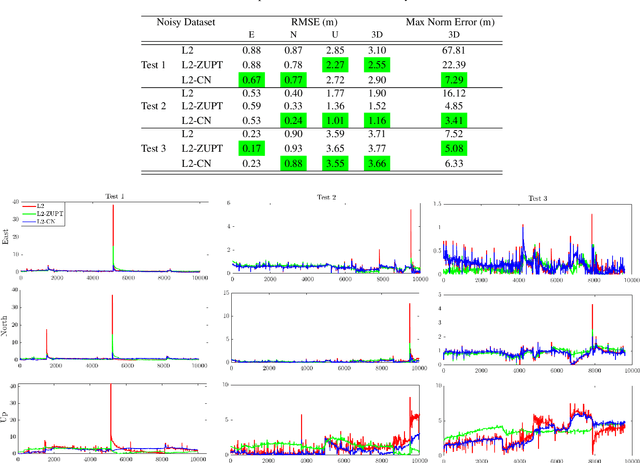
In this work, we demonstrate the importance of zero velocity information for global navigation satellite system (GNSS) based navigation. The effectiveness of using the zero velocity information with zero velocity update (ZUPT) for inertial navigation applications have been shown in the literature. Here we leverage this information and add it as a position constraint in a GNSS factor graph. We also compare its performance to a GNSS/inertial navigation system (INS) coupled factor graph. We tested our ZUPT aided factor graph method on three datasets and compared it with the GNSS-only factor graph.
Does Yoga Make You Happy? Analyzing Twitter User Happiness using Textual and Temporal Information
Dec 05, 2020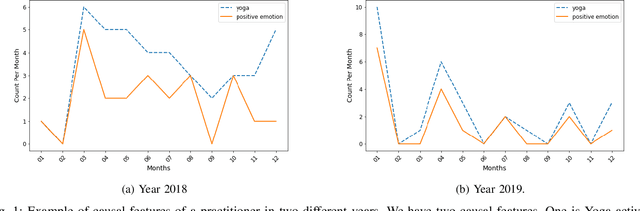
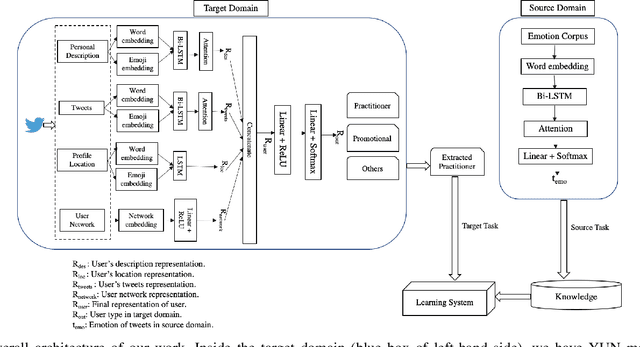
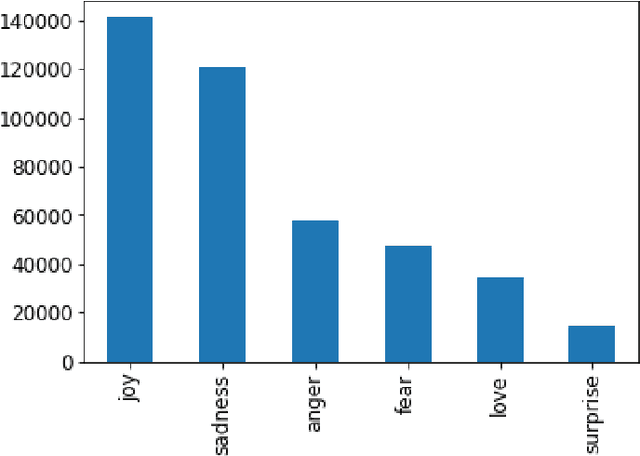
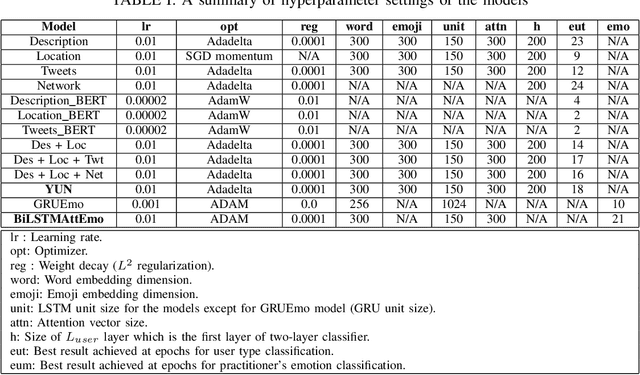
Although yoga is a multi-component practice to hone the body and mind and be known to reduce anxiety and depression, there is still a gap in understanding people's emotional state related to yoga in social media. In this study, we investigate the causal relationship between practicing yoga and being happy by incorporating textual and temporal information of users using Granger causality. To find out causal features from the text, we measure two variables (i) Yoga activity level based on content analysis and (ii) Happiness level based on emotional state. To understand users' yoga activity, we propose a joint embedding model based on the fusion of neural networks with attention mechanism by leveraging users' social and textual information. For measuring the emotional state of yoga users (target domain), we suggest a transfer learning approach to transfer knowledge from an attention-based neural network model trained on a source domain. Our experiment on Twitter dataset demonstrates that there are 1447 users where "yoga Granger-causes happiness".
Variational Quantum Policy Gradients with an Application to Quantum Control
Mar 20, 2022

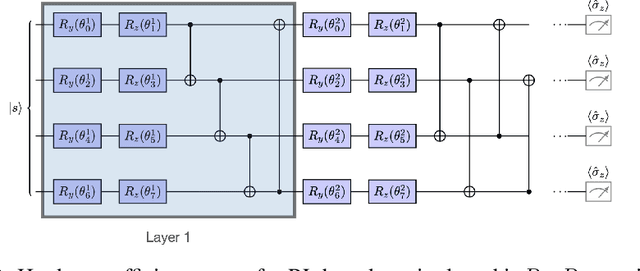

Quantum Machine Learning models are composed by Variational Quantum Circuits (VQCs) in a very natural way. There are already some empirical results proving that such models provide an advantage in supervised/unsupervised learning tasks. However, when applied to Reinforcement Learning (RL), less is known. In this work, we consider Policy Gradients using a hardware-efficient ansatz. We prove that the complexity of obtaining an {\epsilon}-approximation of the gradient using quantum hardware scales only logarithmically with the number of parameters, considering the number of quantum circuits executions. We test the performance of such models in benchmarking environments and verify empirically that such quantum models outperform typical classical neural networks used in those environments, using a fraction of the number of parameters. Moreover, we propose the utilization of the Fisher Information spectrum to show that the quantum model is less prone to barren plateaus than its classical counterpart. As a different use case, we consider the application of such variational quantum models to the problem of quantum control and show its feasibility in the quantum-quantum domain.
TONet: Tone-Octave Network for Singing Melody Extraction from Polyphonic Music
Feb 02, 2022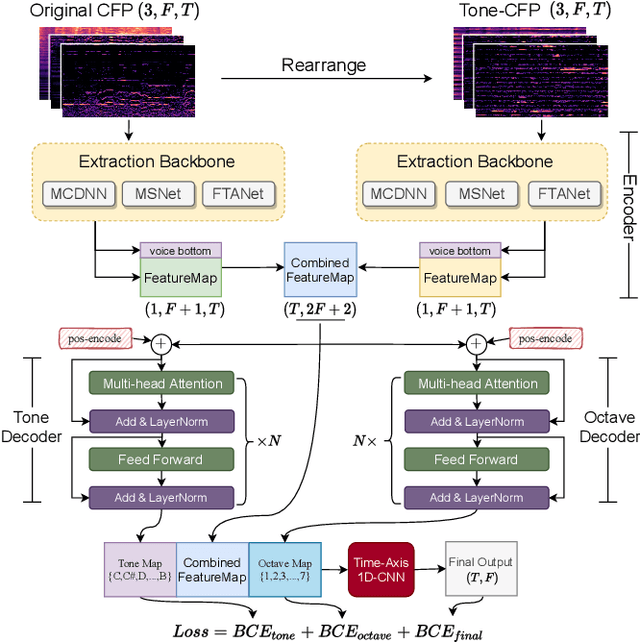
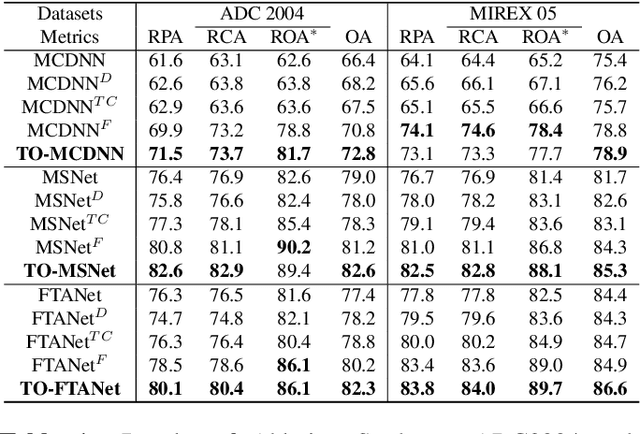
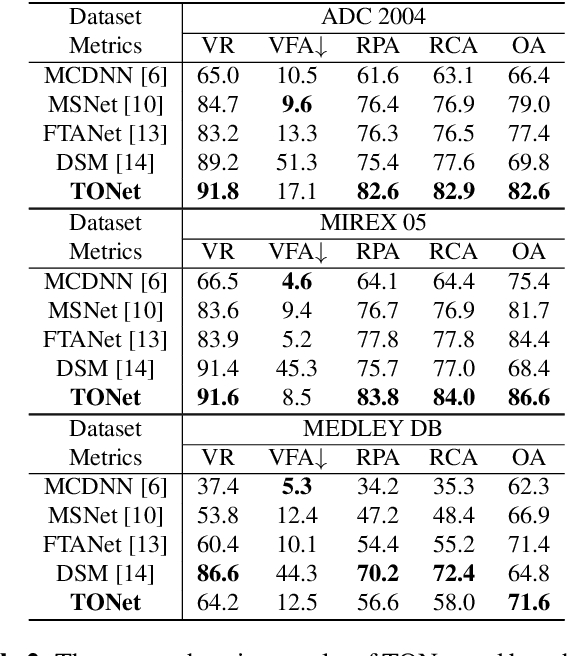
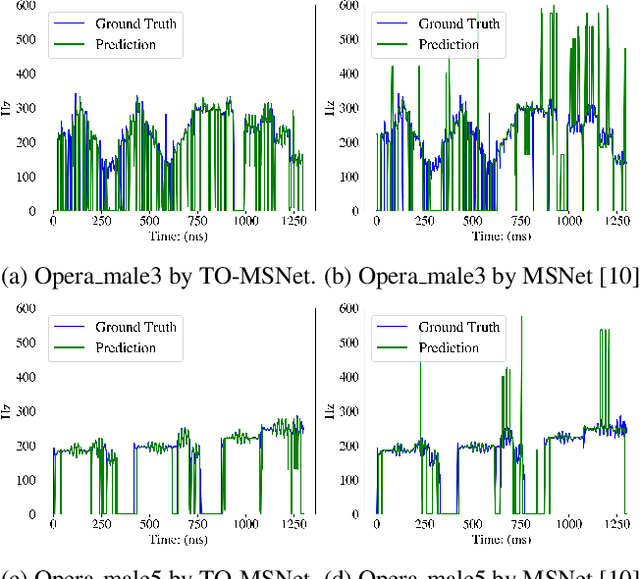
Singing melody extraction is an important problem in the field of music information retrieval. Existing methods typically rely on frequency-domain representations to estimate the sung frequencies. However, this design does not lead to human-level performance in the perception of melody information for both tone (pitch-class) and octave. In this paper, we propose TONet, a plug-and-play model that improves both tone and octave perceptions by leveraging a novel input representation and a novel network architecture. First, we present an improved input representation, the Tone-CFP, that explicitly groups harmonics via a rearrangement of frequency-bins. Second, we introduce an encoder-decoder architecture that is designed to obtain a salience feature map, a tone feature map, and an octave feature map. Third, we propose a tone-octave fusion mechanism to improve the final salience feature map. Experiments are done to verify the capability of TONet with various baseline backbone models. Our results show that tone-octave fusion with Tone-CFP can significantly improve the singing voice extraction performance across various datasets -- with substantial gains in octave and tone accuracy.
Exploring the use of Time-Dependent Cross-Network Information for Personalized Recommendations
Aug 25, 2020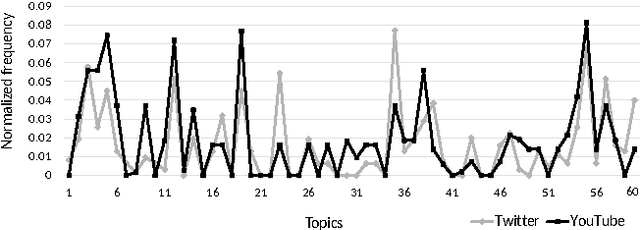
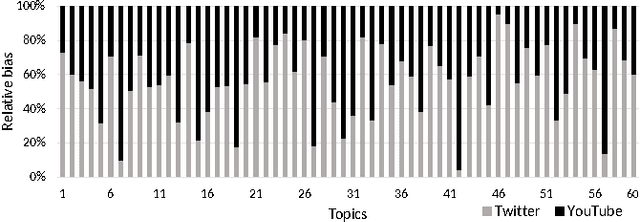

The overwhelming volume and complexity of information in online applications make recommendation essential for users to find information of interest. However, two major limitations that coexist in real world applications (1) incomplete user profiles, and (2) the dynamic nature of user preferences continue to degrade recommender quality in aspects such as timeliness, accuracy, diversity and novelty. To address both the above limitations in a single solution, we propose a novel cross-network time aware recommender solution. The solution first learns historical user models in the target network by aggregating user preferences from multiple source networks. Second, user level time aware latent factors are learnt to develop current user models from the historical models and conduct timely recommendations. We illustrate our solution by using auxiliary information from the Twitter source network to improve recommendations for the YouTube target network. Experiments conducted using multiple time aware and cross-network baselines under different time granularities show that the proposed solution achieves superior performance in terms of accuracy, novelty and diversity.
Privacy-preserving Generative Framework Against Membership Inference Attacks
Feb 11, 2022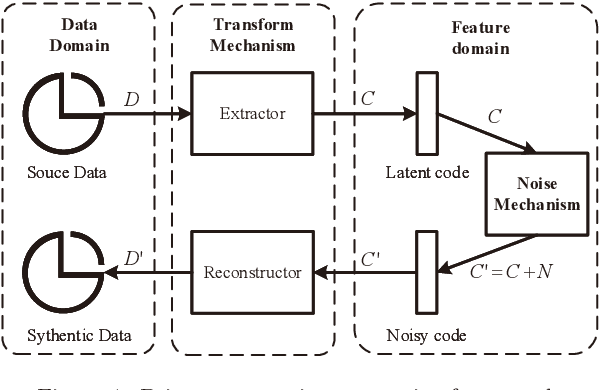
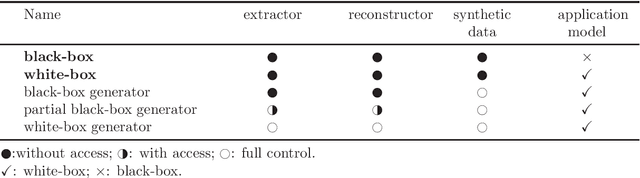
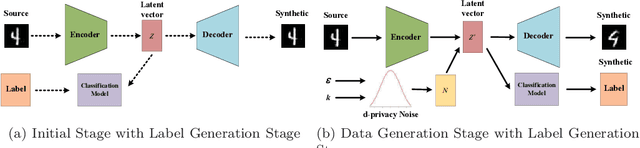

Artificial intelligence and machine learning have been integrated into all aspects of our lives and the privacy of personal data has attracted more and more attention. Since the generation of the model needs to extract the effective information of the training data, the model has the risk of leaking the privacy of the training data. Membership inference attacks can measure the model leakage of source data to a certain degree. In this paper, we design a privacy-preserving generative framework against membership inference attacks, through the information extraction and data generation capabilities of the generative model variational autoencoder (VAE) to generate synthetic data that meets the needs of differential privacy. Instead of adding noise to the model output or tampering with the training process of the target model, we directly process the original data. We first map the source data to the latent space through the VAE model to get the latent code, then perform noise process satisfying metric privacy on the latent code, and finally use the VAE model to reconstruct the synthetic data. Our experimental evaluation demonstrates that the machine learning model trained with newly generated synthetic data can effectively resist membership inference attacks and still maintain high utility.
Automated Algorithm Selection: from Feature-Based to Feature-Free Approaches
Mar 24, 2022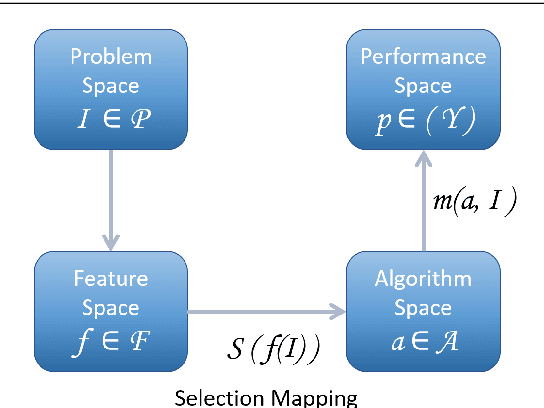
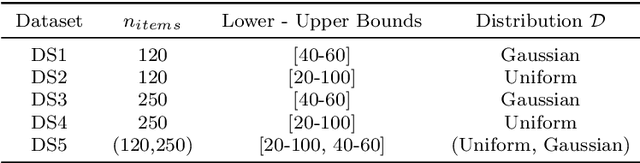

We propose a novel technique for algorithm-selection, applicable to optimisation domains in which there is implicit sequential information encapsulated in the data, e.g., in online bin-packing. Specifically we train two types of recurrent neural networks to predict a packing heuristic in online bin-packing, selecting from four well-known heuristics. As input, the RNN methods only use the sequence of item-sizes. This contrasts to typical approaches to algorithm-selection which require a model to be trained using domain-specific instance features that need to be first derived from the input data. The RNN approaches are shown to be capable of achieving within 5% of the oracle performance on between 80.88% to 97.63% of the instances, depending on the dataset. They are also shown to outperform classical machine learning models trained using derived features. Finally, we hypothesise that the proposed methods perform well when the instances exhibit some implicit structure that results in discriminatory performance with respect to a set of heuristics. We test this hypothesis by generating fourteen new datasets with increasing levels of structure, and show that there is a critical threshold of structure required before algorithm-selection delivers benefit.
Reading-strategy Inspired Visual Representation Learning for Text-to-Video Retrieval
Jan 23, 2022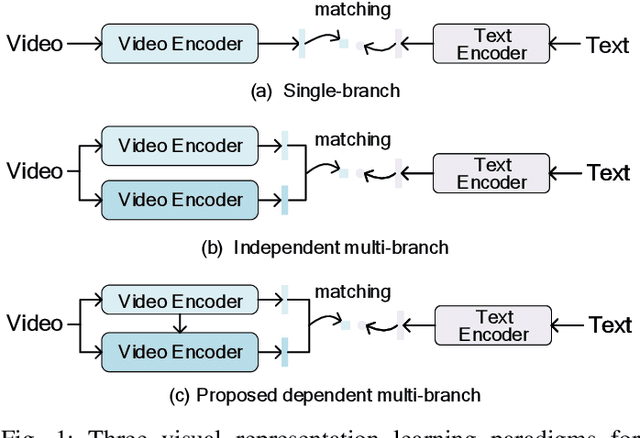
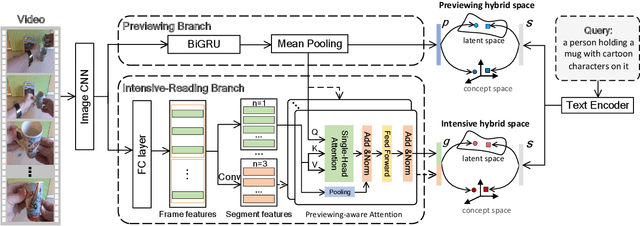
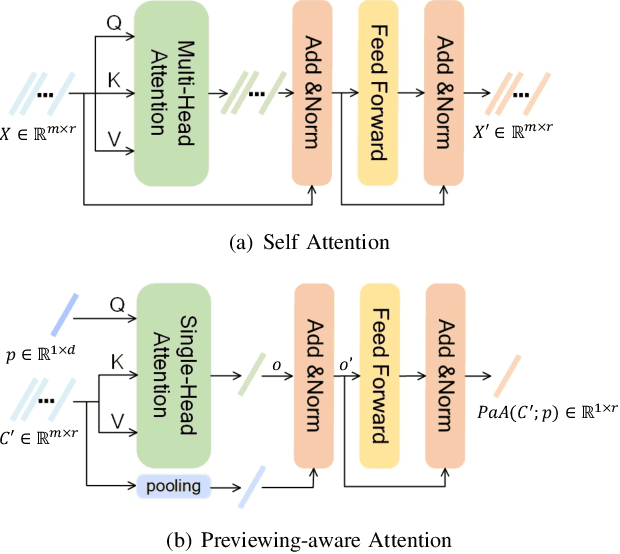
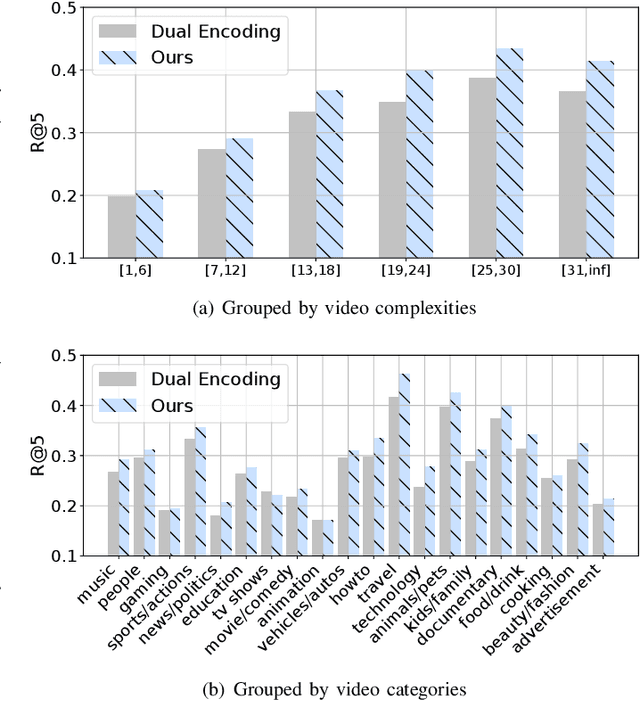
This paper aims for the task of text-to-video retrieval, where given a query in the form of a natural-language sentence, it is asked to retrieve videos which are semantically relevant to the given query, from a great number of unlabeled videos. The success of this task depends on cross-modal representation learning that projects both videos and sentences into common spaces for semantic similarity computation. In this work, we concentrate on video representation learning, an essential component for text-to-video retrieval. Inspired by the reading strategy of humans, we propose a Reading-strategy Inspired Visual Representation Learning (RIVRL) to represent videos, which consists of two branches: a previewing branch and an intensive-reading branch. The previewing branch is designed to briefly capture the overview information of videos, while the intensive-reading branch is designed to obtain more in-depth information. Moreover, the intensive-reading branch is aware of the video overview captured by the previewing branch. Such holistic information is found to be useful for the intensive-reading branch to extract more fine-grained features. Extensive experiments on three datasets are conducted, where our model RIVRL achieves a new state-of-the-art on TGIF and VATEX. Moreover, on MSR-VTT, our model using two video features shows comparable performance to the state-of-the-art using seven video features and even outperforms models pre-trained on the large-scale HowTo100M dataset.
PICASSO: Unleashing the Potential of GPU-centric Training for Wide-and-deep Recommender Systems
Apr 11, 2022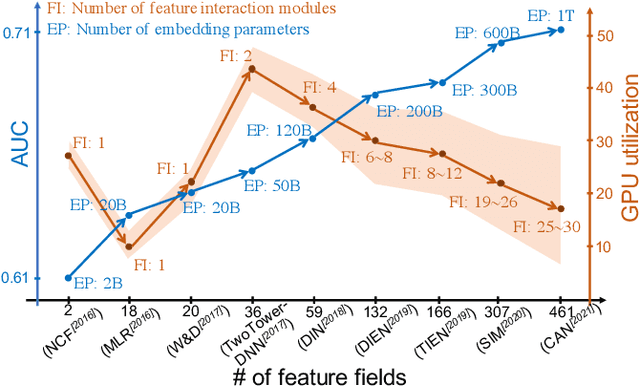

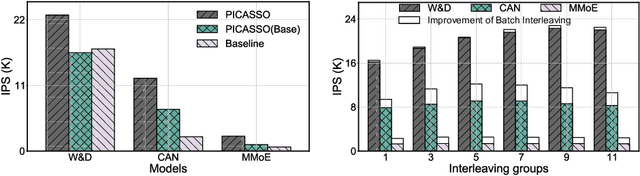
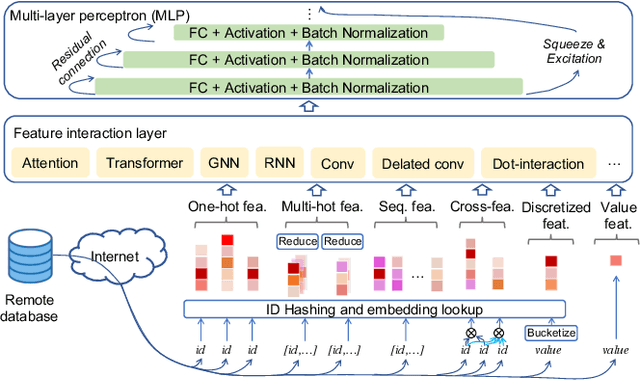
The development of personalized recommendation has significantly improved the accuracy of information matching and the revenue of e-commerce platforms. Recently, it has 2 trends: 1) recommender systems must be trained timely to cope with ever-growing new products and ever-changing user interests from online marketing and social network; 2) SOTA recommendation models introduce DNN modules to improve prediction accuracy. Traditional CPU-based recommender systems cannot meet these two trends, and GPU- centric training has become a trending approach. However, we observe that GPU devices in training recommender systems are underutilized, and they cannot attain an expected throughput improvement as what it has achieved in CV and NLP areas. This issue can be explained by two characteristics of these recommendation models: First, they contain up to a thousand input feature fields, introducing fragmentary and memory-intensive operations; Second, the multiple constituent feature interaction submodules introduce substantial small-sized compute kernels. To remove this roadblock to the development of recommender systems, we propose a novel framework named PICASSO to accelerate the training of recommendation models on commodity hardware. Specifically, we conduct a systematic analysis to reveal the bottlenecks encountered in training recommendation models. We leverage the model structure and data distribution to unleash the potential of hardware through our packing, interleaving, and caching optimization. Experiments show that PICASSO increases the hardware utilization by an order of magnitude on the basis of SOTA baselines and brings up to 6x throughput improvement for a variety of industrial recommendation models. Using the same hardware budget in production, PICASSO on average shortens the walltime of daily training tasks by 7 hours, significantly reducing the delay of continuous delivery.
POETREE: Interpretable Policy Learning with Adaptive Decision Trees
Mar 15, 2022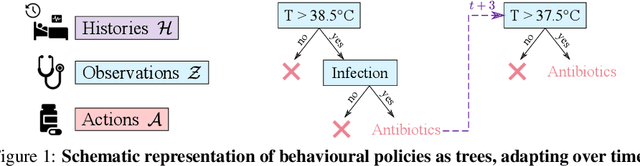

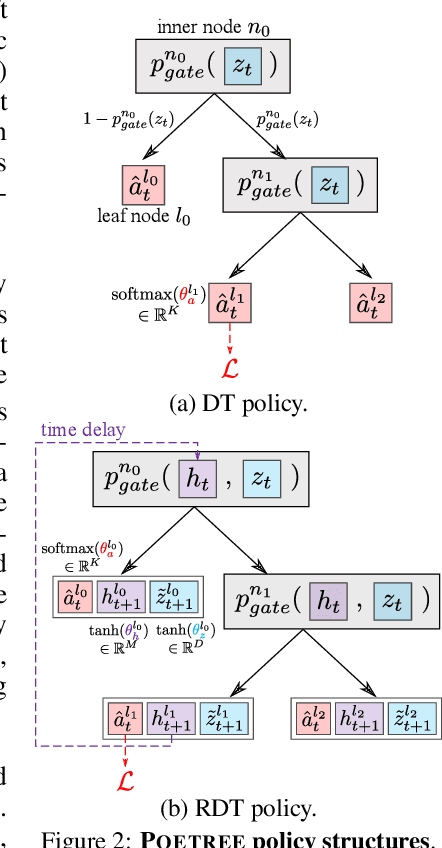
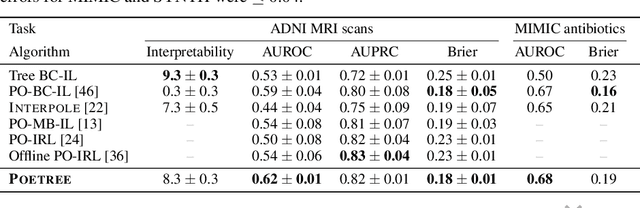
Building models of human decision-making from observed behaviour is critical to better understand, diagnose and support real-world policies such as clinical care. As established policy learning approaches remain focused on imitation performance, they fall short of explaining the demonstrated decision-making process. Policy Extraction through decision Trees (POETREE) is a novel framework for interpretable policy learning, compatible with fully-offline and partially-observable clinical decision environments -- and builds probabilistic tree policies determining physician actions based on patients' observations and medical history. Fully-differentiable tree architectures are grown incrementally during optimization to adapt their complexity to the modelling task, and learn a representation of patient history through recurrence, resulting in decision tree policies that adapt over time with patient information. This policy learning method outperforms the state-of-the-art on real and synthetic medical datasets, both in terms of understanding, quantifying and evaluating observed behaviour as well as in accurately replicating it -- with potential to improve future decision support systems.