 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhotonic Quantum-Enhanced Knowledge Distillation
Mar 16, 2026Photonic quantum processors naturally produce intrinsically stochastic measurement outcomes, offering a hardware-native source of structured randomness that can be exploited during machine-learning training. Here we introduce Photonic Quantum-Enhanced Knowledge Distillation (PQKD), a hybrid quantum photonic--classical framework in which a programmable photonic circuit generates a compact conditioning signal that constrains and guides a parameter-efficient student network during distillation from a high-capacity teacher. PQKD replaces fully trainable convolutional kernels with dictionary convolutions: each layer learns only a small set of shared spatial basis filters, while sample-dependent channel-mixing weights are derived from shot-limited photonic features and mapped through a fixed linear transform. Training alternates between standard gradient-based optimisation of the student and sampling-robust, gradient-free updates of photonic parameters, avoiding differentiation through photonic hardware. Across MNIST, Fashion-MNIST and CIFAR-10, PQKD traces a controllable compression--accuracy frontier, remaining close to teacher performance on simpler benchmarks under aggressive convolutional compression. Performance degrades predictably with finite sampling, consistent with shot-noise scaling, and exponential moving-average feature smoothing suppresses high-frequency shot-noise fluctuations, extending the practical operating regime at moderate shot budgets.
Hybrid Quantum Temporal Convolutional Networks
Feb 27, 2026Quantum machine learning models for sequential data face scalability challenges with complex multivariate signals. We introduce the Hybrid Quantum Temporal Convolutional Network (HQTCN), which combines classical temporal windowing with a quantum convolutional neural network core. By applying a shared quantum circuit across temporal windows, HQTCN captures long-range dependencies while achieving significant parameter reduction. Evaluated on synthetic NARMA sequences and high-dimensional EEG time-series, HQTCN performs competitively with classical baselines on univariate data and outperforms all baselines on multivariate tasks. The model demonstrates particular strength under data-limited conditions, maintaining high performance with substantially fewer parameters than conventional approaches. These results establish HQTCN as a parameter-efficient approach for multivariate time-series analysis.
Quantum Super-resolution by Adaptive Non-local Observables
Jan 20, 2026Super-resolution (SR) seeks to reconstruct high-resolution (HR) data from low-resolution (LR) observations. Classical deep learning methods have advanced SR substantially, but require increasingly deeper networks, large datasets, and heavy computation to capture fine-grained correlations. In this work, we present the \emph{first study} to investigate quantum circuits for SR. We propose a framework based on Variational Quantum Circuits (VQCs) with \emph{Adaptive Non-Local Observable} (ANO) measurements. Unlike conventional VQCs with fixed Pauli readouts, ANO introduces trainable multi-qubit Hermitian observables, allowing the measurement process to adapt during training. This design leverages the high-dimensional Hilbert space of quantum systems and the representational structure provided by entanglement and superposition. Experiments demonstrate that ANO-VQCs achieve up to five-fold higher resolution with a relatively small model size, suggesting a promising new direction at the intersection of quantum machine learning and super-resolution.
Addressing the Current Challenges of Quantum Machine Learning through Multi-Chip Ensembles
May 13, 2025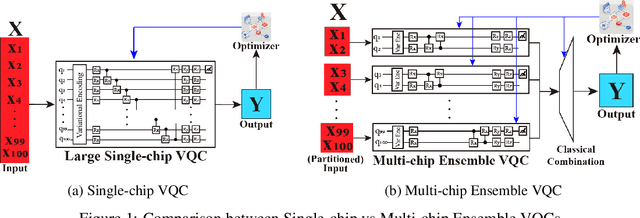

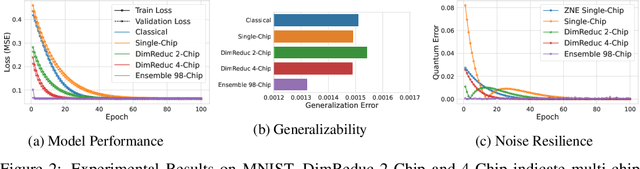

Quantum Machine Learning (QML) holds significant promise for solving computational challenges across diverse domains. However, its practical deployment is constrained by the limitations of noisy intermediate-scale quantum (NISQ) devices, including noise, limited scalability, and trainability issues in variational quantum circuits (VQCs). We introduce the multi-chip ensemble VQC framework, which partitions high-dimensional computations across smaller quantum chips to enhance scalability, trainability, and noise resilience. We show that this approach mitigates barren plateaus, reduces quantum error bias and variance, and maintains robust generalization through controlled entanglement. Designed to align with current and emerging quantum hardware, the framework demonstrates strong potential for enabling scalable QML on near-term devices, as validated by experiments on standard benchmark datasets (MNIST, FashionMNIST, CIFAR-10) and real world dataset (PhysioNet EEG).
Adaptive Non-local Observable on Quantum Neural Networks
Apr 18, 2025Conventional Variational Quantum Circuits (VQCs) for Quantum Machine Learning typically rely on a fixed Hermitian observable, often built from Pauli operators. Inspired by the Heisenberg picture, we propose an adaptive non-local measurement framework that substantially increases the model complexity of the quantum circuits. Our introduction of dynamical Hermitian observables with evolving parameters shows that optimizing VQC rotations corresponds to tracing a trajectory in the observable space. This viewpoint reveals that standard VQCs are merely a special case of the Heisenberg representation. Furthermore, we show that properly incorporating variational rotations with non-local observables enhances qubit interaction and information mixture, admitting flexible circuit designs. Two non-local measurement schemes are introduced, and numerical simulations on classification tasks confirm that our approach outperforms conventional VQCs, yielding a more powerful and resource-efficient approach as a Quantum Neural Network.
Linguistic Knowledge Transfer Learning for Speech Enhancement
Mar 10, 2025Linguistic knowledge plays a crucial role in spoken language comprehension. It provides essential semantic and syntactic context for speech perception in noisy environments. However, most speech enhancement (SE) methods predominantly rely on acoustic features to learn the mapping relationship between noisy and clean speech, with limited exploration of linguistic integration. While text-informed SE approaches have been investigated, they often require explicit speech-text alignment or externally provided textual data, constraining their practicality in real-world scenarios. Additionally, using text as input poses challenges in aligning linguistic and acoustic representations due to their inherent differences. In this study, we propose the Cross-Modality Knowledge Transfer (CMKT) learning framework, which leverages pre-trained large language models (LLMs) to infuse linguistic knowledge into SE models without requiring text input or LLMs during inference. Furthermore, we introduce a misalignment strategy to improve knowledge transfer. This strategy applies controlled temporal shifts, encouraging the model to learn more robust representations. Experimental evaluations demonstrate that CMKT consistently outperforms baseline models across various SE architectures and LLM embeddings, highlighting its adaptability to different configurations. Additionally, results on Mandarin and English datasets confirm its effectiveness across diverse linguistic conditions, further validating its robustness. Moreover, CMKT remains effective even in scenarios without textual data, underscoring its practicality for real-world applications. By bridging the gap between linguistic and acoustic modalities, CMKT offers a scalable and innovative solution for integrating linguistic knowledge into SE models, leading to substantial improvements in both intelligibility and enhancement performance.
Learning to Measure Quantum Neural Networks
Jan 10, 2025



The rapid progress in quantum computing (QC) and machine learning (ML) has attracted growing attention, prompting extensive research into quantum machine learning (QML) algorithms to solve diverse and complex problems. Designing high-performance QML models demands expert-level proficiency, which remains a significant obstacle to the broader adoption of QML. A few major hurdles include crafting effective data encoding techniques and parameterized quantum circuits, both of which are crucial to the performance of QML models. Additionally, the measurement phase is frequently overlooked-most current QML models rely on pre-defined measurement protocols that often fail to account for the specific problem being addressed. We introduce a novel approach that makes the observable of the quantum system-specifically, the Hermitian matrix-learnable. Our method features an end-to-end differentiable learning framework, where the parameterized observable is trained alongside the ordinary quantum circuit parameters simultaneously. Using numerical simulations, we show that the proposed method can identify observables for variational quantum circuits that lead to improved outcomes, such as higher classification accuracy, thereby boosting the overall performance of QML models.
Transfer Learning Analysis of Variational Quantum Circuits
Jan 02, 2025


This work analyzes transfer learning of the Variational Quantum Circuit (VQC). Our framework begins with a pretrained VQC configured in one domain and calculates the transition of 1-parameter unitary subgroups required for a new domain. A formalism is established to investigate the adaptability and capability of a VQC under the analysis of loss bounds. Our theory observes knowledge transfer in VQCs and provides a heuristic interpretation for the mechanism. An analytical fine-tuning method is derived to attain the optimal transition for adaptations of similar domains.
Quantum Gradient Class Activation Map for Model Interpretability
Aug 12, 2024



Quantum machine learning (QML) has recently made significant advancements in various topics. Despite the successes, the safety and interpretability of QML applications have not been thoroughly investigated. This work proposes using Variational Quantum Circuits (VQCs) for activation mapping to enhance model transparency, introducing the Quantum Gradient Class Activation Map (QGrad-CAM). This hybrid quantum-classical computing framework leverages both quantum and classical strengths and gives access to the derivation of an explicit formula of feature map importance. Experimental results demonstrate significant, fine-grained, class-discriminative visual explanations generated across both image and speech datasets.
Quantum Privacy Aggregation of Teacher Ensembles (QPATE) for Privacy-preserving Quantum Machine Learning
Jan 15, 2024



The utility of machine learning has rapidly expanded in the last two decades and presents an ethical challenge. Papernot et. al. developed a technique, known as Private Aggregation of Teacher Ensembles (PATE) to enable federated learning in which multiple teacher models are trained on disjoint datasets. This study is the first to apply PATE to an ensemble of quantum neural networks (QNN) to pave a new way of ensuring privacy in quantum machine learning (QML) models.