 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrainMover: Efficient ML Training Live Migration with No Memory Overhead
Dec 17, 2024



Machine learning training has emerged as one of the most prominent workloads in modern data centers. These training jobs are large-scale, long-lasting, and tightly coupled, and are often disrupted by various events in the cluster such as failures, maintenance, and job scheduling. To handle these events, we rely on cold migration, where we first checkpoint the entire cluster, replace the related machines, and then restart the training. This approach leads to disruptions to the training jobs, resulting in significant downtime. In this paper, we present TrainMover, a live migration system that enables machine replacement during machine learning training. TrainMover minimizes downtime by leveraging member replacement of collective communication groups and sandbox lazy initialization. Our evaluation demonstrates that TrainMover achieves 16x less downtime compared to all baselines, effectively handling data center events like straggler rebalancing, maintenance, and unexpected failures.
Cora: Accelerating Stateful Network Applications with SmartNICs
Oct 29, 2024



With the growing performance requirements on networked applications, there is a new trend of offloading stateful network applications to SmartNICs to improve performance and reduce the total cost of ownership. However, offloading stateful network applications is non-trivial due to state operation complexity, state resource consumption, and the complicated relationship between traffic and state. Naively partitioning the program by state or traffic can result in a suboptimal partition plan with higher CPU usage or even packet drops. In this paper, we propose Cora, a compiler and runtime that offloads stateful network applications to SmartNIC-accelerated hosts. Cora compiler introduces an accurate performance model for each SmartNIC and employs an efficient compiling algorithm to search the offloading plan. Cora runtime can monitor traffic dynamics and adapt to minimize CPU usage. Cora is built atop Netronome Agilio and BlueField 2 SmartNICs. Our evaluation shows that for the same throughput target, Cora can propose partition plans saving up to 94.0% CPU cores, 1.9 times more than baseline solutions. Under the same resource constraint, Cora can accelerate network functions by 44.9%-82.3%. Cora runtime can adapt to traffic changes and keep CPU usage low.
HawkVision: Low-Latency Modeless Edge AI Serving
May 29, 2024The trend of modeless ML inference is increasingly growing in popularity as it hides the complexity of model inference from users and caters to diverse user and application accuracy requirements. Previous work mostly focuses on modeless inference in data centers. To provide low-latency inference, in this paper, we promote modeless inference at the edge. The edge environment introduces additional challenges related to low power consumption, limited device memory, and volatile network environments. To address these challenges, we propose HawkVision, which provides low-latency modeless serving of vision DNNs. HawkVision leverages a two-layer edge-DC architecture that employs confidence scaling to reduce the number of model options while meeting diverse accuracy requirements. It also supports lossy inference under volatile network environments. Our experimental results show that HawkVision outperforms current serving systems by up to 1.6X in P99 latency for providing modeless service. Our FPGA prototype demonstrates similar performance at certain accuracy levels with up to a 3.34X reduction in power consumption.
Cross-head Supervision for Crowd Counting with Noisy Annotations
Mar 16, 2023



Noisy annotations such as missing annotations and location shifts often exist in crowd counting datasets due to multi-scale head sizes, high occlusion, etc. These noisy annotations severely affect the model training, especially for density map-based methods. To alleviate the negative impact of noisy annotations, we propose a novel crowd counting model with one convolution head and one transformer head, in which these two heads can supervise each other in noisy areas, called Cross-Head Supervision. The resultant model, CHS-Net, can synergize different types of inductive biases for better counting. In addition, we develop a progressive cross-head supervision learning strategy to stabilize the training process and provide more reliable supervision. Extensive experimental results on ShanghaiTech and QNRF datasets demonstrate superior performance over state-of-the-art methods. Code is available at https://github.com/RaccoonDML/CHSNet.
Unsupervised Video Anomaly Detection for Stereotypical Behaviours in Autism
Feb 27, 2023



Monitoring and analyzing stereotypical behaviours is important for early intervention and care taking in Autism Spectrum Disorder (ASD). This paper focuses on automatically detecting stereotypical behaviours with computer vision techniques. Off-the-shelf methods tackle this task by supervised classification and activity recognition techniques. However, the unbounded types of stereotypical behaviours and the difficulty in collecting video recordings of ASD patients largely limit the feasibility of the existing supervised detection methods. As a result, we tackle these challenges from a new perspective, i.e. unsupervised video anomaly detection for stereotypical behaviours detection. The models can be trained among unlabeled videos containing only normal behaviours and unknown types of abnormal behaviours can be detected during inference. Correspondingly, we propose a Dual Stream deep model for Stereotypical Behaviours Detection, DS-SBD, based on the temporal trajectory of human poses and the repetition patterns of human actions. Extensive experiments are conducted to verify the effectiveness of our proposed method and suggest that it serves as a potential benchmark for future research.
Forget Less, Count Better: A Domain-Incremental Self-Distillation Learning Benchmark for Lifelong Crowd Counting
May 06, 2022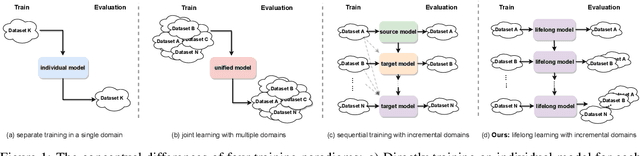
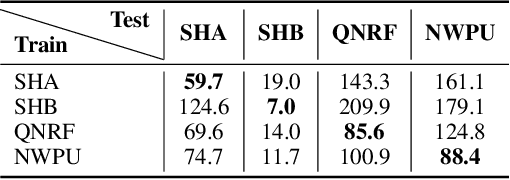
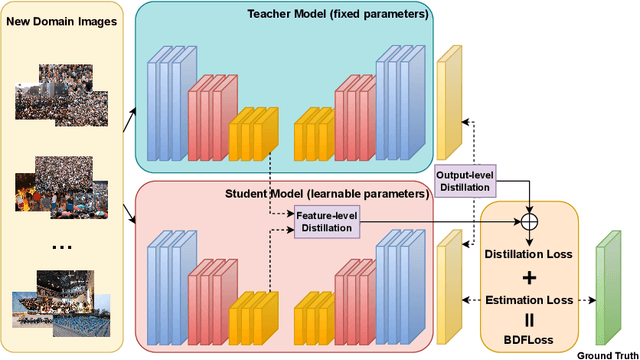
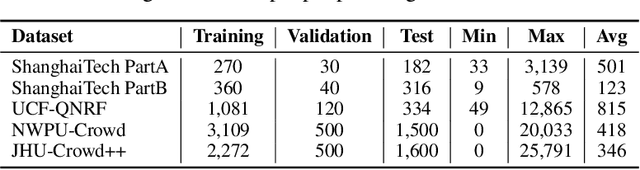
Crowd Counting has important applications in public safety and pandemic control. A robust and practical crowd counting system has to be capable of continuously learning with the new-coming domain data in real-world scenarios instead of fitting one domain only. Off-the-shelf methods have some drawbacks to handle multiple domains. 1) The models will achieve limited performance (even drop dramatically) among old domains after training images from new domains due to the discrepancies of intrinsic data distributions from various domains, which is called catastrophic forgetting. 2) The well-trained model in a specific domain achieves imperfect performance among other unseen domains because of the domain shift. 3) It leads to linearly-increased storage overhead either mixing all the data for training or simply training dozens of separate models for different domains when new ones are available. To overcome these issues, we investigate a new task of crowd counting under the incremental domains training setting, namely, Lifelong Crowd Counting. It aims at alleviating the catastrophic forgetting and improving the generalization ability using a single model updated by the incremental domains. To be more specific, we propose a self-distillation learning framework as a benchmark~(Forget Less, Count Better, FLCB) for lifelong crowd counting, which helps the model sustainably leverage previous meaningful knowledge for better crowd counting to mitigate the forgetting when the new data arrive. Meanwhile, a new quantitative metric, normalized backward transfer~(nBwT), is developed to evaluate the forgetting degree of the model in the lifelong learning process. Extensive experimental results demonstrate the superiority of our proposed benchmark in achieving a low catastrophic forgetting degree and strong generalization ability.
S$^2$FPR: Crowd Counting via Self-Supervised Coarse to Fine Feature Pyramid Ranking
Jan 13, 2022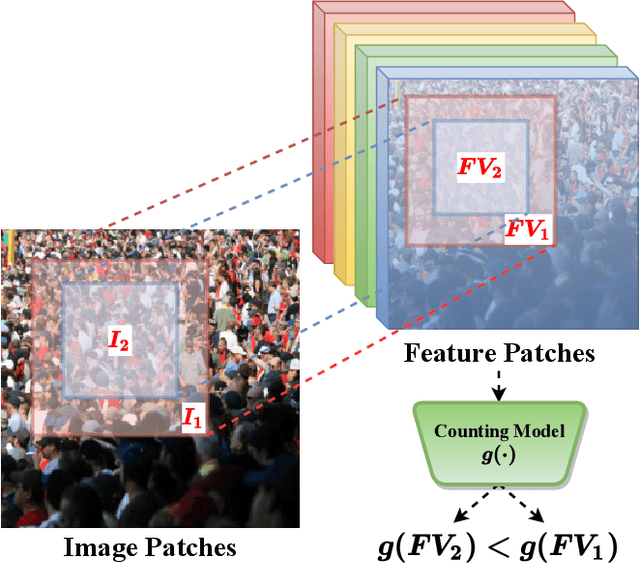
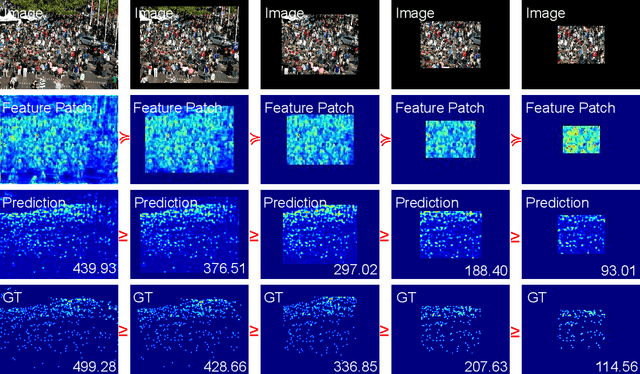
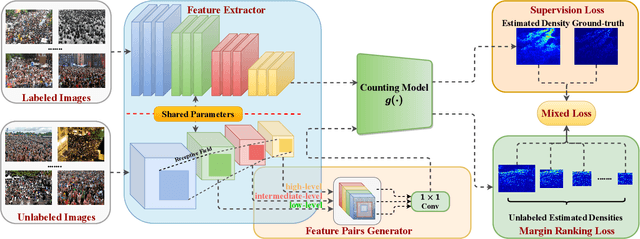

Most conventional crowd counting methods utilize a fully-supervised learning framework to learn a mapping between scene images and crowd density maps. Under the circumstances of such fully-supervised training settings, a large quantity of expensive and time-consuming pixel-level annotations are required to generate density maps as the supervision. One way to reduce costly labeling is to exploit self-structural information and inner-relations among unlabeled images. Unlike the previous methods utilizing these relations and structural information from the original image level, we explore such self-relations from the latent feature spaces because it can extract more abundant relations and structural information. Specifically, we propose S$^2$FPR which can extract structural information and learn partial orders of coarse-to-fine pyramid features in the latent space for better crowd counting with massive unlabeled images. In addition, we collect a new unlabeled crowd counting dataset (FUDAN-UCC) with 4,000 images in total for training. One by-product is that our proposed S$^2$FPR method can leverage numerous partial orders in the latent space among unlabeled images to strengthen the model representation capability and reduce the estimation errors for the crowd counting task. Extensive experiments on four benchmark datasets, i.e. the UCF-QNRF, the ShanghaiTech PartA and PartB, and the UCF-CC-50, show the effectiveness of our method compared with previous semi-supervised methods. The source code and dataset are available at https://github.com/bridgeqiqi/S2FPR.