 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Approximate Inference for Stochastic Planning in Factored Spaces
Mar 23, 2022
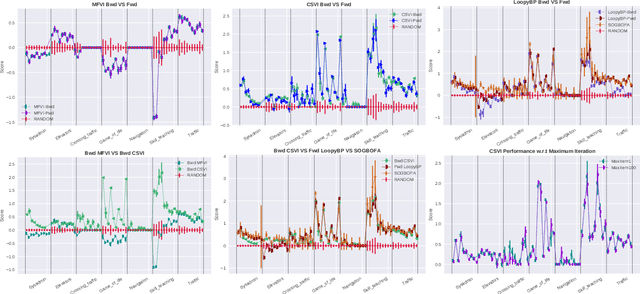

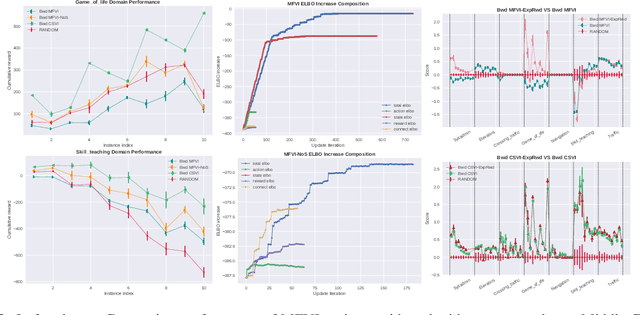
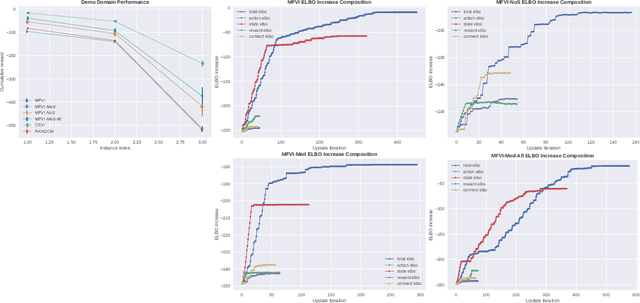
The paper explores the use of approximate inference techniques as solution methods for stochastic planning problems with discrete factored spaces. While much prior work exists on this topic, subtle variations hinder a global understanding of different approaches for their differences and potential advantages. Here we abstract a simple framework that captures and connects prior work along two dimensions, direction of information flow, i.e., forward vs backward inference, and the type of approximation used, e.g., Belief Propagation (BP) vs mean field variational inference (MFVI). Through this analysis we also propose a novel algorithm, CSVI, which provides a tighter variational approximation compared to prior work. An extensive experimental evaluation compares algorithms from different branches of the framework, showing that methods based on BP are generally better than methods based on MFVI, that CSVI is competitive with BP algorithms, and that while inference direction does not show a significant effect for VI methods, forward inference provides stronger performance with BP.
Learn to Use Future Information in Simultaneous Translation
Jul 10, 2020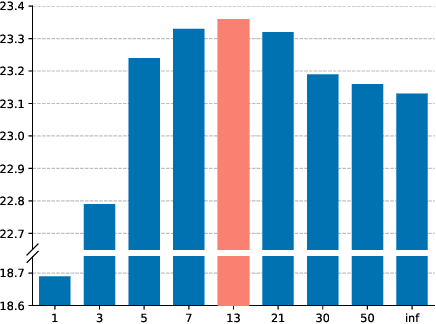
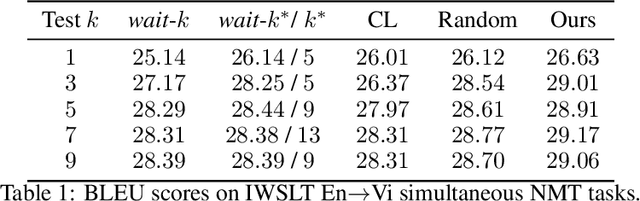
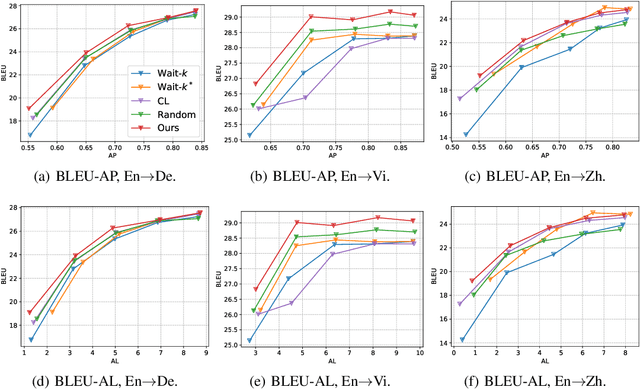

Simultaneous neural machine translation (briefly, NMT) has attracted much attention recently. In contrast to standard NMT, where the NMT system can utilize the full input sentence, simultaneous NMT is formulated as a prefix-to-prefix problem, where the system can only utilize the prefix of the input sentence and more uncertainty is introduced to decoding. Wait-$k$ is a simple yet effective strategy for simultaneous NMT, where the decoder generates the output sequence $k$ words behind the input words. We observed that training simultaneous NMT systems with future information (i.e., trained with a larger $k$) generally outperforms the standard ones (i.e., trained with the given $k$). Based on this observation, we propose a framework that automatically learns how much future information to use in training for simultaneous NMT. We first build a series of tasks where each one is associated with a different $k$, and then learn a model on these tasks guided by a controller. The controller is jointly trained with the translation model through bi-level optimization. We conduct experiments on four datasets to demonstrate the effectiveness of our method.
EventFormer: AU Event Transformer for Facial Action Unit Event Detection
Mar 12, 2022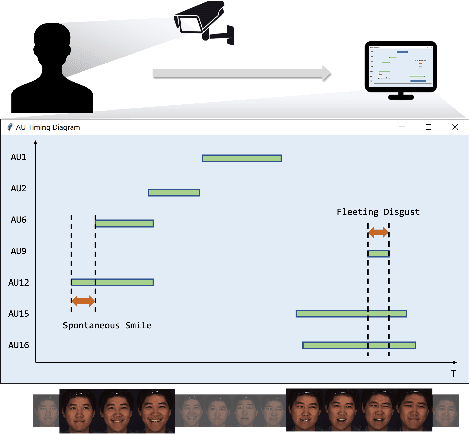
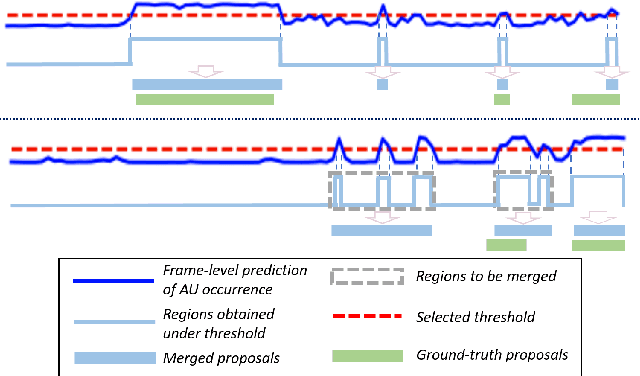
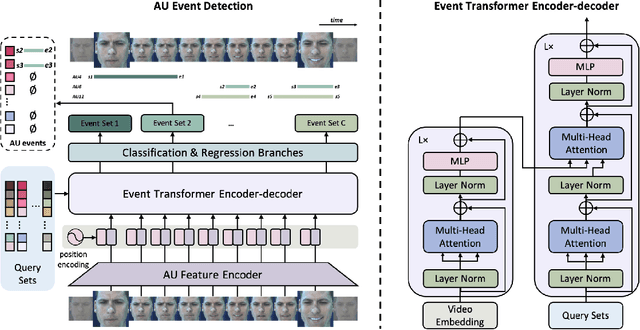
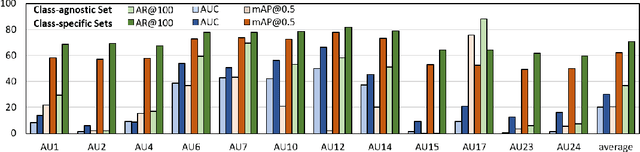
Facial action units (AUs) play an indispensable role in human emotion analysis. We observe that although AU-based high-level emotion analysis is urgently needed by real-world applications, frame-level AU results provided by previous works cannot be directly used for such analysis. Moreover, as AUs are dynamic processes, the utilization of global temporal information is important but has been gravely ignored in the literature. To this end, we propose EventFormer for AU event detection, which is the first work directly detecting AU events from a video sequence by viewing AU event detection as a multiple class-specific sets prediction problem. Extensive experiments conducted on a commonly used AU benchmark dataset, BP4D, show the superiority of EventFormer under suitable metrics.
Point Cloud Denoising via Momentum Ascent in Gradient Fields
Mar 15, 2022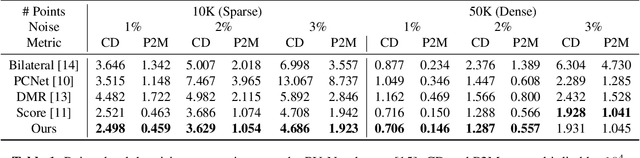
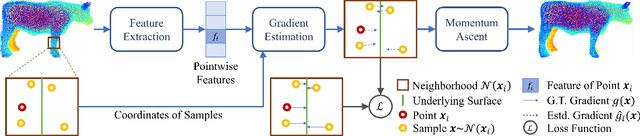

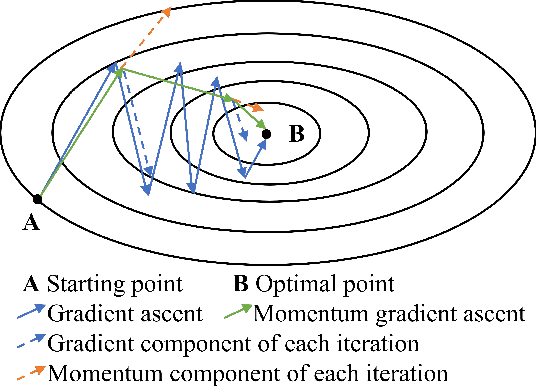
To achieve point cloud denoising, traditional methods heavily rely on geometric priors, and most learning-based approaches suffer from outliers and loss of details. Recently, the gradient-based method was proposed to estimate the gradient fields from the noisy point clouds using neural networks, and refine the position of each point according to the estimated gradient. However, the predicted gradient could fluctuate, leading to perturbed and unstable solutions, as well as a large inference time. To address these issues, we develop the momentum gradient ascent method that leverages the information of previous iterations in determining the trajectories of the points, thus improving the stability of the solution and reducing the inference time. Experiments demonstrate that the proposed method outperforms state-of-the-art methods with a variety of point clouds and noise levels.
Lymphocyte Classification in Hyperspectral Images of Ovarian Cancer Tissue Biopsy Samples
Mar 23, 2022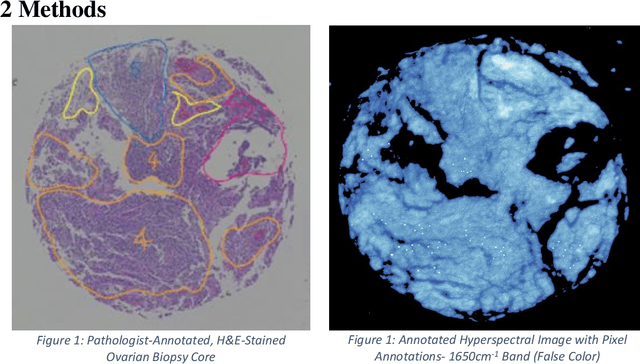
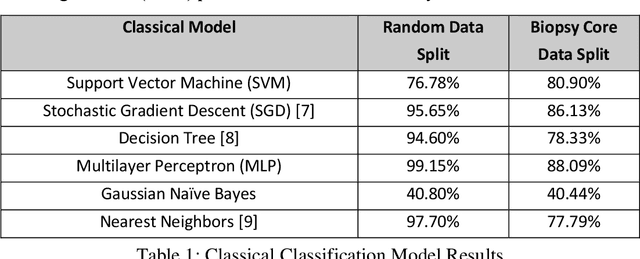
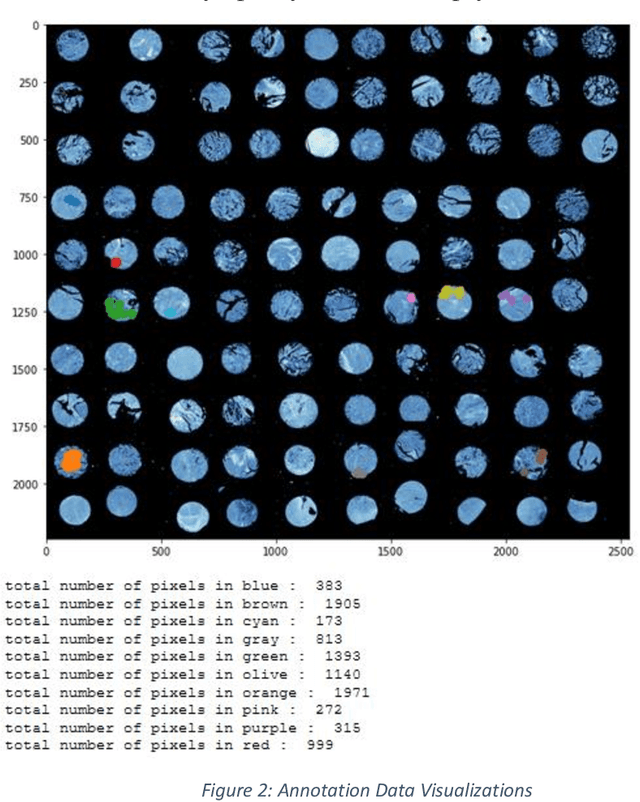

Current methods for diagnosing the progression of multiple types of cancer within patients rely on interpreting stained needle biopsies. This process is time-consuming and susceptible to error throughout the paraffinization, Hematoxylin and Eosin (H&E) staining, deparaffinization, and annotation stages. Fourier Transform Infrared (FTIR) imaging has been shown to be a promising alternative to staining for appropriately annotating biopsy cores without the need for deparaffinization or H&E staining with the use of Fourier Transform Infrared (FTIR) images when combined with machine learning to interpret the dense spectral information. We present a machine learning pipeline to segment white blood cell (lymphocyte) pixels in hyperspectral images of biopsy cores. These cells are clinically important for diagnosis, but some prior work has struggled to incorporate them due to difficulty obtaining precise pixel labels. Evaluated methods include Support Vector Machine (SVM), Gaussian Naive Bayes, and Multilayer Perceptron (MLP), as well as analyzing the comparatively modern convolutional neural network (CNN).
A Keypoint-based Global Association Network for Lane Detection
Apr 15, 2022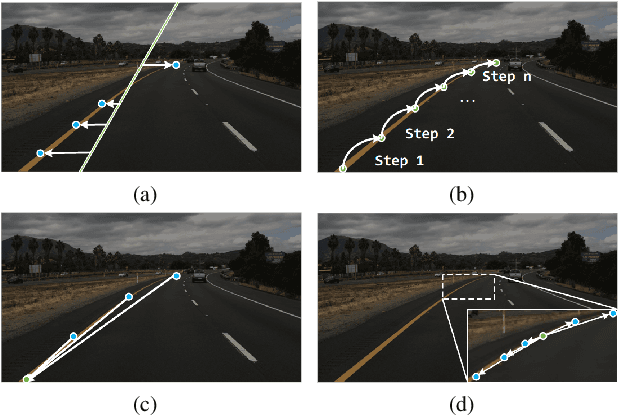

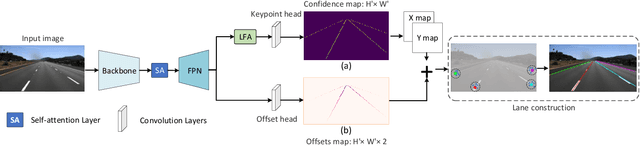
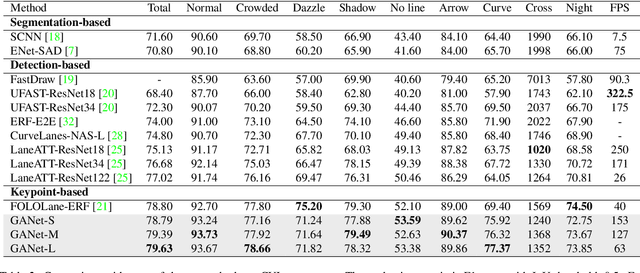
Lane detection is a challenging task that requires predicting complex topology shapes of lane lines and distinguishing different types of lanes simultaneously. Earlier works follow a top-down roadmap to regress predefined anchors into various shapes of lane lines, which lacks enough flexibility to fit complex shapes of lanes due to the fixed anchor shapes. Lately, some works propose to formulate lane detection as a keypoint estimation problem to describe the shapes of lane lines more flexibly and gradually group adjacent keypoints belonging to the same lane line in a point-by-point manner, which is inefficient and time-consuming during postprocessing. In this paper, we propose a Global Association Network (GANet) to formulate the lane detection problem from a new perspective, where each keypoint is directly regressed to the starting point of the lane line instead of point-by-point extension. Concretely, the association of keypoints to their belonged lane line is conducted by predicting their offsets to the corresponding starting points of lanes globally without dependence on each other, which could be done in parallel to greatly improve efficiency. In addition, we further propose a Lane-aware Feature Aggregator (LFA), which adaptively captures the local correlations between adjacent keypoints to supplement local information to the global association. Extensive experiments on two popular lane detection benchmarks show that our method outperforms previous methods with F1 score of 79.63% on CULane and 97.71% on Tusimple dataset with high FPS. The code will be released at https://github.com/Wolfwjs/GANet.
A Novel Intrinsic Image Decomposition Method to Recover Albedo for Aerial Images in Photogrammetry Processing
Apr 08, 2022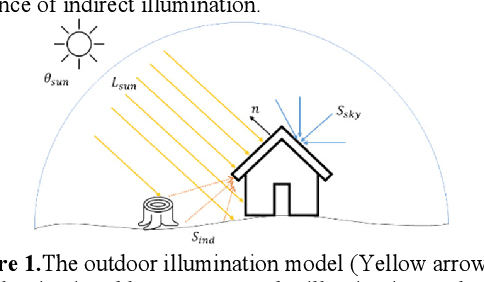


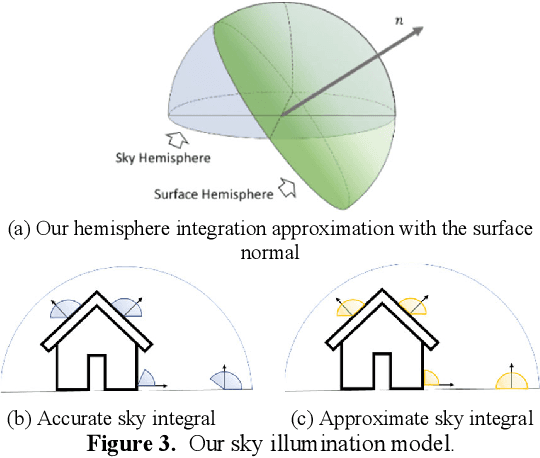
Recovering surface albedos from photogrammetric images for realistic rendering and synthetic environments can greatly facilitate its downstream applications in VR/AR/MR and digital twins. The textured 3D models from standard photogrammetric pipelines are suboptimal to these applications because these textures are directly derived from images, which intrinsically embedded the spatially and temporally variant environmental lighting information, such as the sun illumination, direction, causing different looks of the surface, making such models less realistic when used in 3D rendering under synthetic lightings. On the other hand, since albedo images are less variable by environmental lighting, it can, in turn, benefit basic photogrammetric processing. In this paper, we attack the problem of albedo recovery for aerial images for the photogrammetric process and demonstrate the benefit of albedo recovery for photogrammetry data processing through enhanced feature matching and dense matching. To this end, we proposed an image formation model with respect to outdoor aerial imagery under natural illumination conditions; we then, derived the inverse model to estimate the albedo by utilizing the typical photogrammetric products as an initial approximation of the geometry. The estimated albedo images are tested in intrinsic image decomposition, relighting, feature matching, and dense matching/point cloud generation results. Both synthetic and real-world experiments have demonstrated that our method outperforms existing methods and can enhance photogrammetric processing.
S$^2$FPR: Crowd Counting via Self-Supervised Coarse to Fine Feature Pyramid Ranking
Jan 13, 2022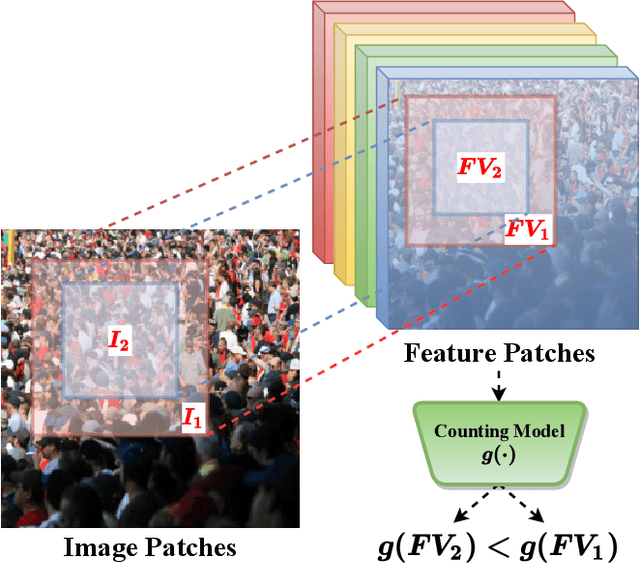
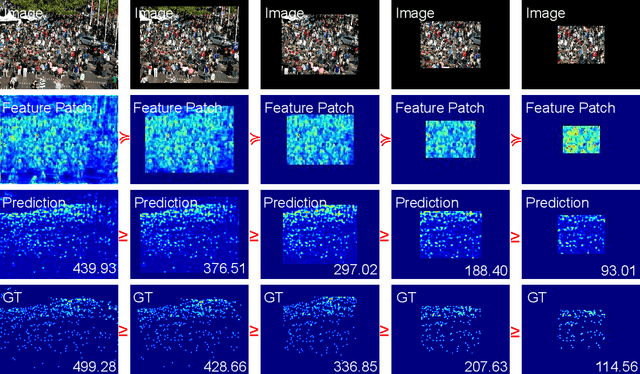
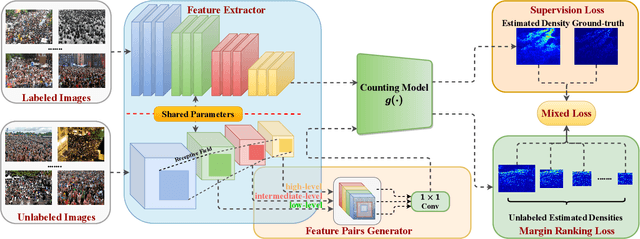

Most conventional crowd counting methods utilize a fully-supervised learning framework to learn a mapping between scene images and crowd density maps. Under the circumstances of such fully-supervised training settings, a large quantity of expensive and time-consuming pixel-level annotations are required to generate density maps as the supervision. One way to reduce costly labeling is to exploit self-structural information and inner-relations among unlabeled images. Unlike the previous methods utilizing these relations and structural information from the original image level, we explore such self-relations from the latent feature spaces because it can extract more abundant relations and structural information. Specifically, we propose S$^2$FPR which can extract structural information and learn partial orders of coarse-to-fine pyramid features in the latent space for better crowd counting with massive unlabeled images. In addition, we collect a new unlabeled crowd counting dataset (FUDAN-UCC) with 4,000 images in total for training. One by-product is that our proposed S$^2$FPR method can leverage numerous partial orders in the latent space among unlabeled images to strengthen the model representation capability and reduce the estimation errors for the crowd counting task. Extensive experiments on four benchmark datasets, i.e. the UCF-QNRF, the ShanghaiTech PartA and PartB, and the UCF-CC-50, show the effectiveness of our method compared with previous semi-supervised methods. The source code and dataset are available at https://github.com/bridgeqiqi/S2FPR.
Domain Adaptation via Prompt Learning
Feb 14, 2022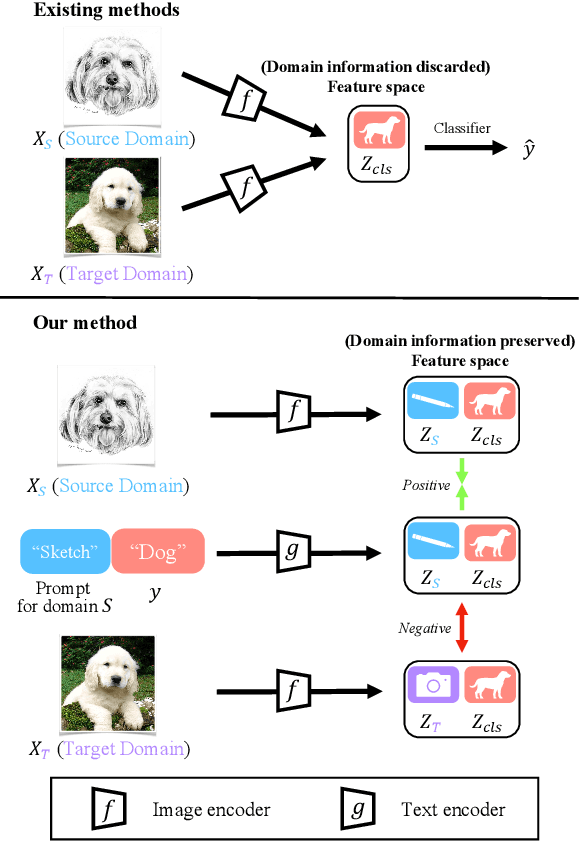

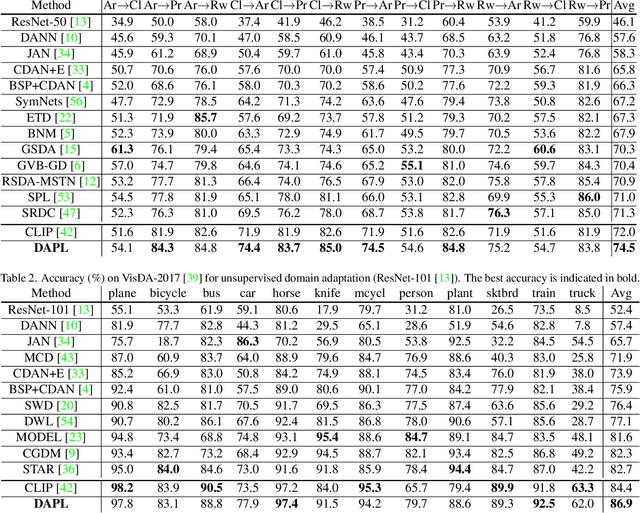
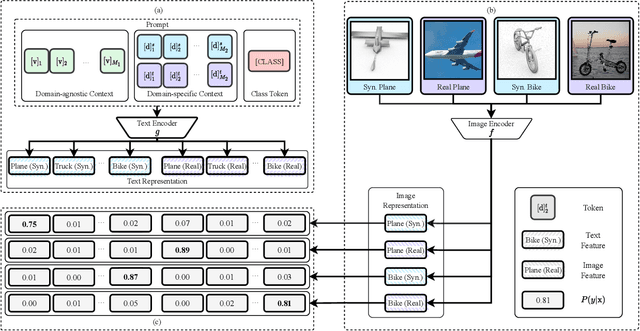
Unsupervised domain adaption (UDA) aims to adapt models learned from a well-annotated source domain to a target domain, where only unlabeled samples are given. Current UDA approaches learn domain-invariant features by aligning source and target feature spaces. Such alignments are imposed by constraints such as statistical discrepancy minimization or adversarial training. However, these constraints could lead to the distortion of semantic feature structures and loss of class discriminability. In this paper, we introduce a novel prompt learning paradigm for UDA, named Domain Adaptation via Prompt Learning (DAPL). In contrast to prior works, our approach makes use of pre-trained vision-language models and optimizes only very few parameters. The main idea is to embed domain information into prompts, a form of representations generated from natural language, which is then used to perform classification. This domain information is shared only by images from the same domain, thereby dynamically adapting the classifier according to each domain. By adopting this paradigm, we show that our model not only outperforms previous methods on several cross-domain benchmarks but also is very efficient to train and easy to implement.
Deep Learning for Spectral Filling in Radio Frequency Applications
Mar 31, 2022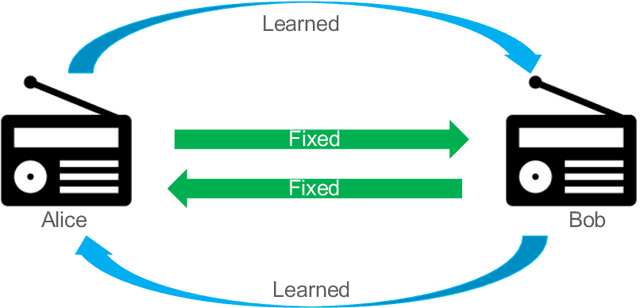
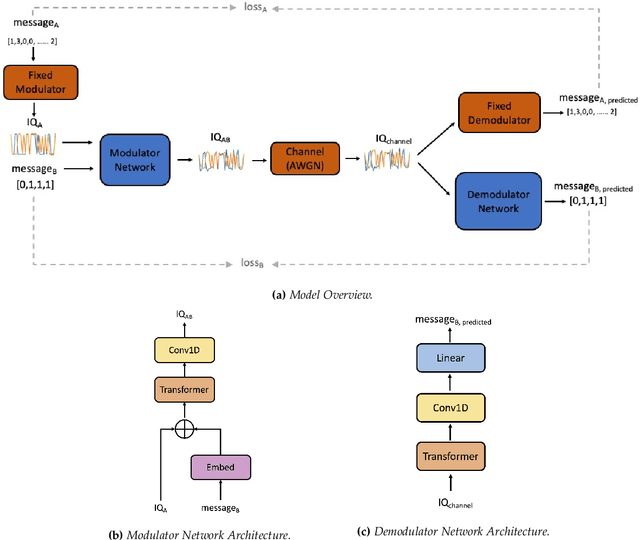
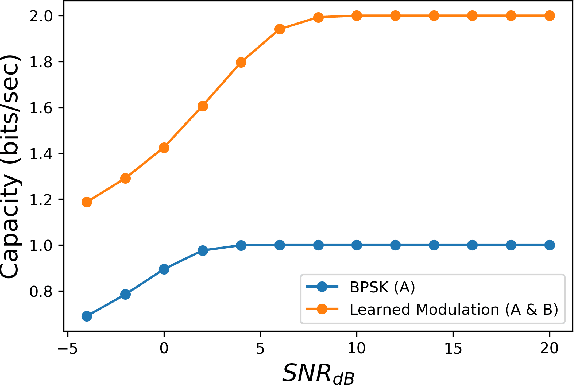
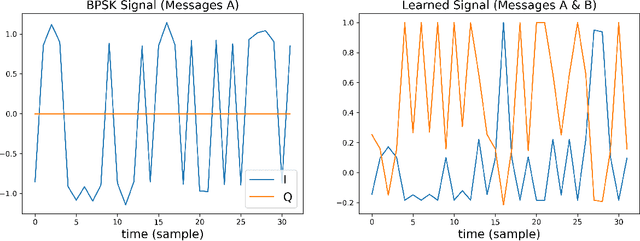
Due to the Internet of Things (IoT) proliferation, Radio Frequency (RF) channels are increasingly congested with new kinds of devices, which carry unique and diverse communication needs. This poses complex challenges in modern digital communications, and calls for the development of technological innovations that (i) optimize capacity (bitrate) in limited bandwidth environments, (ii) integrate cooperatively with already-deployed RF protocols, and (iii) are adaptive to the ever-changing demands in modern digital communications. In this paper we present methods for applying deep neural networks for spectral filling. Given an RF channel transmitting digital messages with a pre-established modulation scheme, we automatically learn novel modulation schemes for sending extra information, in the form of additional messages, "around" the fixed-modulation signals (i.e., without interfering with them). In so doing, we effectively increase channel capacity without increasing bandwidth. We further demonstrate the ability to generate signals that closely resemble the original modulations, such that the presence of extra messages is undetectable to third-party listeners. We present three computational experiments demonstrating the efficacy of our methods, and conclude by discussing the implications of our results for modern RF applications.