 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquiBim: Learning Symmetry-Equivariant Policy for Bimanual Manipulation
Mar 09, 2026Robotic imitation learning has achieved impressive success in learning complex manipulation behaviors from demonstrations. However, many existing robot learning methods do not explicitly account for the physical symmetries of robotic systems, often resulting in asymmetric or inconsistent behaviors under symmetric observations. This limitation is particularly pronounced in dual-arm manipulation, where bilateral symmetry is inherent to both the robot morphology and the structure of many tasks. In this paper, we introduce EquiBim, a symmetry-equivariant policy learning framework for bimanual manipulation that enforces bilateral equivariance between observations and actions during training. Our approach formulates physical symmetry as a group action on both observation and action spaces, and imposes an equivariance constraint on policy predictions under symmetric transformations. The framework is model-agnostic and can be seamlessly integrated into a wide range of imitation learning pipelines with diverse observation modalities and action representations, including point cloud-based and image-based policies, as well as both end-effector-space and joint-space parameterizations. We evaluate EquiBim on RoboTwin, a dual-arm robotic platform with symmetric kinematics, and evaluate it across diverse observation and action configurations in simulation. We further validate the approach on a real-world dual-arm system. Across both simulation and physical experiments, our method consistently improves performance and robustness under distribution shifts. These results suggest that explicitly enforcing physical symmetry provides a simple yet effective inductive bias for bimanual robot learning.
When Are RL Hyperparameters Benign? A Study in Offline Goal-Conditioned RL
Feb 05, 2026Hyperparameter sensitivity in Deep Reinforcement Learning (RL) is often accepted as unavoidable. However, it remains unclear whether it is intrinsic to the RL problem or exacerbated by specific training mechanisms. We investigate this question in offline goal-conditioned RL, where data distributions are fixed, and non-stationarity can be explicitly controlled via scheduled shifts in data quality. Additionally, we study varying data qualities under both stationary and non-stationary regimes, and cover two representative algorithms: HIQL (bootstrapped TD-learning) and QRL (quasimetric representation learning). Overall, we observe substantially greater robustness to changes in hyperparameter configurations than commonly reported for online RL, even under controlled non-stationarity. Once modest expert data is present ($\approx$ 20\%), QRL maintains broad, stable near-optimal regions, while HIQL exhibits sharp optima that drift significantly across training phases. To explain this divergence, we introduce an inter-goal gradient alignment diagnostic. We find that bootstrapped objectives exhibit stronger destructive gradient interference, which coincides directly with hyperparameter sensitivity. These results suggest that high sensitivity to changes in hyperparameter configurations during training is not inevitable in RL, but is amplified by the dynamics of bootstrapping, offering a pathway toward more robust algorithmic objective design.
Moments Matter:Stabilizing Policy Optimization using Return Distributions
Jan 05, 2026Deep Reinforcement Learning (RL) agents often learn policies that achieve the same episodic return yet behave very differently, due to a combination of environmental (random transitions, initial conditions, reward noise) and algorithmic (minibatch selection, exploration noise) factors. In continuous control tasks, even small parameter shifts can produce unstable gaits, complicating both algorithm comparison and real-world transfer. Previous work has shown that such instability arises when policy updates traverse noisy neighborhoods and that the spread of post-update return distribution $R(θ)$, obtained by repeatedly sampling minibatches, updating $θ$, and measuring final returns, is a useful indicator of this noise. Although explicitly constraining the policy to maintain a narrow $R(θ)$ can improve stability, directly estimating $R(θ)$ is computationally expensive in high-dimensional settings. We propose an alternative that takes advantage of environmental stochasticity to mitigate update-induced variability. Specifically, we model state-action return distribution through a distributional critic and then bias the advantage function of PPO using higher-order moments (skewness and kurtosis) of this distribution. By penalizing extreme tail behaviors, our method discourages policies from entering parameter regimes prone to instability. We hypothesize that in environments where post-update critic values align poorly with post-update returns, standard PPO struggles to produce a narrow $R(θ)$. In such cases, our moment-based correction narrows $R(θ)$, improving stability by up to 75% in Walker2D, while preserving comparable evaluation returns.
ARLBench: Flexible and Efficient Benchmarking for Hyperparameter Optimization in Reinforcement Learning
Sep 27, 2024



Hyperparameters are a critical factor in reliably training well-performing reinforcement learning (RL) agents. Unfortunately, developing and evaluating automated approaches for tuning such hyperparameters is both costly and time-consuming. As a result, such approaches are often only evaluated on a single domain or algorithm, making comparisons difficult and limiting insights into their generalizability. We propose ARLBench, a benchmark for hyperparameter optimization (HPO) in RL that allows comparisons of diverse HPO approaches while being highly efficient in evaluation. To enable research into HPO in RL, even in settings with low compute resources, we select a representative subset of HPO tasks spanning a variety of algorithm and environment combinations. This selection allows for generating a performance profile of an automated RL (AutoRL) method using only a fraction of the compute previously necessary, enabling a broader range of researchers to work on HPO in RL. With the extensive and large-scale dataset on hyperparameter landscapes that our selection is based on, ARLBench is an efficient, flexible, and future-oriented foundation for research on AutoRL. Both the benchmark and the dataset are available at https://github.com/automl/arlbench.
* Accepted at the 17th European Workshop on Reinforcement Learning
Instance Selection for Dynamic Algorithm Configuration with Reinforcement Learning: Improving Generalization
Jul 18, 2024Dynamic Algorithm Configuration (DAC) addresses the challenge of dynamically setting hyperparameters of an algorithm for a diverse set of instances rather than focusing solely on individual tasks. Agents trained with Deep Reinforcement Learning (RL) offer a pathway to solve such settings. However, the limited generalization performance of these agents has significantly hindered the application in DAC. Our hypothesis is that a potential bias in the training instances limits generalization capabilities. We take a step towards mitigating this by selecting a representative subset of training instances to overcome overrepresentation and then retraining the agent on this subset to improve its generalization performance. For constructing the meta-features for the subset selection, we particularly account for the dynamic nature of the RL agent by computing time series features on trajectories of actions and rewards generated by the agent's interaction with the environment. Through empirical evaluations on the Sigmoid and CMA-ES benchmarks from the standard benchmark library for DAC, called DACBench, we discuss the potentials of our selection technique compared to training on the entire instance set. Our results highlight the efficacy of instance selection in refining DAC policies for diverse instance spaces.
Structure in Reinforcement Learning: A Survey and Open Problems
Jun 28, 2023Reinforcement Learning (RL), bolstered by the expressive capabilities of Deep Neural Networks (DNNs) for function approximation, has demonstrated considerable success in numerous applications. However, its practicality in addressing a wide range of real-world scenarios, characterized by diverse and unpredictable dynamics, noisy signals, and large state and action spaces, remains limited. This limitation stems from issues such as poor data efficiency, limited generalization capabilities, a lack of safety guarantees, and the absence of interpretability, among other factors. To overcome these challenges and improve performance across these crucial metrics, one promising avenue is to incorporate additional structural information about the problem into the RL learning process. Various sub-fields of RL have proposed methods for incorporating such inductive biases. We amalgamate these diverse methodologies under a unified framework, shedding light on the role of structure in the learning problem, and classify these methods into distinct patterns of incorporating structure. By leveraging this comprehensive framework, we provide valuable insights into the challenges associated with structured RL and lay the groundwork for a design pattern perspective on RL research. This novel perspective paves the way for future advancements and aids in the development of more effective and efficient RL algorithms that can potentially handle real-world scenarios better.
AutoML in the Age of Large Language Models: Current Challenges, Future Opportunities and Risks
Jun 13, 2023


The fields of both Natural Language Processing (NLP) and Automated Machine Learning (AutoML) have achieved remarkable results over the past years. In NLP, especially Large Language Models (LLMs) have experienced a rapid series of breakthroughs very recently. We envision that the two fields can radically push the boundaries of each other through tight integration. To showcase this vision, we explore the potential of a symbiotic relationship between AutoML and LLMs, shedding light on how they can benefit each other. In particular, we investigate both the opportunities to enhance AutoML approaches with LLMs from different perspectives and the challenges of leveraging AutoML to further improve LLMs. To this end, we survey existing work, and we critically assess risks. We strongly believe that the integration of the two fields has the potential to disrupt both fields, NLP and AutoML. By highlighting conceivable synergies, but also risks, we aim to foster further exploration at the intersection of AutoML and LLMs.
Learning Activation Functions for Sparse Neural Networks
May 18, 2023



Sparse Neural Networks (SNNs) can potentially demonstrate similar performance to their dense counterparts while saving significant energy and memory at inference. However, the accuracy drop incurred by SNNs, especially at high pruning ratios, can be an issue in critical deployment conditions. While recent works mitigate this issue through sophisticated pruning techniques, we shift our focus to an overlooked factor: hyperparameters and activation functions. Our analyses have shown that the accuracy drop can additionally be attributed to (i) Using ReLU as the default choice for activation functions unanimously, and (ii) Fine-tuning SNNs with the same hyperparameters as dense counterparts. Thus, we focus on learning a novel way to tune activation functions for sparse networks and combining these with a separate hyperparameter optimization (HPO) regime for sparse networks. By conducting experiments on popular DNN models (LeNet-5, VGG-16, ResNet-18, and EfficientNet-B0) trained on MNIST, CIFAR-10, and ImageNet-16 datasets, we show that the novel combination of these two approaches, dubbed Sparse Activation Function Search, short: SAFS, results in up to 15.53%, 8.88%, and 6.33% absolute improvement in the accuracy for LeNet-5, VGG-16, and ResNet-18 over the default training protocols, especially at high pruning ratios. Our code can be found at https://github.com/automl/SAFS
AutoRL Hyperparameter Landscapes
Apr 11, 2023Although Reinforcement Learning (RL) has shown to be capable of producing impressive results, its use is limited by the impact of its hyperparameters on performance. This often makes it difficult to achieve good results in practice. Automated RL (AutoRL) addresses this difficulty, yet little is known about the dynamics of the hyperparameter landscapes that hyperparameter optimization (HPO) methods traverse in search of optimal configurations. In view of existing AutoRL approaches dynamically adjusting hyperparameter configurations, we propose an approach to build and analyze these hyperparameter landscapes not just for one point in time but at multiple points in time throughout training. Addressing an important open question on the legitimacy of such dynamic AutoRL approaches, we provide thorough empirical evidence that the hyperparameter landscapes strongly vary over time across representative algorithms from RL literature (DQN and SAC) in different kinds of environments (Cartpole and Hopper). This supports the theory that hyperparameters should be dynamically adjusted during training and shows the potential for more insights on AutoRL problems that can be gained through landscape analyses.
Towards Meta-learned Algorithm Selection using Implicit Fidelity Information
Jun 07, 2022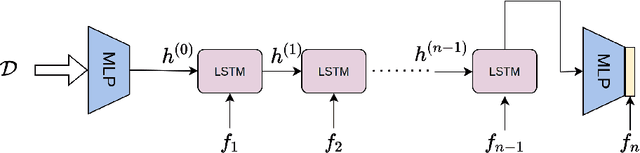
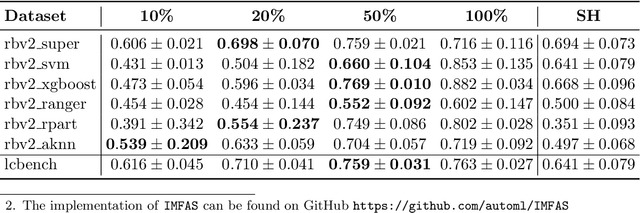
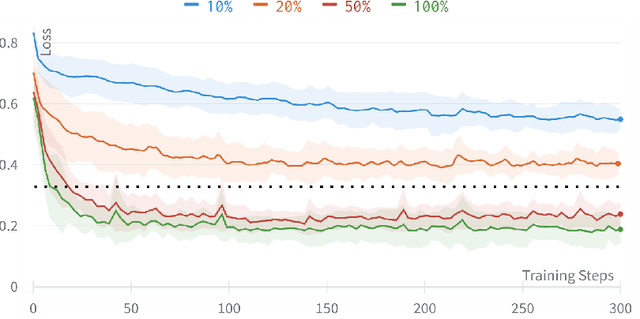

Automatically selecting the best performing algorithm for a given dataset or ranking multiple of them by their expected performance supports users in developing new machine learning applications. Most approaches for this problem rely on dataset meta-features and landmarking performances to capture the salient topology of the datasets and those topologies that the algorithms attend to. Landmarking usually exploits cheap algorithms not necessarily in the pool of candidate algorithms to get inexpensive approximations of the topology. While somewhat indicative, handcrafted dataset meta-features and landmarks are likely insufficient descriptors, strongly depending on the alignment of the geometries the landmarks and candidates search for. We propose IMFAS, a method to exploit multi-fidelity landmarking information directly from the candidate algorithms in the form of non-parametrically non-myopic meta-learned learning curves via LSTM networks in a few-shot setting during testing. Using this mechanism, IMFAS jointly learns the topology of of the datasets and the inductive biases of algorithms without expensively training them to convergence. IMFAS produces informative landmarks, easily enriched by arbitrary meta-features at a low computational cost, capable of producing the desired ranking using cheaper fidelities. We additionally show that it is able to beat Successive Halving with at most half the fidelity sequence during test time