 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Third VoicePrivacy Challenge: Preserving Emotional Expressiveness and Linguistic Content in Voice Anonymization
Jan 17, 2026We present results and analyses from the third VoicePrivacy Challenge held in 2024, which focuses on advancing voice anonymization technologies. The task was to develop a voice anonymization system for speech data that conceals a speaker's voice identity while preserving linguistic content and emotional state. We provide a systematic overview of the challenge framework, including detailed descriptions of the anonymization task and datasets used for both system development and evaluation. We outline the attack model and objective evaluation metrics for assessing privacy protection (concealing speaker voice identity) and utility (content and emotional state preservation). We describe six baseline anonymization systems and summarize the innovative approaches developed by challenge participants. Finally, we provide key insights and observations to guide the design of future VoicePrivacy challenges and identify promising directions for voice anonymization research.
Analysis of Speech Temporal Dynamics in the Context of Speaker Verification and Voice Anonymization
Dec 22, 2024



In this paper, we investigate the impact of speech temporal dynamics in application to automatic speaker verification and speaker voice anonymization tasks. We propose several metrics to perform automatic speaker verification based only on phoneme durations. Experimental results demonstrate that phoneme durations leak some speaker information and can reveal speaker identity from both original and anonymized speech. Thus, this work emphasizes the importance of taking into account the speaker's speech rate and, more importantly, the speaker's phonetic duration characteristics, as well as the need to modify them in order to develop anonymization systems with strong privacy protection capacity.
The First VoicePrivacy Attacker Challenge Evaluation Plan
Oct 09, 2024



The First VoicePrivacy Attacker Challenge is a new kind of challenge organized as part of the VoicePrivacy initiative and supported by ICASSP 2025 as the SP Grand Challenge It focuses on developing attacker systems against voice anonymization, which will be evaluated against a set of anonymization systems submitted to the VoicePrivacy 2024 Challenge. Training, development, and evaluation datasets are provided along with a baseline attacker system. Participants shall develop their attacker systems in the form of automatic speaker verification systems and submit their scores on the development and evaluation data to the organizers. To do so, they can use any additional training data and models, provided that they are openly available and declared before the specified deadline. The metric for evaluation is equal error rate (EER). Results will be presented at the ICASSP 2025 special session to which 5 selected top-ranked participants will be invited to submit and present their challenge systems.
Adapting General Disentanglement-Based Speaker Anonymization for Enhanced Emotion Preservation
Aug 12, 2024



A general disentanglement-based speaker anonymization system typically separates speech into content, speaker, and prosody features using individual encoders. This paper explores how to adapt such a system when a new speech attribute, for example, emotion, needs to be preserved to a greater extent. While existing systems are good at anonymizing speaker embeddings, they are not designed to preserve emotion. Two strategies for this are examined. First, we show that integrating emotion embeddings from a pre-trained emotion encoder can help preserve emotional cues, even though this approach slightly compromises privacy protection. Alternatively, we propose an emotion compensation strategy as a post-processing step applied to anonymized speaker embeddings. This conceals the original speaker's identity and reintroduces the emotional traits lost during speaker embedding anonymization. Specifically, we model the emotion attribute using support vector machines to learn separate boundaries for each emotion. During inference, the original speaker embedding is processed in two ways: one, by an emotion indicator to predict emotion and select the emotion-matched SVM accurately; and two, by a speaker anonymizer to conceal speaker characteristics. The anonymized speaker embedding is then modified along the corresponding SVM boundary towards an enhanced emotional direction to save the emotional cues. The proposed strategies are also expected to be useful for adapting a general disentanglement-based speaker anonymization system to preserve other target paralinguistic attributes, with potential for a range of downstream tasks.
The VoicePrivacy 2022 Challenge: Progress and Perspectives in Voice Anonymisation
Jul 16, 2024



The VoicePrivacy Challenge promotes the development of voice anonymisation solutions for speech technology. In this paper we present a systematic overview and analysis of the second edition held in 2022. We describe the voice anonymisation task and datasets used for system development and evaluation, present the different attack models used for evaluation, and the associated objective and subjective metrics. We describe three anonymisation baselines, provide a summary description of the anonymisation systems developed by challenge participants, and report objective and subjective evaluation results for all. In addition, we describe post-evaluation analyses and a summary of related work reported in the open literature. Results show that solutions based on voice conversion better preserve utility, that an alternative which combines automatic speech recognition with synthesis achieves greater privacy, and that a privacy-utility trade-off remains inherent to current anonymisation solutions. Finally, we present our ideas and priorities for future VoicePrivacy Challenge editions.
The VoicePrivacy 2024 Challenge Evaluation Plan
Apr 03, 2024



The task of the challenge is to develop a voice anonymization system for speech data which conceals the speaker's voice identity while protecting linguistic content and emotional states. The organizers provide development and evaluation datasets and evaluation scripts, as well as baseline anonymization systems and a list of training resources formed on the basis of the participants' requests. Participants apply their developed anonymization systems, run evaluation scripts and submit evaluation results and anonymized speech data to the organizers. Results will be presented at a workshop held in conjunction with Interspeech 2024 to which all participants are invited to present their challenge systems and to submit additional workshop papers.
LeBenchmark 2.0: a Standardized, Replicable and Enhanced Framework for Self-supervised Representations of French Speech
Sep 11, 2023Self-supervised learning (SSL) is at the origin of unprecedented improvements in many different domains including computer vision and natural language processing. Speech processing drastically benefitted from SSL as most of the current domain-related tasks are now being approached with pre-trained models. This work introduces LeBenchmark 2.0 an open-source framework for assessing and building SSL-equipped French speech technologies. It includes documented, large-scale and heterogeneous corpora with up to 14,000 hours of heterogeneous speech, ten pre-trained SSL wav2vec 2.0 models containing from 26 million to one billion learnable parameters shared with the community, and an evaluation protocol made of six downstream tasks to complement existing benchmarks. LeBenchmark 2.0 also presents unique perspectives on pre-trained SSL models for speech with the investigation of frozen versus fine-tuned downstream models, task-agnostic versus task-specific pre-trained models as well as a discussion on the carbon footprint of large-scale model training.
Language-independent speaker anonymization using orthogonal Householder neural network
May 30, 2023



Speaker anonymization aims to conceal a speaker's identity while preserving content information in speech. Current mainstream neural-network speaker anonymization systems disentangle speech into prosody-related, content, and speaker representations. The speaker representation is then anonymized by a selection-based speaker anonymizer that uses a mean vector over a set of randomly selected speaker vectors from an external pool of English speakers. However, the resulting anonymized vectors are subject to severe privacy leakage against powerful attackers, reduction in speaker diversity, and language mismatch problems for unseen language speaker anonymization. To generate diverse, language-neutral speaker vectors, this paper proposes an anonymizer based on an orthogonal Householder neural network (OHNN). Specifically, the OHNN acts like a rotation to transform the original speaker vectors into anonymized speaker vectors, which are constrained to follow the distribution over the original speaker vector space. A basic classification loss is introduced to ensure that anonymized speaker vectors from different speakers have unique speaker identities. To further protect speaker identities, an improved classification loss and similarity loss are used to push original-anonymized sample pairs away from each other. Experiments on VoicePrivacy Challenge datasets in English and the AISHELL-3 dataset in Mandarin demonstrate the proposed anonymizer's effectiveness.
Federated Learning for ASR based on Wav2vec 2.0
Feb 20, 2023



This paper presents a study on the use of federated learning to train an ASR model based on a wav2vec 2.0 model pre-trained by self supervision. Carried out on the well-known TED-LIUM 3 dataset, our experiments show that such a model can obtain, with no use of a language model, a word error rate of 10.92% on the official TED-LIUM 3 test set, without sharing any data from the different users. We also analyse the ASR performance for speakers depending to their participation to the federated learning. Since federated learning was first introduced for privacy purposes, we also measure its ability to protect speaker identity. To do that, we exploit an approach to analyze information contained in exchanged models based on a neural network footprint on an indicator dataset. This analysis is made layer-wise and shows which layers in an exchanged wav2vec 2.0 based model bring the speaker identity information.
The VoicePrivacy 2020 Challenge Evaluation Plan
May 14, 2022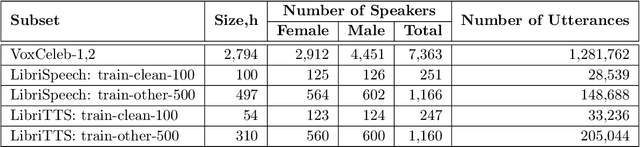
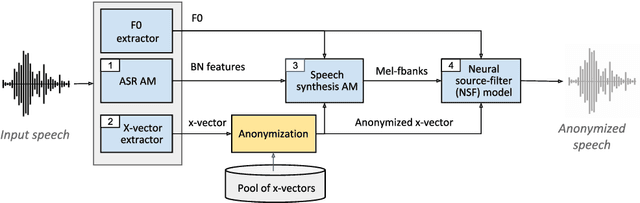
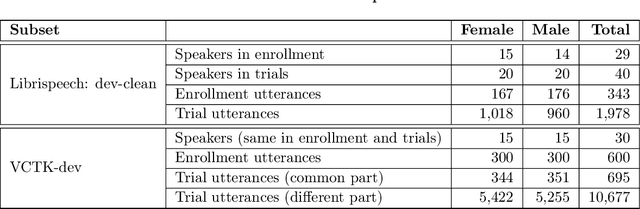
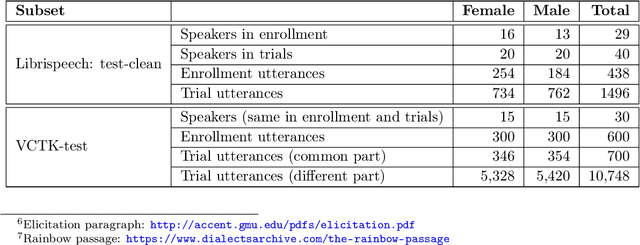
The VoicePrivacy Challenge aims to promote the development of privacy preservation tools for speech technology by gathering a new community to define the tasks of interest and the evaluation methodology, and benchmarking solutions through a series of challenges. In this document, we formulate the voice anonymization task selected for the VoicePrivacy 2020 Challenge and describe the datasets used for system development and evaluation. We also present the attack models and the associated objective and subjective evaluation metrics. We introduce two anonymization baselines and report objective evaluation results.