 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Comparative Study of Fusion Methods for SASV Challenge 2022
Mar 31, 2022
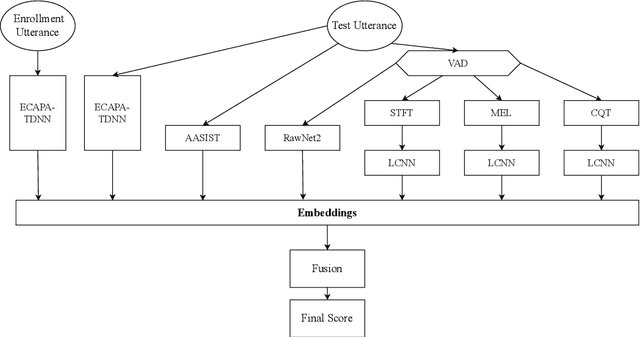
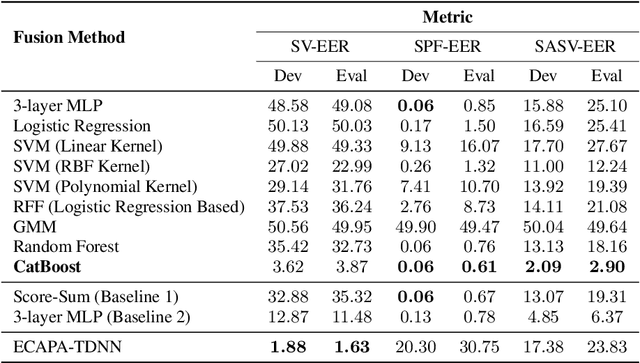
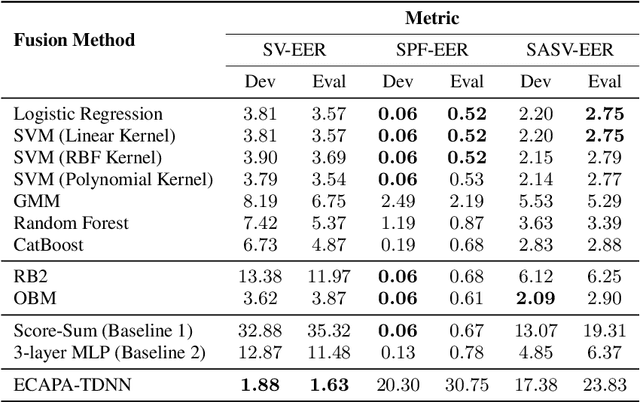
Automatic Speaker Verification (ASV) system is a type of bio-metric authentication. It can be attacked by an intruder, who falsifies data in order to get access to protected information. Countermeasures (CM) are special algorithms that detect these spoofing-attacks. While the ASVspoof Challenge series were focused on the development of CM for fixed ASV system, the new Spoofing Aware Speaker Verification (SASV) Challenge organizers believe that best results can be achieved if CM and ASV systems are optimized jointly. One of the approaches for cooperative optimization is a fusion over embeddings or scores obtained from ASV and CM models. The baselines of SASV Challenge 2022 present two types of fusion: score-sum and back-end ensemble with a 3-layer MLP. This paper describes our research of other fusion methods, including boosting over embeddings, which has not been used in anti-spoofing studies before.
Sign and Basis Invariant Networks for Spectral Graph Representation Learning
Apr 11, 2022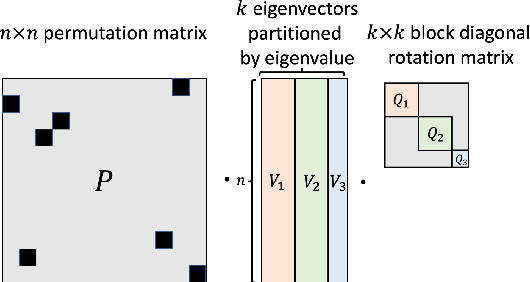
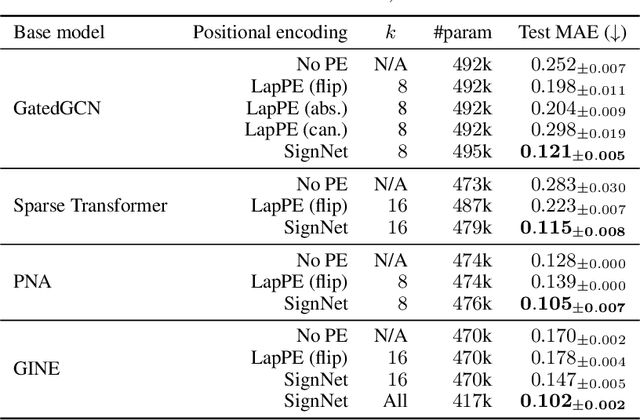

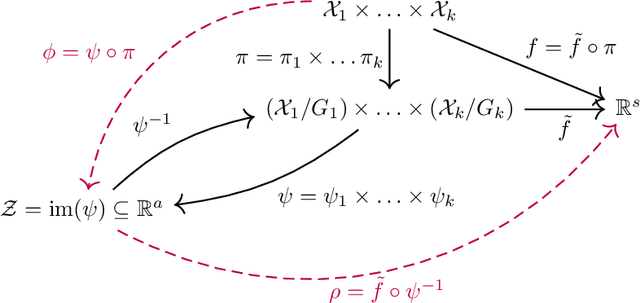
Many machine learning tasks involve processing eigenvectors derived from data. Especially valuable are Laplacian eigenvectors, which capture useful structural information about graphs and other geometric objects. However, ambiguities arise when computing eigenvectors: for each eigenvector $v$, the sign flipped $-v$ is also an eigenvector. More generally, higher dimensional eigenspaces contain infinitely many choices of basis eigenvectors. These ambiguities make it a challenge to process eigenvectors and eigenspaces in a consistent way. In this work we introduce SignNet and BasisNet -- new neural architectures that are invariant to all requisite symmetries and hence process collections of eigenspaces in a principled manner. Our networks are universal, i.e., they can approximate any continuous function of eigenvectors with the proper invariances. They are also theoretically strong for graph representation learning -- they can approximate any spectral graph convolution, can compute spectral invariants that go beyond message passing neural networks, and can provably simulate previously proposed graph positional encodings. Experiments show the strength of our networks for molecular graph regression, learning expressive graph representations, and learning implicit neural representations on triangle meshes. Our code is available at https://github.com/cptq/SignNet-BasisNet .
Language-Independent Speaker Anonymization Approach using Self-Supervised Pre-Trained Models
Mar 26, 2022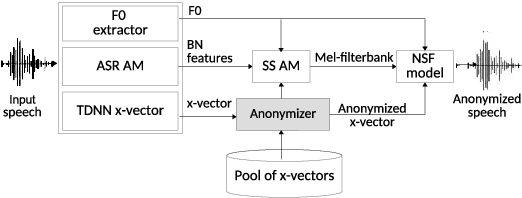
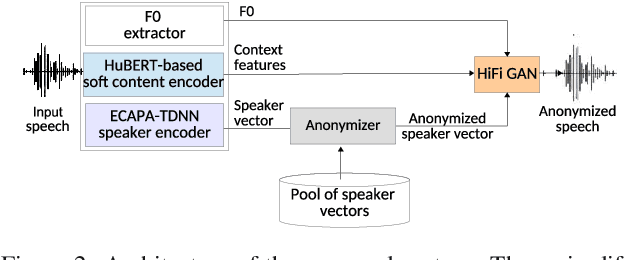

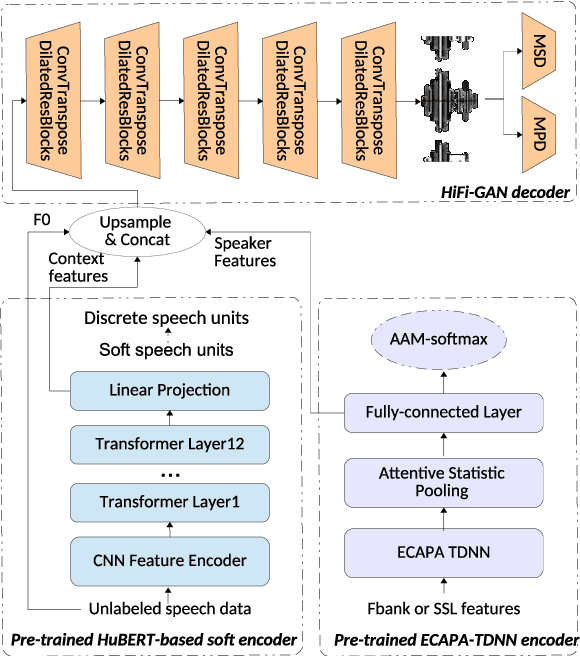
Speaker anonymization aims to protect the privacy of speakers while preserving spoken linguistic information from speech. Current mainstream neural network speaker anonymization systems are complicated, containing an F0 extractor, speaker encoder, automatic speech recognition acoustic model (ASR AM), speech synthesis acoustic model and speech waveform generation model. Moreover, as an ASR AM is language-dependent, trained on English data, it is hard to adapt it into another language. In this paper, we propose a simpler self-supervised learning (SSL)-based method for language-independent speaker anonymization without any explicit language-dependent model, which can be easily used for other languages. Extensive experiments were conducted on the VoicePrivacy Challenge 2020 datasets in English and AISHELL-3 datasets in Mandarin to demonstrate the effectiveness of our proposed SSL-based language-independent speaker anonymization method.
Privacy-aware Early Detection of COVID-19 through Adversarial Training
Jan 09, 2022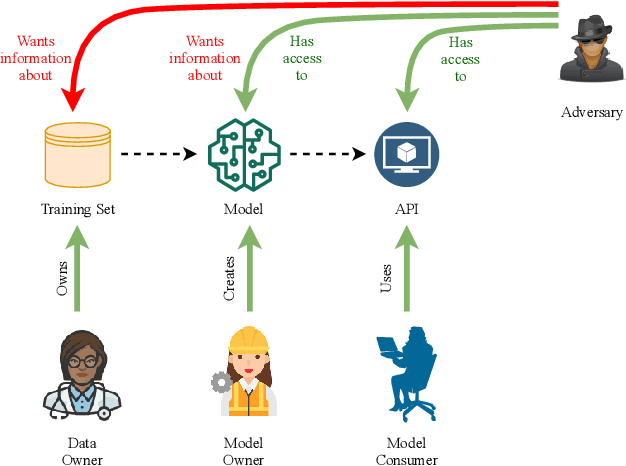
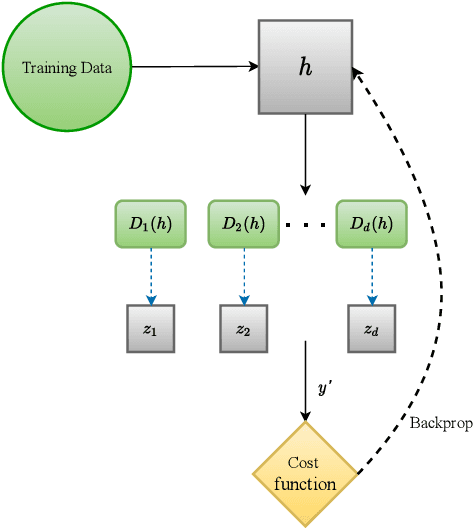

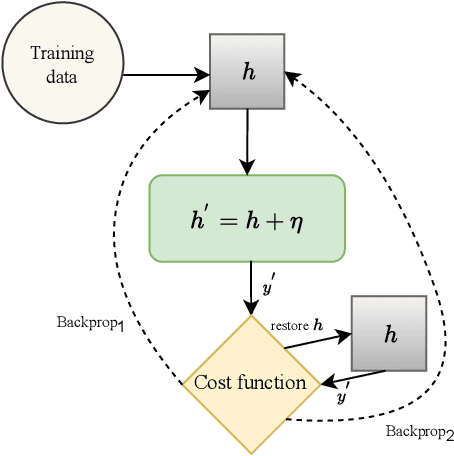
Early detection of COVID-19 is an ongoing area of research that can help with triage, monitoring and general health assessment of potential patients and may reduce operational strain on hospitals that cope with the coronavirus pandemic. Different machine learning techniques have been used in the literature to detect coronavirus using routine clinical data (blood tests, and vital signs). Data breaches and information leakage when using these models can bring reputational damage and cause legal issues for hospitals. In spite of this, protecting healthcare models against leakage of potentially sensitive information is an understudied research area. In this work, we examine two machine learning approaches, intended to predict a patient's COVID-19 status using routinely collected and readily available clinical data. We employ adversarial training to explore robust deep learning architectures that protect attributes related to demographic information about the patients. The two models we examine in this work are intended to preserve sensitive information against adversarial attacks and information leakage. In a series of experiments using datasets from the Oxford University Hospitals, Bedfordshire Hospitals NHS Foundation Trust, University Hospitals Birmingham NHS Foundation Trust, and Portsmouth Hospitals University NHS Trust we train and test two neural networks that predict PCR test results using information from basic laboratory blood tests, and vital signs performed on a patients' arrival to hospital. We assess the level of privacy each one of the models can provide and show the efficacy and robustness of our proposed architectures against a comparable baseline. One of our main contributions is that we specifically target the development of effective COVID-19 detection models with built-in mechanisms in order to selectively protect sensitive attributes against adversarial attacks.
LSTM-RASA Based Agri Farm Assistant for Farmers
Apr 07, 2022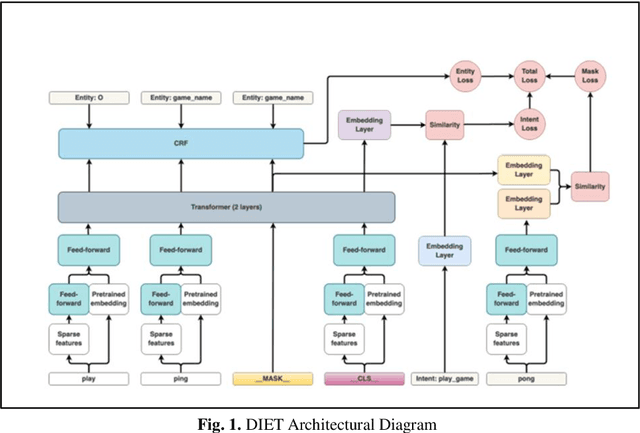

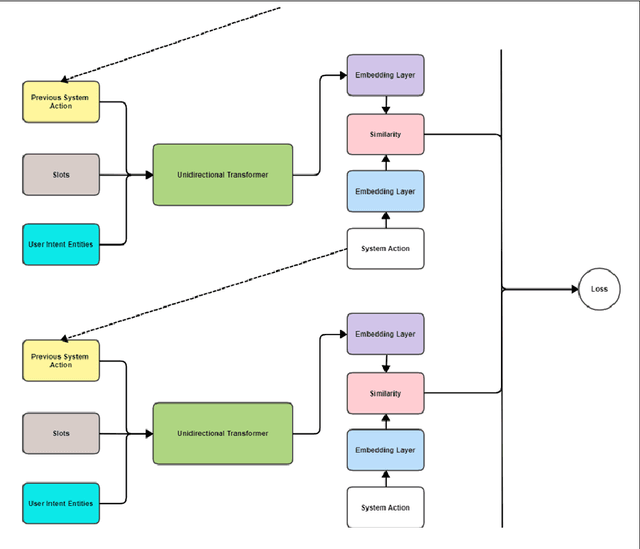
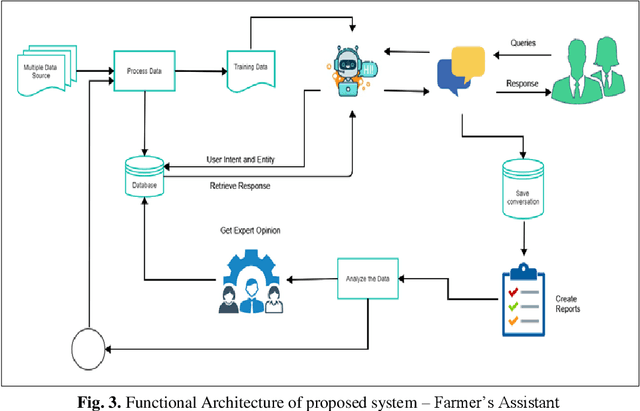
The application of Deep Learning and Natural Language based ChatBots are growing rapidly in recent years. They are used in many fields like customer support, reservation system and as personal assistant. The Enterprises are using such ChatBots to serve their customers in a better and efficient manner. Even after such technological advancement, the expert advice does not reach the farmers on timely manner. The farmers are still largely dependent on their peers knowledge in solving the problems they face in their field. These technologies have not been effectively used to give the required information to farmers on timely manner. This project aims to implement a closed domain ChatBot for the field of Agriculture Farmers Assistant. Farmers can have conversation with the Chatbot and get the expert advice in their field. Farmers Assistant is based on RASA Open Source Framework. The Chatbot identifies the intent and entity from user utterances and retrieve the remedy from the database and share it with the user. We tested the Bot with existing data and it showed promising results.
DOM-LM: Learning Generalizable Representations for HTML Documents
Jan 25, 2022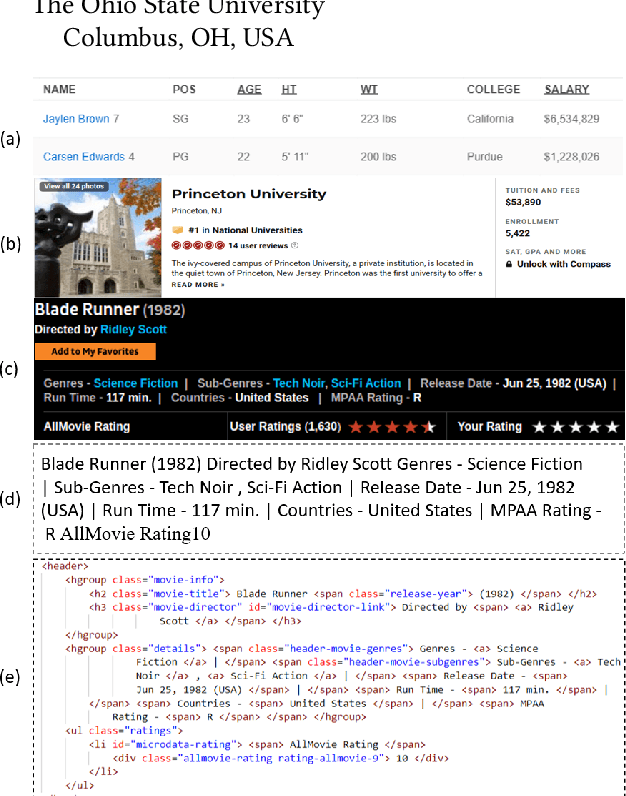

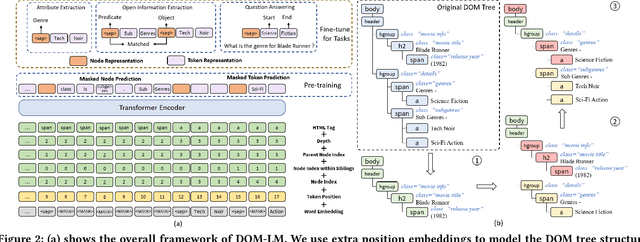
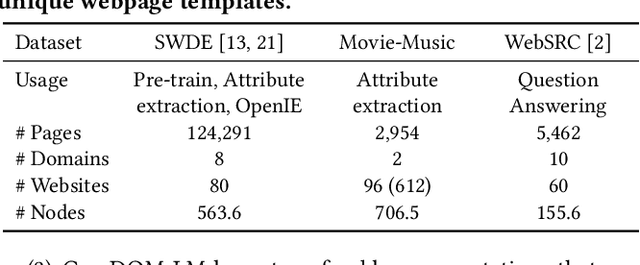
HTML documents are an important medium for disseminating information on the Web for human consumption. An HTML document presents information in multiple text formats including unstructured text, structured key-value pairs, and tables. Effective representation of these documents is essential for machine understanding to enable a wide range of applications, such as Question Answering, Web Search, and Personalization. Existing work has either represented these documents using visual features extracted by rendering them in a browser, which is typically computationally expensive, or has simply treated them as plain text documents, thereby failing to capture useful information presented in their HTML structure. We argue that the text and HTML structure together convey important semantics of the content and therefore warrant a special treatment for their representation learning. In this paper, we introduce a novel representation learning approach for web pages, dubbed DOM-LM, which addresses the limitations of existing approaches by encoding both text and DOM tree structure with a transformer-based encoder and learning generalizable representations for HTML documents via self-supervised pre-training. We evaluate DOM-LM on a variety of webpage understanding tasks, including Attribute Extraction, Open Information Extraction, and Question Answering. Our extensive experiments show that DOM-LM consistently outperforms all baselines designed for these tasks. In particular, DOM-LM demonstrates better generalization performance both in few-shot and zero-shot settings, making it attractive for making it suitable for real-world application settings with limited labeled data.
Boosting Self-Supervised Embeddings for Speech Enhancement
Apr 07, 2022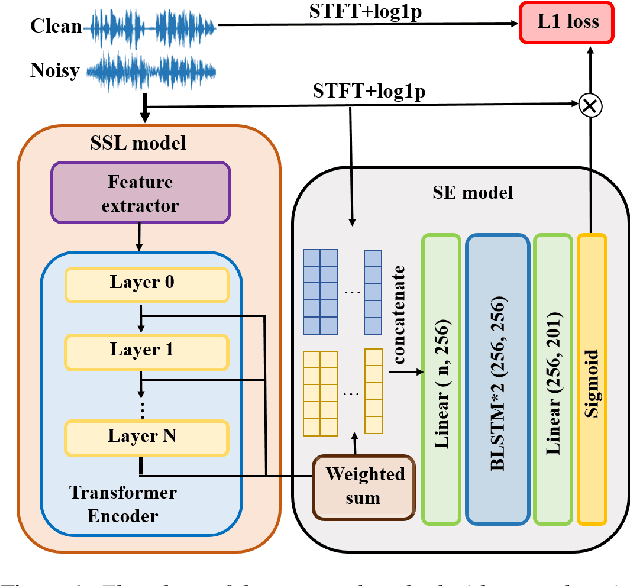
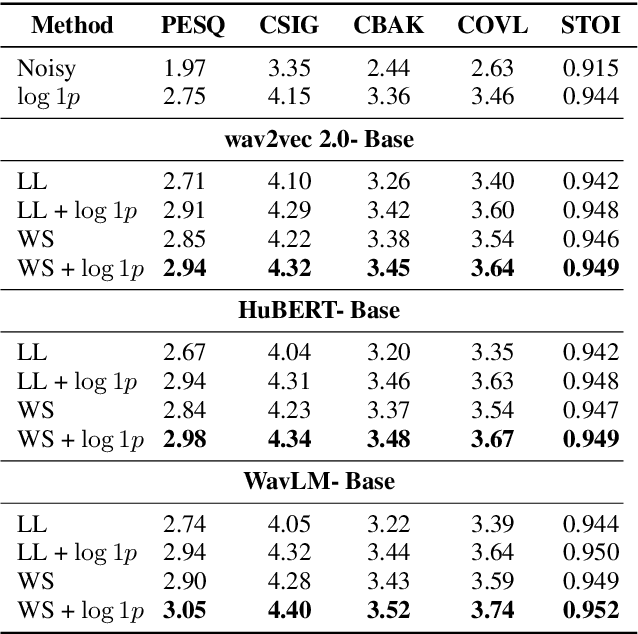
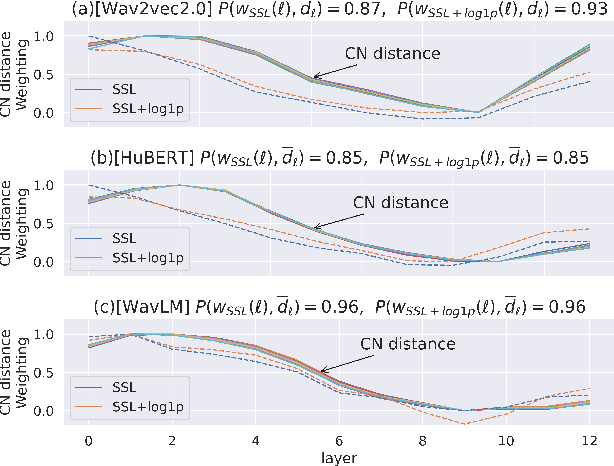
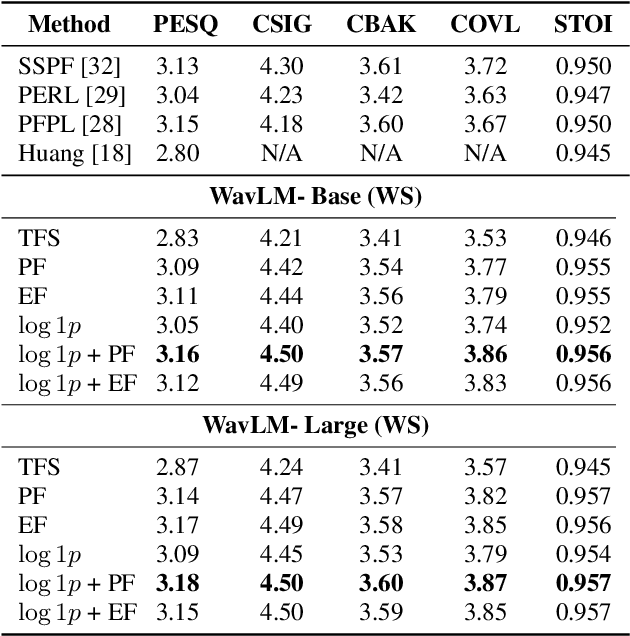
Self-supervised learning (SSL) representation for speech has achieved state-of-the-art (SOTA) performance on several downstream tasks. However, there remains room for improvement in speech enhancement (SE) tasks. In this study, we used a cross-domain feature to solve the problem that SSL embeddings may lack fine-grained information to regenerate speech signals. By integrating the SSL representation and spectrogram, the result can be significantly boosted. We further study the relationship between the noise robustness of SSL representation via clean-noisy distance (CN distance) and the layer importance for SE. Consequently, we found that SSL representations with lower noise robustness are more important. Furthermore, our experiments on the VCTK-DEMAND dataset demonstrated that fine-tuning an SSL representation with an SE model can outperform the SOTA SSL-based SE methods in PESQ, CSIG and COVL without invoking complicated network architectures. In later experiments, the CN distance in SSL embeddings was observed to increase after fine-tuning. These results verify our expectations and may help design SE-related SSL training in the future.
Efficient Federated Learning on Knowledge Graphs via Privacy-preserving Relation Embedding Aggregation
Apr 11, 2022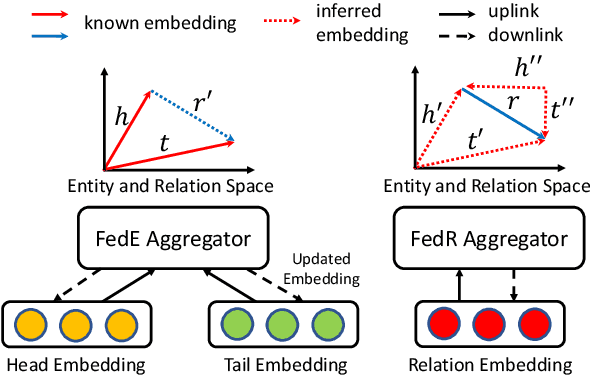
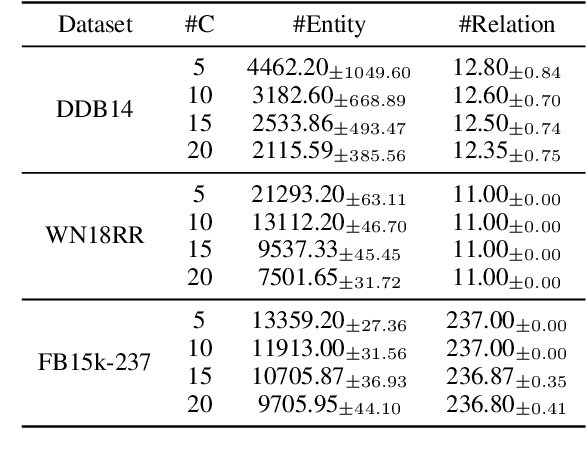
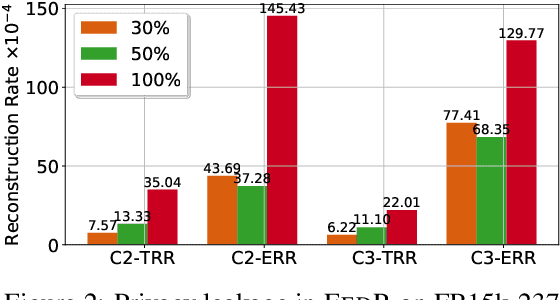
Federated Learning (FL) on knowledge graphs (KGs) has yet to be as well studied as other domains, such as computer vision and natural language processing. A recent study FedE first proposes an FL framework that shares entity embeddings of KGs across all clients. However, compared with model sharing in vanilla FL, entity embedding sharing from FedE would incur severe privacy leakage. Specifically, the known entity embedding can be used to infer whether a specific relation between two entities exists in a private client. In this paper, we first develop a novel attack that aims to recover the original data based on embedding information, which is further used to evaluate the vulnerabilities of FedE. Furthermore, we propose a Federated learning paradigm with privacy-preserving Relation embedding aggregation (FedR) to tackle the privacy issue in FedE. Compared to entity embedding sharing, relation embedding sharing policy can significantly reduce the communication cost due to its smaller size of queries. We conduct extensive experiments to evaluate FedR with five different embedding learning models and three benchmark KG datasets. Compared to FedE, FedR achieves similar utility and significant (nearly 2X) improvements in both privacy and efficiency on link prediction task.
Contextualize Me -- The Case for Context in Reinforcement Learning
Feb 09, 2022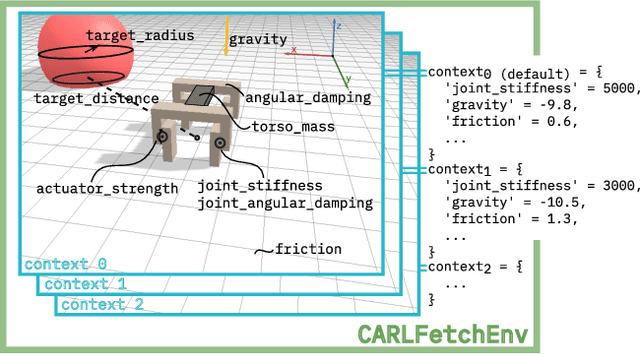
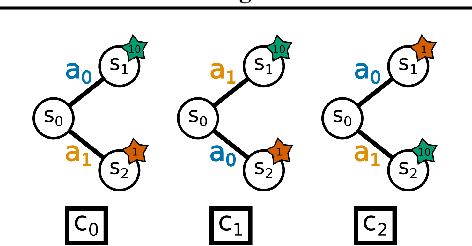
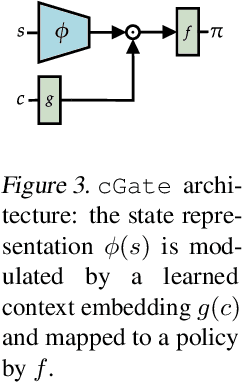
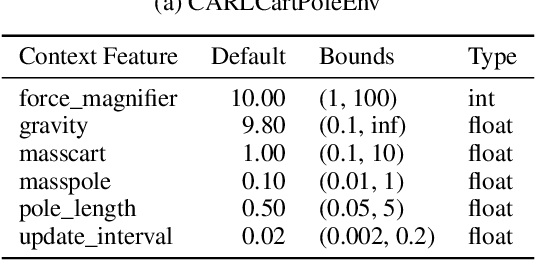
While Reinforcement Learning (RL) has made great strides towards solving increasingly complicated problems, many algorithms are still brittle to even slight changes in environments. Contextual Reinforcement Learning (cRL) provides a theoretical framework to model such changes in a principled manner, thereby enabling flexible, precise and interpretable task specification and generation. Thus, cRL is an important formalization for studying generalization in RL. In this work, we reason about solving cRL in theory and practice. We show that theoretically optimal behavior in contextual Markov Decision Processes requires explicit context information. In addition, we empirically explore context-based task generation, utilizing context information in training and propose cGate, our state-modulating policy architecture. To this end, we introduce the first benchmark library designed for generalization based on cRL extensions of popular benchmarks, CARL. In short: Context matters!
GIRAFFE HD: A High-Resolution 3D-aware Generative Model
Mar 28, 2022
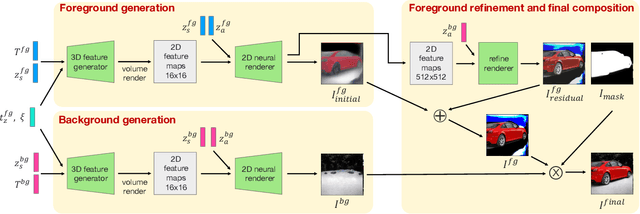

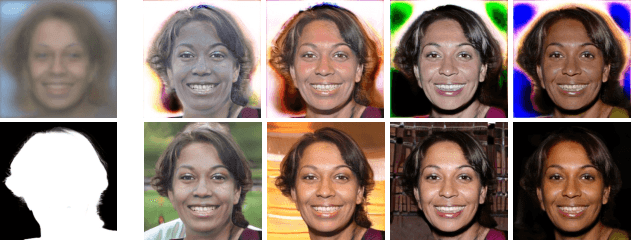
3D-aware generative models have shown that the introduction of 3D information can lead to more controllable image generation. In particular, the current state-of-the-art model GIRAFFE can control each object's rotation, translation, scale, and scene camera pose without corresponding supervision. However, GIRAFFE only operates well when the image resolution is low. We propose GIRAFFE HD, a high-resolution 3D-aware generative model that inherits all of GIRAFFE's controllable features while generating high-quality, high-resolution images ($512^2$ resolution and above). The key idea is to leverage a style-based neural renderer, and to independently generate the foreground and background to force their disentanglement while imposing consistency constraints to stitch them together to composite a coherent final image. We demonstrate state-of-the-art 3D controllable high-resolution image generation on multiple natural image datasets.