 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeriving Representative Structure from Music Corpora
Feb 21, 2025Western music is an innately hierarchical system of interacting levels of structure, from fine-grained melody to high-level form. In order to analyze music compositions holistically and at multiple granularities, we propose a unified, hierarchical meta-representation of musical structure called the structural temporal graph (STG). For a single piece, the STG is a data structure that defines a hierarchy of progressively finer structural musical features and the temporal relationships between them. We use the STG to enable a novel approach for deriving a representative structural summary of a music corpus, which we formalize as a dually NP-hard combinatorial optimization problem extending the Generalized Median Graph problem. Our approach first applies simulated annealing to develop a measure of structural distance between two music pieces rooted in graph isomorphism. Our approach then combines the formal guarantees of SMT solvers with nested simulated annealing over structural distances to produce a structurally sound, representative centroid STG for an entire corpus of STGs from individual pieces. To evaluate our approach, we conduct experiments verifying that structural distance accurately differentiates between music pieces, and that derived centroids accurately structurally characterize their corpora.
Jam-ALT: A Formatting-Aware Lyrics Transcription Benchmark
Nov 23, 2023



Current automatic lyrics transcription (ALT) benchmarks focus exclusively on word content and ignore the finer nuances of written lyrics including formatting and punctuation, which leads to a potential misalignment with the creative products of musicians and songwriters as well as listeners' experiences. For example, line breaks are important in conveying information about rhythm, emotional emphasis, rhyme, and high-level structure. To address this issue, we introduce Jam-ALT, a new lyrics transcription benchmark based on the JamendoLyrics dataset. Our contribution is twofold. Firstly, a complete revision of the transcripts, geared specifically towards ALT evaluation by following a newly created annotation guide that unifies the music industry's guidelines, covering aspects such as punctuation, line breaks, spelling, background vocals, and non-word sounds. Secondly, a suite of evaluation metrics designed, unlike the traditional word error rate, to capture such phenomena. We hope that the proposed benchmark contributes to the ALT task, enabling more precise and reliable assessments of transcription systems and enhancing the user experience in lyrics applications such as subtitle renderings for live captioning or karaoke.
TONet: Tone-Octave Network for Singing Melody Extraction from Polyphonic Music
Feb 02, 2022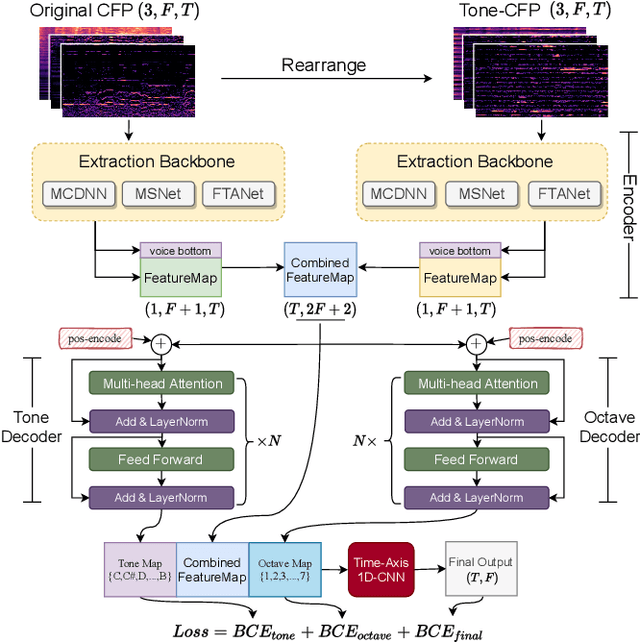
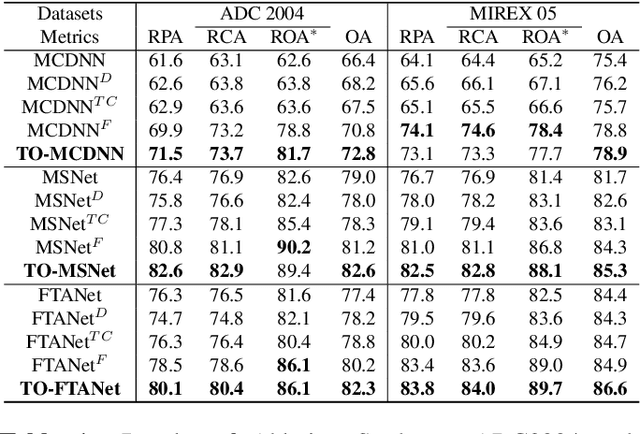
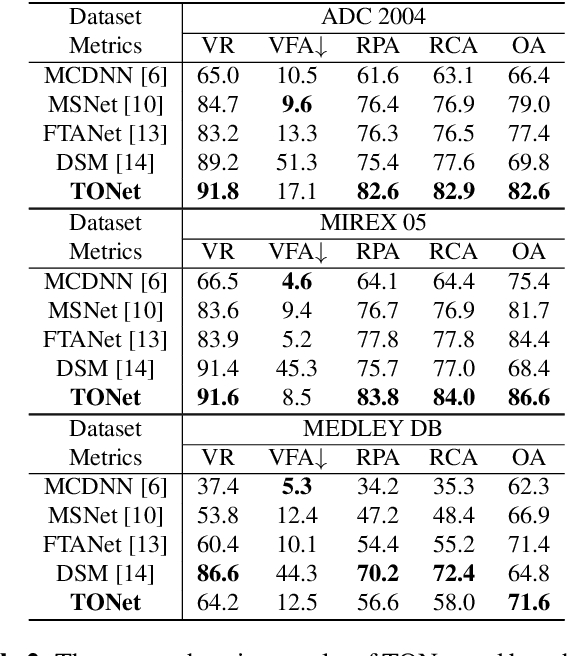
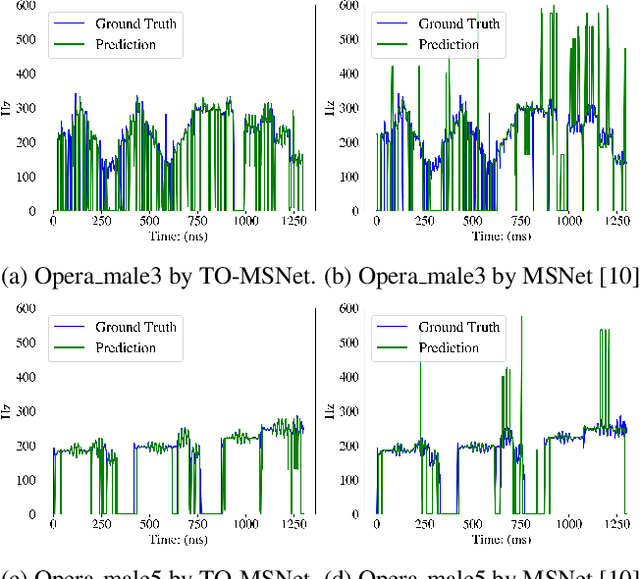
Singing melody extraction is an important problem in the field of music information retrieval. Existing methods typically rely on frequency-domain representations to estimate the sung frequencies. However, this design does not lead to human-level performance in the perception of melody information for both tone (pitch-class) and octave. In this paper, we propose TONet, a plug-and-play model that improves both tone and octave perceptions by leveraging a novel input representation and a novel network architecture. First, we present an improved input representation, the Tone-CFP, that explicitly groups harmonics via a rearrangement of frequency-bins. Second, we introduce an encoder-decoder architecture that is designed to obtain a salience feature map, a tone feature map, and an octave feature map. Third, we propose a tone-octave fusion mechanism to improve the final salience feature map. Experiments are done to verify the capability of TONet with various baseline backbone models. Our results show that tone-octave fusion with Tone-CFP can significantly improve the singing voice extraction performance across various datasets -- with substantial gains in octave and tone accuracy.
Towards Cross-Cultural Analysis using Music Information Dynamics
Nov 24, 2021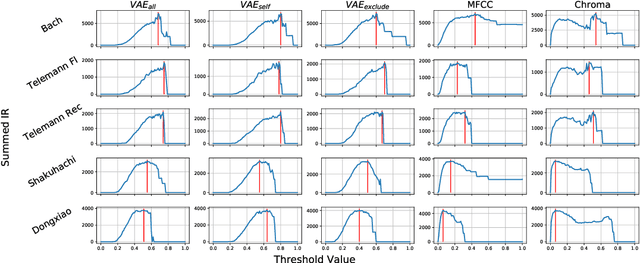
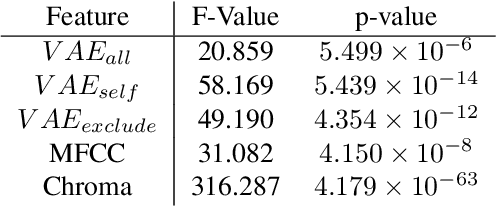
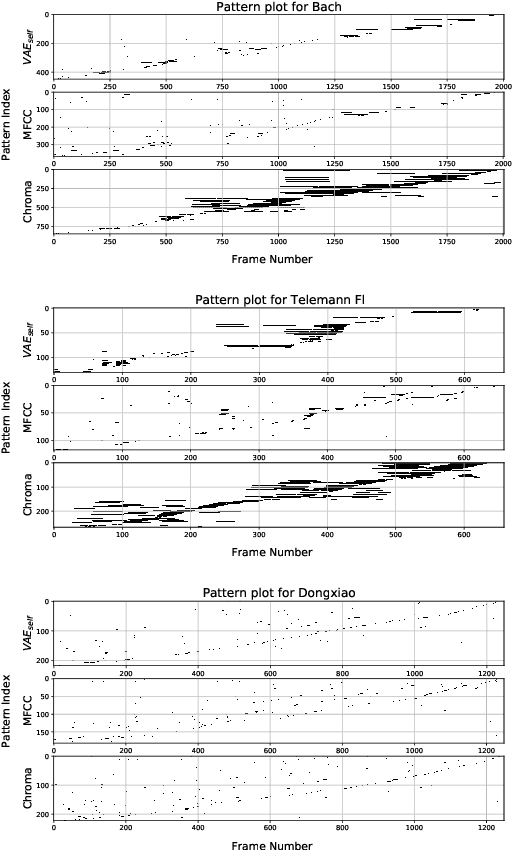
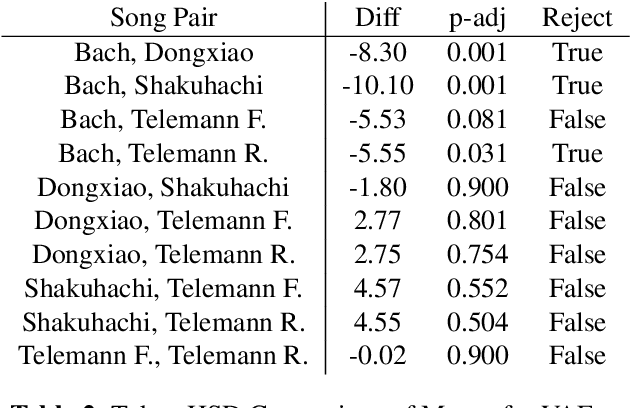
A music piece is both comprehended hierarchically, from sonic events to melodies, and sequentially, in the form of repetition and variation. Music from different cultures establish different aesthetics by having different style conventions on these two aspects. We propose a framework that could be used to quantitatively compare music from different cultures by looking at these two aspects. The framework is based on an Music Information Dynamics model, a Variable Markov Oracle (VMO), and is extended with a variational representation learning of audio. A variational autoencoder (VAE) is trained to map audio fragments into a latent representation. The latent representation is fed into a VMO. The VMO then learns a clustering of the latent representation via a threshold that maximizes the information rate of the quantized latent representation sequence. This threshold effectively controls the sensibility of the predictive step to acoustic changes, which determines the framework's ability to track repetitions on longer time scales. This approach allows characterization of the overall information contents of a musical signal at each level of acoustic sensibility. Our findings under this framework show that sensibility to subtle acoustic changes is higher for East-Asian musical traditions, while the Western works exhibit longer motivic structures at higher thresholds of differences in the latent space. This suggests that a profile of information contents, analyzed as a function of the level of acoustic detail can serve as a possible cultural characteristic.
Music SketchNet: Controllable Music Generation via Factorized Representations of Pitch and Rhythm
Aug 04, 2020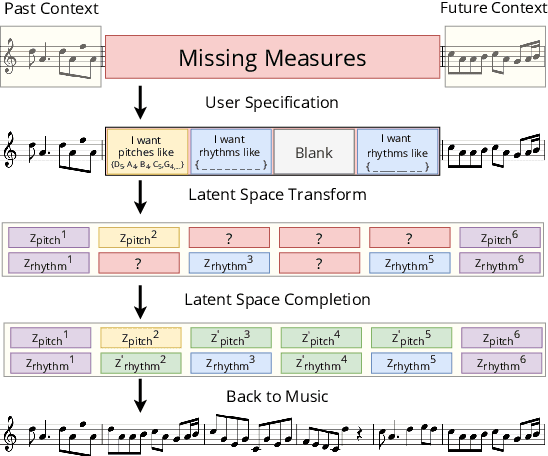
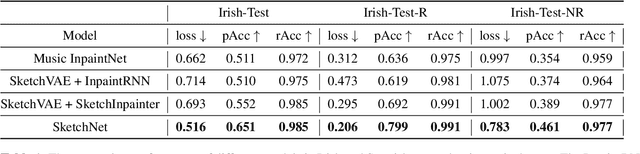
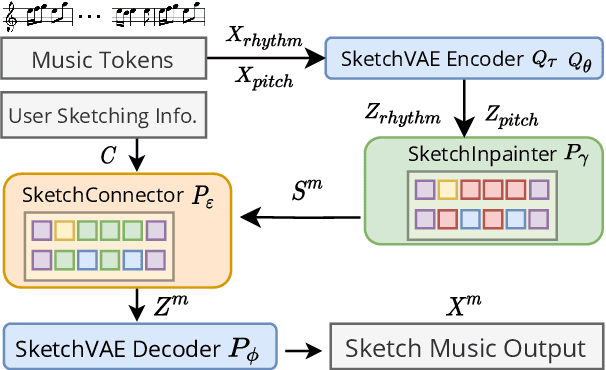
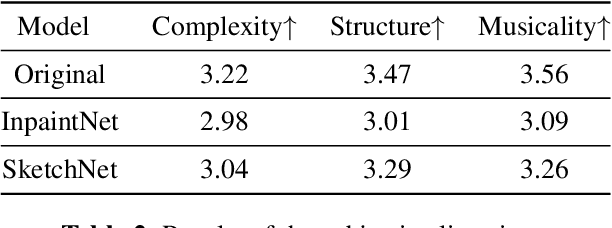
Drawing an analogy with automatic image completion systems, we propose Music SketchNet, a neural network framework that allows users to specify partial musical ideas guiding automatic music generation. We focus on generating the missing measures in incomplete monophonic musical pieces, conditioned on surrounding context, and optionally guided by user-specified pitch and rhythm snippets. First, we introduce SketchVAE, a novel variational autoencoder that explicitly factorizes rhythm and pitch contour to form the basis of our proposed model. Then we introduce two discriminative architectures, SketchInpainter and SketchConnector, that in conjunction perform the guided music completion, filling in representations for the missing measures conditioned on surrounding context and user-specified snippets. We evaluate SketchNet on a standard dataset of Irish folk music and compare with models from recent works. When used for music completion, our approach outperforms the state-of-the-art both in terms of objective metrics and subjective listening tests. Finally, we demonstrate that our model can successfully incorporate user-specified snippets during the generation process.
Deep Autotuner: a Pitch Correcting Network for Singing Performances
Feb 12, 2020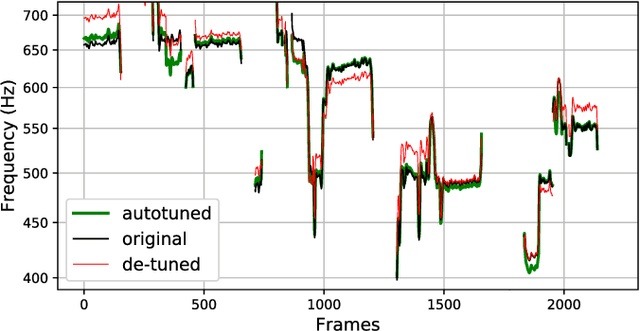
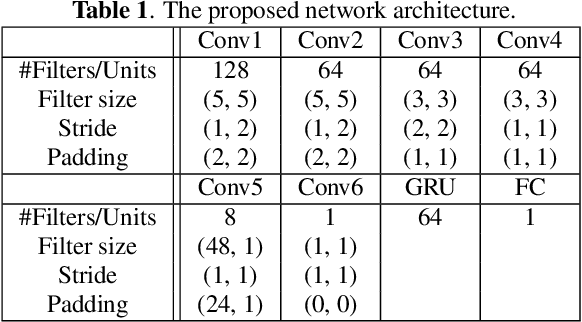
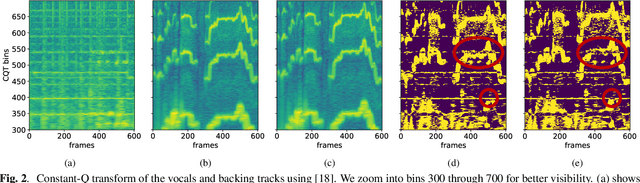
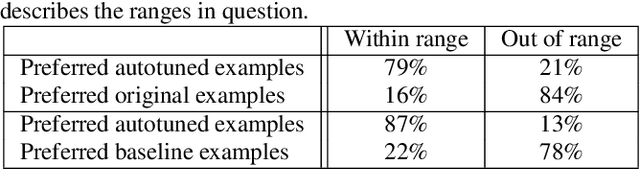
We introduce a data-driven approach to automatic pitch correction of solo singing performances. The proposed approach predicts note-wise pitch shifts from the relationship between the respective spectrograms of the singing and accompaniment. This approach differs from commercial systems, where vocal track notes are usually shifted to be centered around pitches in a user-defined score, or mapped to the closest pitch among the twelve equal-tempered scale degrees. The proposed system treats pitch as a continuous value rather than relying on a set of discretized notes found in musical scores, thus allowing for improvisation and harmonization in the singing performance. We train our neural network model using a dataset of 4,702 amateur karaoke performances selected for good intonation. Our model is trained on both incorrect intonation, for which it learns a correction, and intentional pitch variation, which it learns to preserve. The proposed deep neural network with gated recurrent units on top of convolutional layers shows promising performance on the real-world score-free singing pitch correction task of autotuning.
Deep Autotuner: A Data-Driven Approach to Natural-Sounding Pitch Correction for Singing Voice in Karaoke Performances
Feb 03, 2019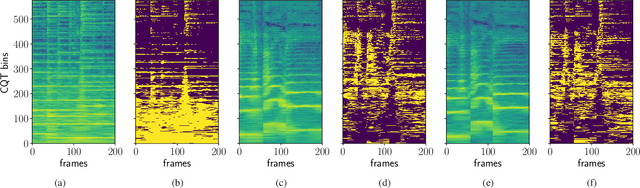
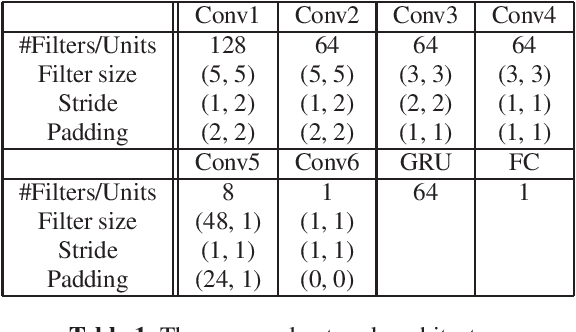
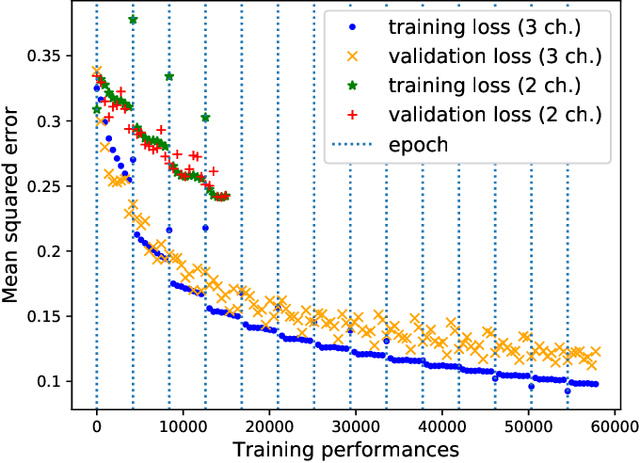
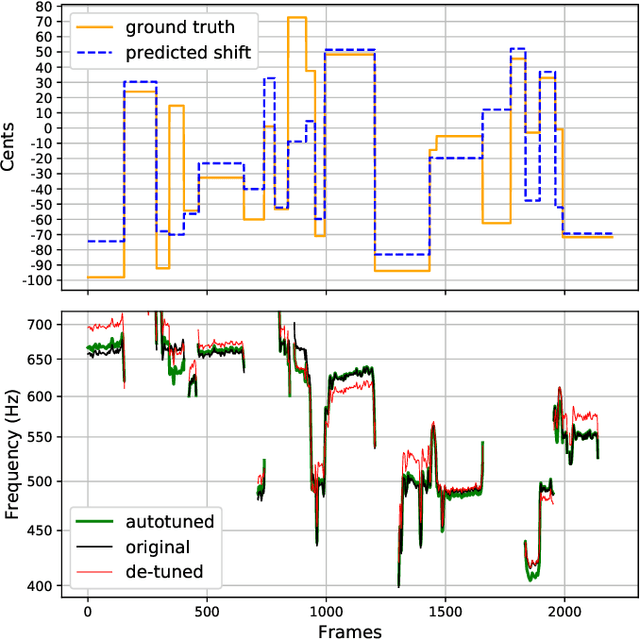
We describe a machine-learning approach to pitch correcting a solo singing performance in a karaoke setting, where the solo voice and accompaniment are on separate tracks. The proposed approach addresses the situation where no musical score of the vocals nor the accompaniment exists: It predicts the amount of correction from the relationship between the spectral contents of the vocal and accompaniment tracks. Hence, the pitch shift in cents suggested by the model can be used to make the voice sound in tune with the accompaniment. This approach differs from commercially used automatic pitch correction systems, where notes in the vocal tracks are shifted to be centered around notes in a user-defined score or mapped to the closest pitch among the twelve equal-tempered scale degrees. We train the model using a dataset of 4,702 amateur karaoke performances selected for good intonation. We present a Convolutional Gated Recurrent Unit (CGRU) model to accomplish this task. This method can be extended into unsupervised pitch correction of a vocal performance, popularly referred to as autotuning.
Free-body Gesture Tracking and Augmented Reality Improvisation for Floor and Aerial Dance
Sep 15, 2015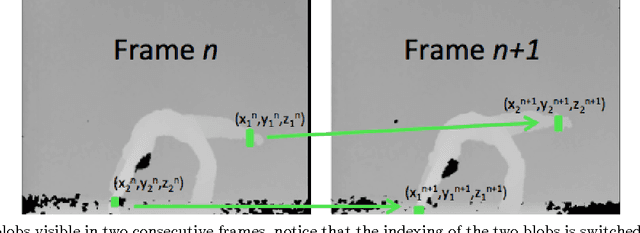


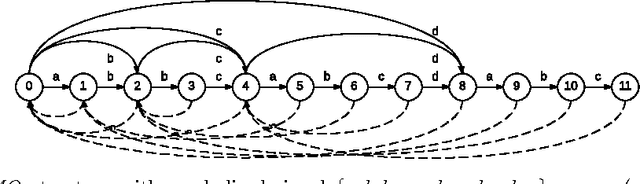
This paper describes an updated interactive performance system for floor and Aerial Dance that controls visual and sonic aspects of the presentation via a depth sensing camera (MS Kinect). In order to detect, measure and track free movement in space, 3 degree of freedom (3-DOF) tracking in space (on the ground and in the air) is performed using IR markers with a method for multi target tracking capabilities added and described in detail. An improved gesture tracking and recognition system, called Action Graph (AG), is described in the paper. Action Graph uses an efficient incremental construction from a single long sequence of movement features and automatically captures repeated sub-segments in the movement from start to finish with no manual interaction needed with other advanced capabilities discussed as well. By using the new model for the gesture we can unify an entire choreography piece by dynamically tracking and recognizing gestures and sub-portions of the piece. This gives the performer the freedom to improvise based on a set of recorded gestures/portions of the choreography and have the system dynamically respond in relation to the performer within a set of related rehearsed actions, an ability that has not been seen in any other system to date.